ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Двухфакторный дисперсионный анализ без повторений
Microsoft Excel располагает функцией Anova: Двухфакторный дисперсионный анализ без повторений (Two-Factor Without Replication), которая используется для выявления факта влияния контролируемых факторов А и В на результативный признак на основе выборочных данных, причем каждому уровню факторов А и В соответствует только одна выборка. Для вызова этой функции необходимо на панели меню выбрать команду Сервис –Анализ данных. На экране раскроется окно Анализ данных, в котором следует выбрать значение Двухфакторный дисперсионный анализ без повторений и щелкнуть на кнопке ОК. В результате на экране раскроется диалоговое окно, показанное на рис. 1.
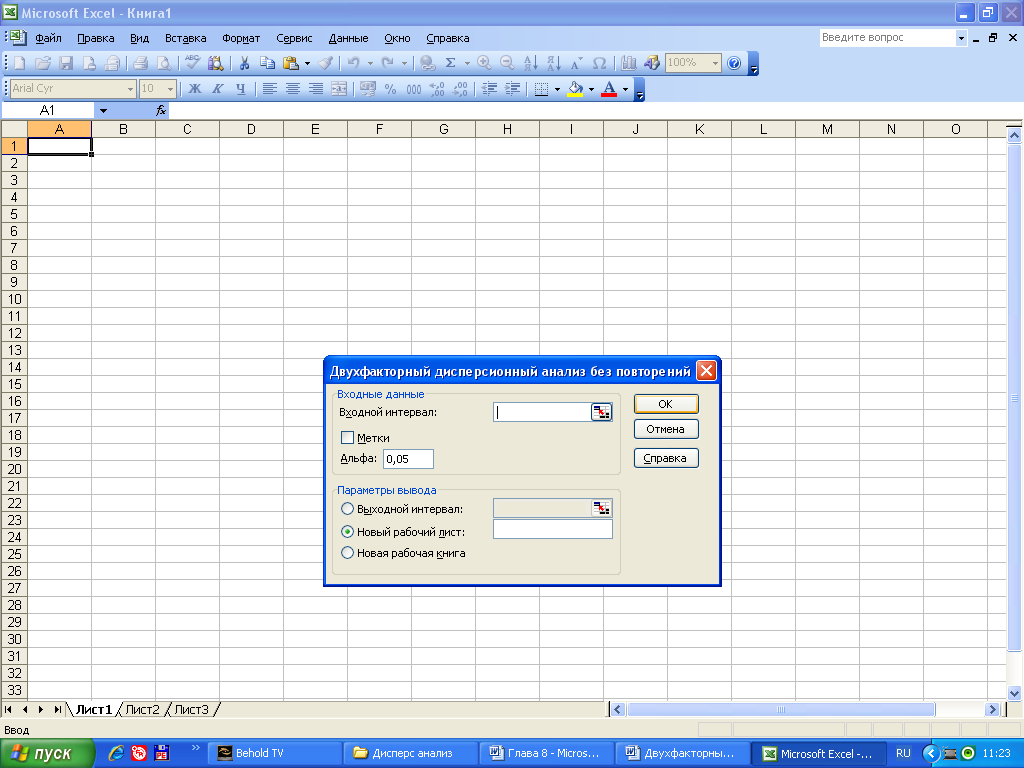
Рис. 1. Диалоговое окно Двухфакторного дисперсионного анализа без повторений
В диалоговом окне задаются следующие параметры.
1. В поле Входной интервал (Input Range) вводится ссылка на диапазон ячеек, содержащий анализируемые данные.
2. Флажок опции Метки (Labels) устанавливается в том случае, если первая строка во входном диапазоне содержит заголовки столбцов. Если заголовки отсутствуют, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. В поле Aльфа вводится принятый уровень значимости α, соответствующий вероятности возникновения ошибки первого рода.
4. Переключатель в группе Параметры вывода (Output options) может быть установлен в одно из трех положений: Output Range (Выходной диапазон), New Worksheet Ply (Новый рабочий лист) или New Workbook (Новая рабочая книга).
Рассмотрим использование функции Двухфакторныйдисперсионный анализ без повторений (Anova: Two-Factor Without Replication) на следующем примере.
Пример 2. На рис. 2 представлены данные об урожайности (ц/га) четырех сортов пшеницы (четыре уровня фактора А), достигнутой при использовании пяти типов удобрений (пять уровней фактора В).
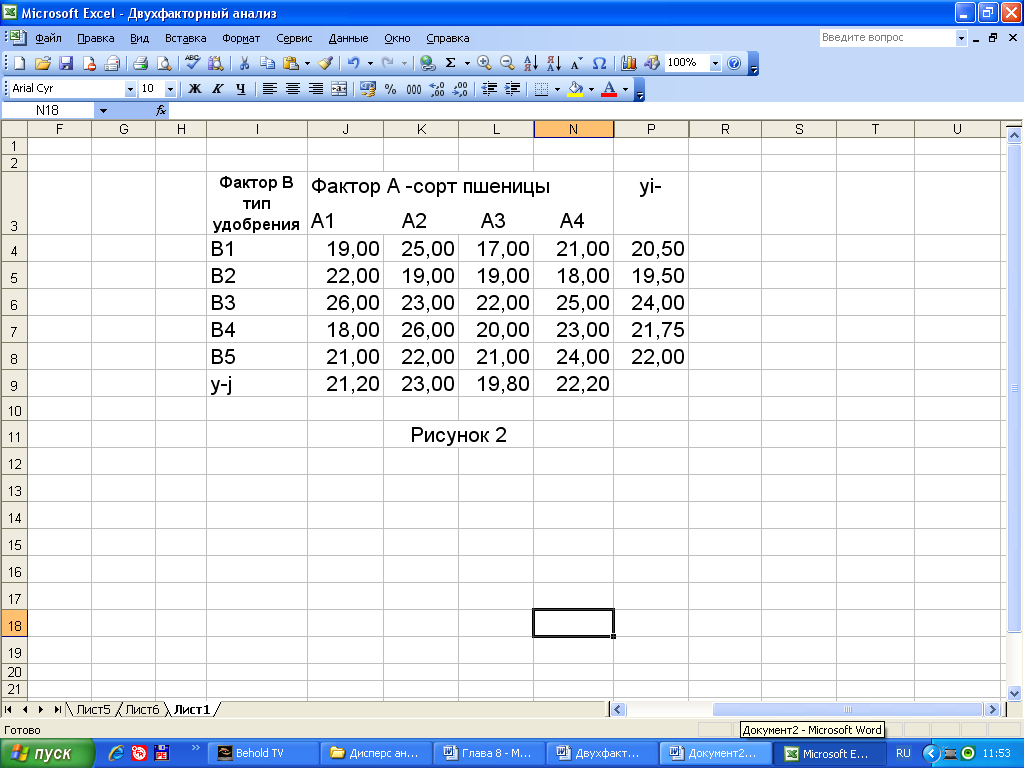
Данные получены на 20 участках одинакового размера и аналогичного почвенного покрова. Необходимо определить, влияет ли сорт и тип удобрения на урожайность пшеницы.
Решение
Результаты двухфакторного дисперсионного анализа с помощью функции Двухфакторный дисперсионный анализ без повторений представлены на рис. 3.

Рис. 3. Результаты Двухфакторного дисперсионного анализа без повторений
Как видно по результатам, расчетное значение величины F-статистики для фактора А (тип удобрения) FА=l,67, а критическая область образуется правосторонним интервалом (3,49; +∞). Так как FА=l,67 не попадает в критическую область, гипотезу НА: a1 = a2 + ••• = ak принимаем, т.е. считаем, что в этом эксперименте тип удобрения не оказал влияния на урожайность.
Расчетное значение величины F-статистики для фактора В (сорт пшеницы) FВ =2,03, а критическая область образуется правосторонним интервалом (3,259;+∞).
Так как FВ =2,03 не попадает в критическую область, гипотезу НВ: b1 = b2 =... = bm также принимаем, т.е. считаем, что в данном эксперименте сорт пшеницы также не оказал влияния на урожайность.
Не нашли, что искали? Воспользуйтесь поиском: