ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
ИСТОЧНИКИ БАЗОВЫХ КОМПОНЕНТОВ ЭКОНОМЕТРИЧЕСКОЙ НАУКИ
ПО ВЫПОЛНЕНИЮ РАСЧЕТНЫХ РАБОТ
И ЗАДАНИЯ НА КОНТРОЛЬНУЮ РАБОТУ
ПО ДИСЦИПЛИНЕ «ЭКОНОМЕТРИЯ»
(Для студентов специальностей «Финансы», «Экономика предприятия»
всех форм обучения)
ДОНЕЦК 2008
УДК (075.8) 330.115
ББК65.053
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ ПО ВЫПОЛНЕНИЮ РАСЧЕТНО - ГРАФИЧЕСКИХ РАБОТ И ЗАДАНИЯ НА КОНТРОЛЬНУЮ РАБОТУ ПО ДИСЦИПЛИНЕ «ЭКОНОМЕТРИЯ». – Донецк, ДонТУ,2008. – 50с.
В Методических рекомендациях по дисциплине «Эконометрия» приведен необходимый для решения практических вопросов теоретический материал, решение типовых задач, реализованное на компьютере с помощью прикладных программ Excel, а также контрольные задания.
Методические рекомендации по дисциплине «Эконометрия» разработаны доцентом кафедры «финансы и банковское дело» Л.Д. Слепневой
1. ЭКОНОМЕТРИЯ И ЭКОНОМЕТРИЧЕСКОЕ МОДЕЛИРОВАНИЕ:
ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Эконометрия – экономико-математическая научная дисциплина, разрабатывающая и использующая методы, модели, позволяющие придавать конкретное количественное выражение общим (качественным) закономерностям экономической теории на базе экономической статистики с использованием математико-статистического инструментария.
Говоря об экономической теории в рамках эконометрии, исследователи интересуются не просто выявлением объективно существующих (на качественном уровне) экономических законов и связей между экономическими показателями, но и подходами к их формализации, включающими в себя методы спецификации соответствующих моделей с учетом проблемы их идентифицируемости. При рассмотрении экономической статистики как составной части эконометрии обычно имеют в виду тот аспект этой самостоятельной дисциплины, который непосредственно связан с информационным обеспечением анализируемой эконометрической модели. Под математико-статистическим инструментарием эконометрии подразумеваются отдельные разделы математической статистики: классическая и обобщенная линейные модели регрессионного анализа, анализ временных рядов, построение и анализ системы одновременных уравнений.
Из определения эконометрии следует, что ее происхождение и главное назначение – это экономические и социально-экономические приложения, а именно: модельное описание конкретных количественных взаимосвязей, существующих между анализируемыми показателями.
Следующая схема (рис. 1) позволит лучше разобраться в сущности рассматриваемого вопроса.
|

 |  | ||||
 |
ИСТОЧНИКИ БАЗОВЫХ КОМПОНЕНТОВ ЭКОНОМЕТРИЧЕСКОЙ НАУКИ
 |
Рис. 1. Эконометрия и место ее в ряду смежных дисциплин
Термин «Эконометрия» появился в 1930 году. 29 декабря 1930 года в Кливленде было основано Эконометрическое общество, которое определило себя как «международное общество для развития экономической теории в ее связи со статистикой и математикой».
Каждый изучающий экономику сталкивается с тем, что все экономические переменные связаны между собой. Формирующийся на рынке спрос на некоторый товар рассматривается как функция его цены; затраты на производство продукции предполагаются зависящими от объема ее производства; потребительские расходы могут быть функцией дохода и т.д. Все это примеры связей между двумя переменными, одна из которых (спрос на товар, производственные затраты, потребительские расходы) играют роль объясняемой переменной (или результирующего показателя, зависимой переменной), а другие интерпретируются как объясняющие переменные (или факторы-аргументы, независимые переменные).
Понятно, что кроме цены на величину спроса влияют и другие показатели: величина потребительского дохода, цены на конкурирующие и дополняющие товары и др. Производственные затраты зависят не только от количества производимого продукта, а и от цен на основные производственные ресурсы. Потребительские расходы можно определить как функцию дохода, ликвидных активов и предыдущего уровня потребления. Кроме того, имеют место ошибки измерения величины переменных. Поэтому в каждое такое соотношение приходится вводить несколько объясняющих переменных и случайную составляющую (или возмущение, остаток), которая отражает влияние на результирующий показатель всех неучтенных факторов и ошибок измерения.
Наличие случайной составляющей обусловливает стохастический характер зависимости, поскольку, переходя в своих наблюдениях спроса от одного временного или пространственного такта к другому, обнаруживают случайное варьирование величины спроса около некоторого уровня даже при сохранении значений всех объясняющих переменных неизменными.
Наиболее распространенной в эконометрических исследованиях формой представления стохастической зависимости является аддитивная линейная форма:
Yt = b0 + b1 X 1t + … + bp Xpt + et, (1)
где Yt - значение результирующей (зависимой, объясняемой) переменной, измеренное в t-м временном или пространственном такте,
X1t, X2t,…, Xpt - значения объясняющих (независимых) переменных, полученные в том же t-м измерении,
b0 , b1 , …, bp - некоторые параметры,
et - случайная составляющая (возмущение), характеризующая разницу между модельным[1] и эмпирическим значениями анализируемой результирующей переменной, зафиксированную в t-м измерении.
Модельное значение результирующей переменной равно:
 b0 + b1 X 1t + … + bp Xpt. (2)
b0 + b1 X 1t + … + bp Xpt. (2)
Тогда случайную составляющую можно интерпретировать как случайную ошибку прогноза Y по заданным значениям X1t, X2t,…, Xp t, причем, чтобы исключить систематическую ошибку в оценке Yt по 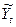 , обычно полагают, что среднее значение возмущения равно нулю. Очевидно, чем больше информации заключено в значениях объясняющих переменных относительно величины Y, тем надежнее будет прогноз и тем меньше будет ошибка прогноза e.
, обычно полагают, что среднее значение возмущения равно нулю. Очевидно, чем больше информации заключено в значениях объясняющих переменных относительно величины Y, тем надежнее будет прогноз и тем меньше будет ошибка прогноза e.
Все экономические модели имеют некоторые общие особенности. Во-первых, они основаны на предположении, что поведение экономических переменных определяется с помощью совместных и одновременных операций с некоторым числом экономических соотношений. Во-вторых, принимается гипотеза, в силу которой модель, допуская упрощение сложной действительности, тем не менее, улавливает главные характеристики изучаемого объекта. В-третьих, создатель модели полагает, что на основе достигнутого с ее помощью понимания реальной системы удастся предсказать ее будущее движение и, возможно, управлять им в целях улучшения экономического благосостояния.
Рассмотрим пример макромодели. Предположим, экономист-теоретик сформулировал следующие положения:
· потребление есть возрастающая функция от имеющегося в наличии дохода, но возрастающая медленнее, чем растет доход;
· объем инвестиций есть возрастающая функция национального дохода и убывающая функция характеристики государственного регулирования (например, нормы процента);
· национальный доход есть сумма потребительских, инвестиционных и государственных закупок товаров и услуг.
Первая задача – перевести эти положения на язык математики. И тут же возникает множество проблем: какие соотношения выбрать между переменными – линейные или нелинейные; если остановиться на нелинейных, то какими они должны быть – логарифмическими, полиномиальными или какими-то еще? Даже определив форму конкретного соотношения, мы оставляем нерешенной проблему выбора различных уровней запаздываний во времени: будут ли, например, инвестиции текущего периода реагировать только на национальный доход, произведенный в последнем периоде, или же на них скажется динамика нескольких предыдущих периодов? Обычный выход из этих трудностей состоит в использовании при первоначальном анализе наиболее простой из возможных форм этих соотношений. Тогда появляется возможность записать на основе указанных выше положений следующую линейную относительно анализируемых переменных и аддитивную относительно случайных составляющих модель:
Y1 t = a0 + a1 (Y3 t - X1t) + e1 t, (3)
Y2 t = b1Y3, t -1 + b2 X2 t + e2 t, (4)
Y3 t = Y1 t + Y2 t + X3 t, (5)
где априорные ограничения выражены неравенствами: 0 < a1 < 1; b1 > 0; b2 < 0.
Эти три соотношения вместе с ограничениями (3) – (5) образуют модель. В ней Y1t обозначает потребление, Y2t - инвестиции, Y3t - национальный доход, X1t – подоходный налог, X2t – норму процента как инструмент государственного регулирования, X3t – государственные закупки товаров и услуг, измеренные в «момент времени» t.
Присутствие в уравнениях (3) и (4) возмущений e1t и e2t обусловлено необходимостью учета влияния соответственно на Y1 t и Y2 t ряда неучтенных (не включенных в модель) факторов.
Полученная модель содержит два уравнения: (3) и (4), объясняющие поведение потребителей и инвесторов, и одно тождество (5). Она сформулирована для дискретных периодов времени и содержит запаздывание (лаг) в один период для отражения воздействия национального дохода на инвестиции.
В любой эконометрической модели в зависимости от конечных прикладных целей ее использования все переменные разделяются на:
· экзогенные, т.е. задаваемые как бы «извне», автономно, в определенной степени планируемые, управляемые;
· эндогенные, т.е. такие переменные, значения которых формируются в процессе и внутри функционирования анализируемой социально-экономической системы в существенной мере под воздействием экзогенных переменных и, конечно, во взаимодействии друг с другом; в эконометрической модели они являются предметом объяснения.
· предопределенные, т. е. выступающие в системе в роли факторов-аргументов, или объясняющих переменных. Множество предопределенных переменных формируется из всех экзогенных переменных (которые могут быть «привязаны» к прошлому, текущему или будущему моментам времени) и так называемых лаговых эндогенных переменных, т.е. таких эндогенных переменных, значения которых входят в уравнения анализируемой эконометрической системы измеренными в прошлые (по отношению к текущему) моменты времени, а следовательно, являются уже известными, заданными.
В нашем примере потребление (Y1t), инвестиции (Y2t ) и национальный доход (Y3t) в текущий момент времени t являются эндогенными переменными; подоходный налог (X1), норма процента как инструмент государственного регулирования (X2t) и государственные закупки товаров и услуг (X3t) – экзогенные переменные, которые вместе с национальным доходом в предшествующий момент времени (Y3, t-1) образуют множество предопределенных переменных.
При построении и анализе эконометрической модели следует различать ее структурную и приведенную формы. Структурнаяформа отражает непосредственно результат формирования уравнений связи между эндогенными и экзогенными переменными, опирающегося на их экономическую сущность. При этом левая часть любого уравнения структурной формы может содержать и эндогенные, и экзогенные переменные без какого-либо разделения их ролей, а правая часть – остаточную случайную компоненту. Такова система (3) – (5). Приведенная форма системы является результатом разрешения структурной формы относительно эндогенных переменных.
Отличительной особенностью эконометрической модели является то, что она, будучи представленной в виде набора математических соотношений, описывает функционирование конкретной экономической системы, а не системы вообще (именно экономики Украины или процесса «спрос – предложение» в данном конкретном месте и в данное время). Поэтому она обязательно «настраивается» на конкретных статистических данных.
В процессе эконометрического моделирования приходится решать следующие проблемы:
· спецификации модели,
· идентифицируемости,
· идентификации,
· верификации модели.
Проблема спецификации решается на начальной стадии моделирования и включает:
1) определение конечных целей моделирования (прогноз, имитация различных сценариев социально-экономического развития анализируемой системы, управление);
2) определение списка экзогенных и эндогенных переменных;
3) определение состава анализируемой системы уравнений и тождеств, их структуры и соответственно списка предопределенных переменных;
4) формулировка исходных предпосылок и априорных ограничений относительно:
· стохастической природы остатков (возмущений) (в классическом варианте моделей постулируется их взаимная некоррелированность, нулевые значения их средних величин, сохранение постоянным в процессе наблюдения значений их дисперсий – гомоскедастичность);
· числовых значений некоторых параметров.
Спецификация опирается на имеющиеся экономические теории, специальные знания
или на интуитивные представления исследователя об анализируемой экономической системе.
Проблема идентифицируемости – это проблема восстановления структурной формы модели (численного оценивания ее параметров) по найденным значениям коэффициентов приведенной формы.
В эконометрической теории приняты следующие определения, связанные с проблемой идентифицируемости.
1. Уравнение структурной формы эконометрической модели называется точно идентифицируемым, если все его коэффициенты однозначно восстанавливаются (определяются) по коэффициентам приведенной формы.
2. Эконометрическая модель называется точно идентифицируемой, если все уравнения ее структурной формы являются точно идентифицируемыми.
3. Уравнение структурной формы называется сверхидентифицируемым, если все его коэффициенты восстанавливаются по коэффициентам приведенной формы, причем некоторые из его коэффициентов могут принимать одновременно несколько числовых значений, соответствующих одной и той же приведенной форме.
4. Уравнение структурной формы называется неидентифицируемым, если хотя бы один из его коэффициентов не может быть восстановлен по коэффициентам приведенной формы. Соответственно модель называется неидентифицируемой, если хотя бы одно из уравнений ее структурной формы является неидентифицируемым.
Проблема идентифицируемости крайне важна с точки зрения решения проблемы идентификации эконометрической модели, т.е. проблемы выбора и реализации методов статистического оценивания ее параметров.
Проблема верификации модели, как и проблема идентификации, является специфичной, связанной с построением именно эконометрической модели. Собственно построение эконометрической модели завершается ее идентификацией, т.е. статистическим оцениванием параметров. После этого, однако, возникают вопросы:
a) насколько удачно решены проблемы спецификации, идентифицируемости и идентификации модели, т.е. можно ли рассчитывать на то, что использование построенной модели в целях прогноза эндогенных переменных и имитационных расчетов, определяющих варианты социально-экономического развития анализируемой системы, даст результаты, достаточно адекватные реальной действительности?
b) какова точность (абсолютная, относительная) прогнозных и имитационных расчетов, основанных на построенной модели?
Получение ответов на эти вопросы с помощью математико-статистических методов и составляет содержание проблемы верификации.
Среди методов математико-статистического инструментария эконометрии центральное место занимает регрессионный анализ.
Под регрессией понимают одностороннюю стохастическую зависимость одной случайно переменной от другой или нескольких случайных переменных. В этом смысле регрессия используется для исследования и оценки зависимостей между экономическими явлениями, порожденными, как правило, совокупным действием комплекса причин. Рассматривая причинно-следственные связи, мы хотим из смешанного сочетания причин выявить действие существенных, освободившись от элементов случайности и действия второстепенных причин. Математическое решение сводится к получению функции регрессии. С помощью методов математической статистики можно исследовать зависимость между такими экономическими показателями как, например, национальный доход, капитальные вложения и трудовые ресурсы. Явления, подлежащие исследованию, должны быть количественно варьирующими величинами. Тогда они считаются переменными в статистическом смысле.
Прежде, чем применять математико-статистический аппарат, явление следует проанализировать с содержательной точки зрения и решить, какую переменную рассматривать как зависимую (следствие), или переменную, подлежащую объяснению с помощью функции регрессии, и какие переменные в ходе анализа считать объясняющими (причины), независимыми, или предсказывающими. Причины и следствия должны быть объяснены экономической теорией.
С помощью функции регрессии
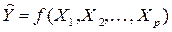 (6)
(6)
количественно оценивается усредненная зависимость между исследуемыми переменными. Понятие регрессии всегда связано с определенными средними условиями. Наблюдая за интересующей его зависимостью при сложном взаимодействии факторов-причин и случайностей, исследователь, с помощью регрессии, отвечает на вопрос: какова была бы зависимость между следствием и выделенными существенными причинами, если бы прочие факторы не изменялись и тем самым не осложняли и не затушевывали основную зависимость?
Случайная переменная e,
 (7)
(7)
характеризует отклонение переменной Y от усредненной величины  , вычисленной по функции регрессии (6). Случайная переменная e называется возмущающей или, кратко, возмущением. Она включает влияние неучтенных факторов-переменных, случайных помех и ошибок наблюдения. Ее трудно исследовать, поскольку она меняется для каждого наблюдения Y. Если бы мы изучали зависимость национального дохода от капитальных вложений, то случайная возмущающая переменная содержала бы в себе влияние на национальный доход таких факторов, как численность работников в сфере производства, производительность труда, использование основных фондов и т. д., а также различные случайные помехи.
, вычисленной по функции регрессии (6). Случайная переменная e называется возмущающей или, кратко, возмущением. Она включает влияние неучтенных факторов-переменных, случайных помех и ошибок наблюдения. Ее трудно исследовать, поскольку она меняется для каждого наблюдения Y. Если бы мы изучали зависимость национального дохода от капитальных вложений, то случайная возмущающая переменная содержала бы в себе влияние на национальный доход таких факторов, как численность работников в сфере производства, производительность труда, использование основных фондов и т. д., а также различные случайные помехи.
Таким образом, переменную Y можно представить в виде:
 , (8)
, (8)
или, с учетом (6)
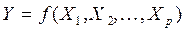 + e.
+ e.
Этот вид записи позволяет интерпретировать возмущение e как учитывающую неправильную спецификацию функции регрессии, т.е. неправильный выбор формы уравнения, описывающего зависимость.
Благодаря введению случайной переменной e переменная Y также становится случайной, поскольку при заданных значениях объясняющих переменных  переменной Y нельзя приписать или поставить в соответствие только одно определенное значение. Если, например, мы изучаем зависимость себестоимости от объема продукции, то, задаваясь значением объема продукции, можно указать диапазон, в котором могут находиться соответствующие значения себестоимости.
переменной Y нельзя приписать или поставить в соответствие только одно определенное значение. Если, например, мы изучаем зависимость себестоимости от объема продукции, то, задаваясь значением объема продукции, можно указать диапазон, в котором могут находиться соответствующие значения себестоимости.
Статистические зависимости могут быть обнаружены лишь при многократном повторении наблюдений. Поэтому в дальнейшем мы будем исходить из того, что для (р + 1) переменных имеется n совместных наблюдений (например, n предприятий). Результаты наблюдений можно представить в виде следующей таблицы:
Таблица 1
| № наблюдения | Переменные | |||||
| Y | Х1 | ... | Хj | ... | Хр | |
| Y1 | Х11 | ... | Х1j | ... | Х1p | |
| Y2 | Х21 | ... | Х2j | ... | Х2p | |
| ... | ... | ... | ... | ... | ... | ... |
| i | Yi | Хi1 | ... | Хij | ... | Хip |
| ... | ... | ... | ... | ... | ... | |
| n | Yn | Хn1 | ... | Хnj | ... | Хnp |
Каждый столбец таблицы (1) представляет ряд наблюдений над одной переменной, например. Введенных в действие основных фондов или объемы производства на n (например. 52) предприятиях. Индекс столбцов j = 1,2,…,p указывает соответствующую объясняющую переменную, а индекс строки i = 1,2,…,n – порядковый номер совместных наблюдений над (р + 1) переменными. Таким образом, Xij – результат i-го наблюдения над j-й переменной. Значения Yi и Xij являются эмпирическими (опытными) данными, полученными в результате наблюдений над переменными Y и Xj. Желательно погрешности измерения, а также ошибки наблюдателя-регистратора свести к минимуму, так как зависимость между исследуемыми переменными может искажаться в силу ошибок наблюдений над значениями переменных.
В то время как исследователь располагает значениями зависимой и объясняющих переменных в результате совместных наблюдений над этими переменными, значения возмущающей переменной e непосредственно получить нельзя, поскольку она представляет собой конгломерат многих, трудно учитываемых и случайных влияний. По этой причине e называется также латентной (скрытой) переменной. Лишь после количественной оценки зависимости в виде функции регрессии можно получить значения возмущающей переменной e по (7). Вычисленные оценки значений возмущения e далее обозначаются е и называются остатками.
Направление причинной связи между переменными определяется через предварительное обоснование и включается в модель как гипотеза. Регрессионный анализ проверяет статистическую состоятельность модели при данной гипотезе.
Пример 1. Предположим, выдвинута гипотеза о том, что уровень фондового индекса FTSE 100 линейно зависим от уровня фондового индекса S&P 500, т.е., когда растет S&P 500, растет и FTSE 100, а когда S&P 500 падает, падает и FTSE 100. Можно проверить эту гипотезу, используя простую линейную регрессию с включением только двух переменных.
Альтернативной гипотезой может быть то, что индекс FTSE 100 находится под влиянием не одного фактора, а нескольких. Например, на текущий уровень FTSE 100 могут влиять индекс S&P 500, уровень рынка облигаций Великобритании и обменный курс $/₤. Эта гипотеза может быть проверена с помощью множественной регрессии.
Основной задачей регрессионного анализа, кроме того, является установление формы связи, т.е. подбор такой функции, которая как можно лучше характеризовала бы осредненное массовое течение явления. Избранная функция должна отражать экономическую закономерность. Поэтому на этапе, предшествующем построению регрессии необходим обстоятельный качественный экономический анализ исследуемой зависимости. На основе этого анализа формулируется гипотеза о типе функции, правдоподобие которой затем статистически проверяется по эмпирическим данным.
Не нашли, что искали? Воспользуйтесь поиском: