ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Компонентный анализ лексического значения
5.1. Общая идея компонентного анализа значения
В разделе 4 мы говорили о таком аспекте словесного знака, как его отношение к другим знакам в системе языка, ввели понятие семантической корреляции и рассмотрели основные виды таких корреляций. Теперь мы рассмотрим, как через установление корреляций между словами можно придти к представлению значений слов в виде комбинации элементарных компонентов смысла, т. е. к компонентному анализу лексических значений.
Мы говорили о том, что отношения, в которые вступают между тобой слова в языке, обладают разной степенью системности. Если понимать системность организации некоторого множества объектов как иозможность построить объекты этого множества с помощью правил, количество которых меньше, чем количество самих объектов, то можно считать, что системными являются те корреляции, которые обеспечи-иают системность организации множества слов. Из этого следует, что системные корреляции не должны быть уникальны, они должны характеризовать не одну пару противопоставленных слов, а целый ряд таких пар. На основе системных отношений между словами строятся пропорциональные равенства, которые можно назвать семантическими пропорциями. I!римеры семантических пропорций:
(1) бояться: пугать = купить: продать =... = выходить замуж: жениться;
(2) кислород: газ = клубника:ягода =... — лингвист:ученый;
(3) писать: почерк = ходить: походка =... = вести себя: поведение;
(4) помнить: вспомнить: напомнить = быть мертвым: умереть: убить =... = бодрствовать: проснуться: разбудить;
(5) мужчина:женщина:ребенок = бык:корова: теленок =... —петух: курица: цыпленок.
Подобные пропорции выражают тот факт, что, с точки зрения знамения, помнить, вспомнить и напомнить — с одной стороны, и бодрство-чать, проснуться и разбудить — с другой, имеют нечто общее; более того, напомнить и разбудить имеют такие общие черты, которыми не обладают ни вспомнить и проснуться, ни помнить и бодрствовать, и, наоборот, нспомнить и проснуться имеют такие общие черты, которыми не обладают
No
Раздел П. Лексическая семантика
Глава 5. Компонентный анализ лексического значения 111
помнить и бодрствовать. То общее, чем обладают эти различные группы слов, можно приписать совпадению элементов, из которых состоят значения этих слов. Таким образом производится следующий логический шаг: от констатации сходств и различий между значениями противопоставляемых друг другу слов, от выделения на этой основе общих для них и различительных семантических признаков осуществляется переход к предположению о том, что значение этих слов состоит из элементарных смысловых единиц — семантических компонентов, сем, соответствующих выделенным при сопоставлении признакам. Предположение о том, что значение каждой единицы языка (в том числе слова) состоит из набора семантических компонентов — это одна из основных гипотез, на которых базируется метод компонентного анализа. В лексической семантике метод компонентного анализа принадлежит к числу основных методов описания лексического значения.
Для уяснения главных идей компонентного анализа полезно сопоставить семантические пропорции с числовыми, как это делает Дж. Лай-онз в своем учебнике «Введение в теоретическую лингвистику» [Лай-онз 1977: 496-497]. Если нам дана числовая пропорция:
а: b = с: d,
то мы можем разложить эту пропорцию на множители. Эти множители для сопоставимости с семантическими пропорциями можно назвать компонентами. Отметим кстати, что в некоторых вариантах компонентного анализа вместо термина семантический компонент используется термин семантический множитель в полном соответствии с арифметической терминологией. Каждое из четырех выражений в этой пропорции далее можно представить как произведение пары множителей, или компонентов. Например, из пропорции:
2: 6 = 10: 30
можно извлечь компоненты-множители 1, 2, 3 и 10. Тогда эту пропорцию можно переписать следующим образом:
(2 х 1): (2 х 3) = (10 х 1): (10 х 3).
Посмотрим на полученные множители-компоненты. Три из них — 1, 2 и 3 — простые числа, которые далее не разложимы, т. е. не предста-вимы в виде произведения других простых чисел, кроме 1 и самого себя. Такие компоненты являются конечными, или минимальными компонентами. Множитель 10 не является простым числом, и следовательно, он может быть представлен в виде произведения конечных компонентов — простых чисел. Для того, чтобы разложить 10 на простые числа — сомно жители — мы должны привлечь к рассмотрению еще одну пропорцию,, например, такую:
1:2 = 5:10.
Это позволит нам извлечь минимальные компоненты числа 10 — 2 и 5. Тогда исходную пропорцию мы сможем представить в виде:
(2 х 1): (2 х 3) = ((2 х 5) х 1): ((2 х 5) х 3).
Здесь уже каждое из четырех исходных выражений представлено в виде произведения своих минимальных, или конечных, компонентов.
Рассуждая аналогичным образом, мы можем проанализировать и семантические пропорции. Из пропорции вспомнить: напомнить = проснуться: разбудить мы можем извлечь три компонента смысла: 'кау-шровать' («'заставить'), 'вспомнить' и 'проснуться'. На этой стадии анализа 'вспомнить' и 'проснуться' выступают как единые компоненты. Если далее мы привлечем к рассмотрению пропорцию помнить: вспомнить = бодрствовать: проснуться, мы сможем извлечь новые компоненты — 'начать', 'помнить' и 'бодрствовать'. Отметим, что ни один из этих компонентов априори не считается конечным компонентом, или минимальным элементом смысла или семантическим примитивом, так как нполне вероятно, что, привлекая другие слова языка для сравнения с данными и составляя пропорции, мы сможем разложить эти компоненты на «более простые», или «более мелкие». Например, на основе пропорции иметь: сохранять = знать: помнить можно представить помнить как произведение компонентов продолжать и знать. Поскольку в принципе для анализа доступны все релевантные пропорции, сторонники компонентного анализа выдвигают второе основное предположение: весь словарный состав языка может быть описан с помощью ограниченного и сравнительно небольшого числа минимальных смысловых элементов.
Для обозначения минимальной единицы значения используется целый ряд терминов: сема, семантический дифференциальный признак, семантический множитель, семантический примитив, смысловой атом, фигура содержания и т. п. Наиболее удобным нам представляется термин «сема».
К настоящему моменту метод компонентного анализа имеет уже более чем 30-летнюю традицию. Начиная с 60-х гг. его применяют в лексической семантике с различными целями, основной из которых является описание лексических значений. Этот метод хорошо зарекомендовал себя и при решении прикладных задач, таких как информационный поиск, автоматическое понимание текста. Метод компонентного анализа реально существует во множестве вариантов, которые могут существенно отличаться друг от друга по целому ряду параметров. Однако суть метода остается неизменной. Говоря на самом общем уровне, компонентный анализ лексических значений — это последовательность процедур, которая, будучи примененной к словам языка, ставит в соответствие каждому слову определенным образом организованный набор семантических компонентов.
В диссертации Т. С. Зевахиной «Компонентный анализ как метод выявления семантической структуры слова» [Зевахина 1979] разработана система параметров (всего их 134), на основе которых можно оха-
112 Раздел II. Лексическая семантика
Глава 5. Компонентный анализ лексического значения 113
растеризовать конкретные разновидности компонентного анализа. Одна группа параметров характеризует процедуры анализа, другая — сам компонентный метаязык. Рассмотрим наиболее распространенные варианты компонентного анализа в хронологическом порядке.
5.2. Ранние варианты компонентного анализа значения
Та разновидность компонентного анализа, которую мы привели для иллюстрации, позаимствовав ее у Лайонза, использует для выявления компонентного представления процедуру построения семантических пропорций. Исходным объектом анализа являются вырванные из контекста слова, взятые в их определенном узуальном значении. Компонентное представление значения слова имеет вид произведения семантических компонентов, порядок следования которых никак не оговаривается.
В учебном пособии Ю. Найды «Компонентный анализ значения», отрывок из которой переведен и опубликован в сборнике «Новое в зарубежной лингвистике» [Найда 1983: 61—74], рассматривается вариант компонентного анализа, основанный на применении процедуры, которую он называет процедурой вертикально-горизонтального анализа значений. Она предусматривает сопоставление значений слов в двух измерениях:
— в вертикальном, когда сравниваются значения, стоящие на разных уровнях иерархии родо-видовых отношений, т. е. значения гиперонимов со значениями гипонимов;
— в горизонтальном, когда сравниваются значения одного и того же уровня иерархии, независимо от того, находятся они в отношении несовместимости, дополнительности или антонимии.
Процедура вертикально-горизонтального анализа иллюстрируется на примере слова magazine 'журнал'. Процедура разбивается на 5 этапов.
Этап 1: определить ту единицу смысла, которая включает значение слова magazine, т. е., иначе говоря, найти ближайший гипероним для этого слова. Его значение и будет искомым компонентом смысла. Для большинства носителей английского языка это будет значение слова periodical 'периодическое издание'.
Этап 2: найти те единицы, которые могут считаться включенными в значение слова, т. е. посмотреть, каково значение его гипонимов. Для некоторых носителей языка это будут гипонимы sites, pulps, comics и т. д. Но для многих носителей американского варианта английского языка на этом уровне будут располагаться прежде всего названия конкретных журналов.
Этап 3: исследование единиц того же самого иерархического уровня, которые находятся с интересующим нас значением в отношении несовместимости или пересечения. Это прежде всего слова book 'книга', pamphlet 'памфлет', newspaper 'газета' w. journal 'журнал (преимущественно научный)'. Значение слова magazine противопоставляется значениям
слов book, pamphlet, brochure по признаку периодичности. Для значений слов magazine, journal и newspaper этот признак является интегральным. Magazine противопоставлен newspaper как издание сброшюрованное или переплетенное. Противопоставляя magazine —journal, определяем, что издание, называемое journal, обычно является более специальным по своему содержанию (например, научные журналы).
Этап 4: составление списка тех минимальных диагностических компонентов, которые, во-первых, отличают значение слова magazine от других значений того же уровня, во-вторых, позволяют включить его адекватным образом в рамки ближайшего вышестоящего значения и, в-третьих, удовлетворительным образом охватывают значения его гипонимов. В нашем случае это будут три компонента: 'периодическое издание', 'переплетенное или сброшюрованное' и 'по содержанию и оформлению носящее довольно популярный характер'.
Этап 5: заключительный, состоит в формулировании дефиниции слова на основе его диагностических компонентов. Такая дефиниция обычно включает указание на класс, к которому принадлежит значение (фактически — указание на значение ближайшего гиперонима), и на значимые противопоставления со значениями смежными, пересекающимися и дополнительными. При дефиниции полезно дать также иллюстрацию значения в виде перечисления гипонимов данного слова. В нашем случае дефиниция могла бы выглядеть следующим образом: периодическое издание, в переплетенном или сброшюрованном виде, имеющее относительно популярное содержание и броское оформление, например Time, Fortune, Sports Illustrated. Отметим, что этап 5, по мнению Найды, является факультативным, так как компонентное представление значения слова мы получаем уже на этапе 4.
Вариант компонентного анализа, который мы только что рассмотрели, является типичным для определенной стадии развития данного метода. Каковы характерные черты этой стадии? Во-первых, анализируются отдельные, изолированные слова с учетом парадигматических отношений между ними, т. е. корреляций, но без учета их синтагматических связей, т. е. реляций. Во-вторых, представление имеет вид неорганизованного набора семантических компонентов или, в лучшем случае, упорядоченной последовательности компонентов. В-третьих, как следствие предыдущего положения, все компоненты, или семы, признаются одинаковыми по их логической природе точно так же, как одинаковы различительные признаки в фонологии. Это позволяет думать об описаниях значений слов как о матрицах идентификации, где плюсами, минусами и нулями отмечается наличие, отсутствие или нерелевантность того или иного признака (аналогично тому, как это делается в фонологии). Такой элементарный вариант компонентного анализа вырабатывался на материале конкретной лексики, в этой области он дает приемлемые результаты. Действительно, слова типа журнал, книга, газета или река, ручей, озеро можно описывать
сим и по ceoe, mu«luiiuix 1ш in ни Ныно иырнжгпии, и »ч шичрнир mi статочио хорошо продсжшнмо i> виде упорядоченной шнчюдошишыинчн однотипных семантических компонентов. По как lonhho мы oljptviHMt'H к анализу слов, обозначающих не предметы, а их свойства и отноше ния между ними, как сразу рассмотренный нами вариант компонентного анализа окажется неудовлетворительным.
В той же работе Найды показано, что к словам типа beautiful 'прекрас^ ный, красивый' или righteous 'справедливый' процедура вертикально-го» ризонтального анализа не применима и нужны другие процедуры, названные им процедурами анализа пересекающихся значений, суть которых состоит в обращении к рассмотрению не слова самого по себе, а словосочетаний с данным словом. Проиллюстрируем их на примере слова beautiful.
Этап 1: найти слова, близкие к данному по значению, т. е. слова из того же семантического поля, которые могут использоваться применительно к тем же объектам или событиям: beautiful 'красивый', pretty 'привлекательный', lovely 'очаровательный' и т. п.
Этап 2: выявление круга объектов, которые могут описываться с помощью отобранных слов. Вот здесь-то и приходится обратиться к рассмотрению сочетаний слов. При этом эффективный метод состоит не в том, чтобы перечислять сотни приемлемых атрибутивных словосочетаний с данными словами, а в том, чтобы найти такие контексты, в которых та или иная единица либо неприемлема совсем, либо выглядит необычно, странно. Это называется анализом отрицательного языкового материала.
| dress (платье) room (комната) sight (вид) thought (мысль) old lady (старая леди) nurse (медсестра) |
|
 man (мужчина) woman (женщина) building (здание) *lake (озеро) *scene (сцена) *jewel (украшение)
man (мужчина) woman (женщина) building (здание) *lake (озеро) *scene (сцена) *jewel (украшение)
| в) |

|
| pretty |
cottage (коттедж) 'skyscraper (небоскреб) jewel (украшение)
Этап 3: цель — выявить те аспекты близких значений, на которых основано их противопоставление. Наиболее эффективный прием — постановка квазисинонимов в один и тот же контекст. Так, сравнивая beautiful woman 'красивая женщина' с pretty -woman 'хорошенькая женщина', мы обнаруживаем, что beautiful выражает ббльшую степень интенсивности качества, чем pretty. Сравнивая beautiful old lady с lovely old lady, мы видим, что физическая (внешняя) привлекательность обязательно входит в значение beautiful, но не обязательно для lovely, которое акцентирует
игыиорое примите wiwnnu, iieuhsi шкчп.ио ш\ тпиое с осооыми достоит итми шм'ииичоиидн. С'ршишиаи beautiful woman и handsome woman, мы интим, что II шачепни handsome центральное место занимает компонент гоничестисшюй внешности и идеальных пропорций. В слове же beauti-hil центральным компонентом является общее впечатление от предмета, 1 шорой из названных компонентов слова handsome в значении beautiful шиш) подразумевается.
Этап 4: перечисление существенных признаков слова, по которым щи) противопоставлено своим квазисинонимам:
1) привлекательность;
2) общего вида;
3) в достаточно высокой степени.
Итак, на рассмотренном примере мы видим, что для выявления > 1>мактической структуры абстрактной лексики мы волей-неволей обращаемся к анализу слова в контексте и используем нашу способность «щснить языковые выражения, во-первых, как правильные или неправильные, а во-вторых, как означающие одно и то же или неравнозначные.
5.3. Принципы компонентного анализа значения в Московской семантической школе
Выше мы рассмотрели классический вариант компонентного ана-пиза — тот вариант, который вырабатывался в основном на материале конкретной лексики и не ставил своей целью дать такое описание значения слова, чтобы на его основе можно было построить описание значения единицы более высокого уровня, т. е. предложения. Однако при анализе абстрактной лексики оказывается необходимым скорректировать традиционные методы компонентного анализа в нескольких существенных аспектах. Показать необходимость такого пересмотра нам будет удобно на основе конкретного примера — анализа значения слова только, осуществленного И. А. Мельчуком [Мельчук 1974: 52 и далее]. Это слово мы будем рассматривать в том его узуальном значении, которое оно имеет и контекстах типа (1)-(3):
(1) Я купил только чашки.
(2) Пришло только три студента.
(3) Собака только обнюхала его.
Можно ли описать значение слова только, взятого отдельно, вне тех выражений, в которых оно употребляется, подобно тому, как мы описываем значение слов журнал, или племянник, или стакан, или ручей? Очевидно, что нет. Здесь нам не удастся с достаточной степенью уверенности ни указать родовое по отношению к только слово — гипероним, ни очертить круг слов, с которыми нужно сопоставлять это слово, ни построить интуитивно удовлетворительные семантические пропорции.
116 Раздел!!. Лексическая семантика
Глава 5. Компонентный анализ лексического значения 117
Здесь возможен только такой путь — анализируя значение выражений, содержащих слово только, определить, какая часть этого значения связана с присутствием во фразе слова только. Другими словами, мы должны описывать, строго говоря, не значение отдельно взятого слова только, а значение определенного класса предложений с этим словом.
Итак, зададимся вопросом: как описать значение слова только в составе фразы, например (1)? Очевидно, что надо как-то описать значение всей фразы целиком и посмотреть, какая часть нашего описания будет связана с присутствием во фразе слова только.
А что значит описать значение фразы? Как говорил Р. О. Якобсон, и для лингвистов, и для обычных носителей языка значением любого лингвистического знака является его перевод в другой знак — такой, в котором это значение более полно развернуто [Якобсон 1985: 362]. И приводил пример: холостяк можно преобразовать в выражение неженатый человек, которое более эксплицитно отражает структуру того же значения, так как отдельные элементы смысла получают в его составе особое выражение.
Если мы говорим об описании значения предложения, то таким описанием будет перевод предложения в другое предложение, которое означает то же, что и первое, но в котором это значение выражено более эксплицитно. Иначе говоря, описание значения предложения — это его перифраза на том же самом языке или перевод на специально созданный семантический метаязык, который в более явном виде представляет значение описываемого предложения.
Итак, что значит только во фразе (1)? Для того, чтобы понять это, нам надо построить другую фразу, которая имела бы то же значение (перифразу), и содержала те же слова, кроме только, которое должно быть заменено другими словами, с более понятным значение. Такая фраза будет толкованием исходной фразы, поскольку толкование некоторого выражения х — это тождественное ему по значению выражение, в котором это значение выражено более эксплицитно, т. е. в котором связь между формой и содержанием более очевидна, чем в толкуемом выражении. Толкованием фразы (1) будет фраза (1а):
(1а) Я купил чашки и неверно, что я купил что-либо, кроме чашек.
Аналогичные толкования имеют фразы (2) и (3):
(2а) Пришло три студента и неверно, что пришло сколько-либо студентов,
кроме трех. (За) Собака обнюхала его и неверно, что собака сделала с ним что-либо,
кроме обнюхивания.
Ясно, что на счет только должны быть отнесены правые (после и) части фраз (1)-(3). Теперь нам надо вьывить то общее, что имеют между собой эти правые части, и мы получим описание значения слова только. Поэтому попробуем записать правые части в более общем виде.
Заметим сначала, что во всех них есть отрицание, затем идет повторение левой части, с той разницей, что слово, к которому относится только заменено неопределенным местоимением {что-либо, сколько-либо); после повторения левой части следует кроме + то самое слово, к которому относится только. Обратим внимание, что в что-либо, кроме и т. п. кроме означает 'отличный', 'неравный'.
Обозначим слово, к которому относится только, через А*, а соответствующее ему местоимение через X.
Теперь введем обозначения для оставшихся частей фразы. Обозначим фразы (1)-(3) как Aj, Аг,... только Ак)..., An_i, А„ = {Ап}. Через {А„} обозначим ту же цепочку, из которой, однако, изъяты только и слово Ак. Пусть {Ап(Х)}, наконец, обозначает цепочку {А!п}, в которую вместо Ак вставлен X. Например, если {Ап} = Я купил только чашки, то Ак = чашки, {AJJ = Я купил, а {А„(Х)} = Я купил X.
Это дает возможность дать обобщенную запись как толкуемого выражения, так и толкования:
{А„} только Ак = А^Ак | и неверно, что существует такой X, что X не равен А* и А„(Х).
Описанием значения слова только является часть толкования, начинающаяся с 'и'. Это его дефиниция, толкование, которое так же, как и те дефиниции, с которыми мы имели дело ранее, состоят из семантических компонентов: 'не', 'равно', 'существует' и т.д. Это описание имеет полное право называться компонентным анализом, так как оно также дает представление слова в виде совокупности компонентов: 'и'; 'неверно, что'; 'существует'; 'равно'.
Мы видим, что в выражение, описывающее значение слова только, входят символы, относящиеся не к самому слову только, а к другим составляющим фразы, в составе которой оно употребляется. Это {А„} и Ajc. Это и значит, что описывается не значение отдельного слова только, а значение выражений, обобщенных в формуле {А„} только А^. Вне этого выражения значение слова только не может быть определено. Если нам все-таки кажется, что только означает нечто отдельно, то это, по-видимому, объясняется тем, что мы подсознательно примысливаем к нему типовые контексты.
К тем же результатам мы приходим при попытке дать семантический анализ любого из слов, обозначающего действия, отношения, свойства, слов с предикатным, кванторным или связочным значением. Компонентное представление значения таких слов обязательно включает в себя отсылку к другим составляющим того предложения, в котором употребляются эти слова.
Сформулируем общий вывод: многие слова могут быть описаны семантически только в составе выражений, больших по объему, т. е. словосочетаний или предложений.
118 Раздел II. Лексическая семантика
Глава 5. Компонентный анализ лексического значения 119
Этот вывод впервые был четко сформулирован представителями Московской семантической школы в начале 60-х гг. Правильность такого подхода к описанию значения слов разных семантических полей была убедительно продемонстрирована в целой серии работ, и в настоящее время является одним из важнейших принципов описания означаемых в лексической семантике, признанных и у нас, и за рубежом (см., например, [Бендикс 1983]).
Итак, в противовес классическому компонентному анализу, работавшему с отдельным словом, современные варианты компонентного анализа исходят из того, что в общем случае толкуемой единицей должно быть не отдельно взятое слово Р, а содержащее его выражение вида XPY, где X и Y — переменные, сообщающие данному выражению форму предложения или словосочетания. Такое выражение называется сентенционной формой (от sentence — предложение). Сентенционная форма может называться и ситуационной формой, поскольку, помимо толкуемого слова, она включает переменные, которые обозначают участников описываемой данным словом ситуации. Так, слово расходовать описывается в составе сентенционной (ситуационной) формы А расходует В на Р, слово репутация — в составе сентенционной формы репутация Х-а среди Y-oe, союз пока — в составе сентенционной формы пока А, В.
Обратим внимание на то, что описание значения слов в составе сентенционных форм образует тот необходимый мостик, по которому мы из области лексической семантики переходим в область семантики предложения. Ведь описание значения предикатного слова, выполненное таким способом, представляет собой каркас семантического представления предложения, содержащего данное слово. Для получения семантического представления предложения нужно только подставить на места переменных частей толкования предиката толкования аргументов этого предиката, возможно, произвести некоторые преобразования, и мы получим описание смысла предложения. Когда же мы имеем дело с компонентными представлениями, полученными путем анализа слова вне его синтагматических связей, мы не получим никакого иного представления смысла предложения, чем простое соположение семантических описаний составляющих его слов без указания семантических связей между ними, что, конечно, не может служить однозначным описанием смысла предложения.
Теперь обратимся к еще одному важному аспекту семантического описания слова только. Мы видим, что это не просто набор, хотя бы и упорядоченный, семантических компонентов, а структура, т. е. образование, имеющее вполне определенную организацию. В самом деле, чрезвычайно важно знать, что отрицание относится ко всему выражению, которое за ним следует, а не к какой-либо его части. Если отнести отрицание к части 'X не равен А^', то мы получим совсем другой смысл: 'и существует такой X, для которого неверно, что он не равен А^, и при этом Aj,(X)'. Это описание очень приблизительно соответствует русскому
1 нову именно (Я купил именно чашки). Более точно здесь описано невы-р.пимое одним словом значение усиления, подчеркивания, выражаемого i помощью избыточного повтора. Отнесем отрицание к другой части выражения, и смысл опять изменится: 'и существует такой X, не равный Ак, лня которого верно, что не А ('и есть не чашки, которые я не купил').
Для огромного количества достаточно абстрактных слов необходимость структурированности, строгой организации семантических компонентов при описании значения еще очевиднее. Так, как показал компонентный анализ глаголов оценочного суждения в английском языке, проведенный Ч. Филлмором [Fillmore 1971], из одних и тех же атомов смысла строятся значения слов accuse «обвинять» и criticize «осуждать»: 'юворить', 'нести ответственность', 'считать', 'плохо'. Разница между шачениями этих слов объясняется только тем, что эти компоненты образуют в них разные структуры. В глаголе accuse сема 'нести ответственность' подчинена семе 'говорить', а сема 'плохо' подчинена семе 'считать':
Xaccused YofZ = 'X сказал, что Y несет ответственность за Z, считая, что Z плохо';
it глаголе criticize сема 'нести ответственность' оказывается подчиненной семе 'считать', а сема 'плохо' — семе 'говорить':
X criticized Yfor Z = 'X сказал, что Z(Y) плохо, считая, что Y несет ответственность за Z'.
Здесь уместна аналогия между атомами смысла и атомами вещества. I) лексической семантике, так же как и в химии, соединение одних и тех же атомов разными способами дает разные сущности: разные вещества — изомеры — в химии и разные значения слов в семантике.
Итак, из рассмотрения второго аспекта описания значения слова только и других слов мы можем сделать следующий вывод: значение слова лолжно представляться в виде структуры, состоящей из элементов смысла и связывающих их синтаксических отношений. С формальной точки зрения, это может быть и предложение семантического языка с однозначной синтаксической структурой, и формула исчисления предикатов, и граф, иершинами которого являются смысловые атомы. Тем самым метаязык компонентного анализа должен иметь не только словарь элементарных семантических единиц, но и свой достаточно развитый синтаксис. Этот вывод опять-таки впервые в отечественной лингвистике был четко сформулирован представителями Московской семантической школы.
Теперь рассмотрим наше описание значения слова только еще с одной стороны. Одинаковы ли семы по их логической природе, относятся ли они все к одной и той же логико-грамматической категории? Очевидно, что нет. Среди семантических компонентов, составляющих значение слова только, мы видим, во-первых, предикаты — элементы, которые имеют «места», заполняемые другими элементами, и термы — элементы,
Раздел II. Лексическая семантика
Глава 5. Компонентный анализ лексического значения 121
«мест» для других элементов не открывающие. Предикатами в широком смысле в нашем описании являются компоненты 'существует', 'неверно, что', 'равен', термами — переменные Ак и X. Среди предикатов в широком смысле можно выделить операторы — одноместные предикаты, единственное место которых может заполняться только другим < предикатом (например, оператор отрицания 'не'); связки — предикаты, открывающие не менее, чем два места, которые должны заполняться только предикатами (например, обычная конъюнкция 'и'1'); кванторы — элементы, одно из двух мест которых заполняется термом, а другое — предикатом ('существует такой X, что Р(Х)'), и предикаты в узком смысле — элементы, все места которых могут заполняться только термами, например, 'купил'. (К этим категориям семантических единиц мы еще вернемся при обсуждении семантики предложения, см. раздел Ш.2.1.1.) Отсюда следует еще один вывод, противоречащий установкам классиче ского компонентного анализа: семантические компоненты неоднородны, они принадлежат к разным синтаксическим типам, среди них необходимо различать хотя бы предикаты и термы.
Подведем итог. Метод компонентного анализа значения слова эволюционировал. Из метода, дававшего представление значения отдельно взятого слова в виде неупорядоченного набора однотипных сем, он превратился в метод анализа слова в типовом сентенциальном контексте, и результаты этого анализа представляются в виде выражений специального семантического метаязыка, имеющего фиксированный словарь семантических элементов, принадлежащих к разным синтаксическим типам, и свой синтаксис.
Существуют разные варианты таких семантических метаязыков (далее СМ), которые одновременно являются и языками для описания значений слов, и языками для описания смысла предложения. Имея ряд общих черт, эти языки отличаются друг от друга по целому ряду параметров.
Во-первых, разные исследователи приписывают семантическим компонентам разный онтологический статус. Для одних сторонников компонентного анализа компоненты — это теоретические лингвистические конструкты, с помощью которых удобно описывать системные отношения в лексике или отношения между предложениями, для других — это ментальные сущности, обладающие психологической реальностью.
'* Сентенциональную конъюнкцию, соединяющую предикативные единицы, следует отличать от термовой конъюнкции — оператора, объединяющего термы в один множественный терм [Падучева 1974: 47]. В естественном языке оба вида конъюнкции могут выражаться одним и тем же союзом. Так, например, в русском языке союз и в предложении Точка А и точка В соединены с точкой С представляет сентенциональную конъюнкцию (соединяющую две предикации: 'точка А соединена с точкой С и точка В соединена с точкой С'), а в предложении Точка А лежит между точкой В и точкой С — термовую (образующую множественный терм 'точка В и точка С).
Различно количество единиц словаря метаязыка. В большинстве «шчощихся СМ количество единиц словаря заранее не ограничивается. Предполагается только, что таких единиц существенно меньше, чем
шпиц словаря языка-объекта. Единственным исключением является 1 1 и-ственный Семантический Метаязык (ЕСМ) А. Вежбицкой2), список № аддных семантических элементов которого хотя и меняется время
и иремени, но в каждый данный момент фиксирован.
По параметру соотношения словаря метаязыка и словаря языка —
ньекта можно выделить четыре типа СМ: 1) вырожденный случай СМ,
юнарь которого совпадает со словарем языка-объекта (примером такого «IV! может служить метаязык толкований (дефиниций) в традиционных толковых словарях, формулируемых на том же языке, значения
ион которого описываются, без наложения каких-либо ограничений па словарный состав толкований; 2) СМ, словарь которого пересекает-
• «I со словарем языка-объекта (например, семантический язык модели Смысл ■£=$■ Текст»); 3) СМ, словарь которого представляет собой подмножество множества слов языка — объекта (например, ЕСМ А. Веж-иинкой); 4) СМ, словарь которого не пересекается со словарем языка — пЬьекта (чистых примеров этого типа не существует, но в принципе, они ношожны). Аналогичным образом могут различаться СМ по тому, как их
• и нтаксис соотносится с синтаксисом языка-объекта.
Различаются СМ и по степени полноты отражения значения языко- но го выражения средствами СМ. Применительно к описанию значений i нов при одном подходе постулируется возможность полного (без остатка) [м июжения (декомпозиции) значения на единицы СМ, а при другом подходе допускается неполная декомпозиция, и семантика слова описывается ■ помощью постулатов значения [Карнап 1959], задающих необходимые \словия для употребления данного слова. Так, семантическое описание i юва холостяк с помощью постулатов значения имеет следующий вид:
14) холостяк (х) -*• ЧЕЛОВЕК (х) & МУЖСКОГО ПОЛА (х) & ВЗРОСЛЫЙ (х) & -. ЖЕНАТ (х).
)то показывает, что в значение слова холостяк входят указанные семантические единицы, но, возможно, их совокупностью оно не исчерпывается. Если же мы вместо знака следования (импликации) поставим
шак равенства, то мы тем самым берем на себя «повышенные обязательства» — утверждаем, что все «языковое поведение» данного слова определяется вхождением в его семантическую структуру этих и только этих единиц. В данном конкретном случае подобное решение было»ы поспешным, поскольку не всякого неженатого взрослого мужчину можно назвать холостяком, например, вряд ли это можно сделать по отношению к папе римскому (другие примеры неуместности употребления данного слова при соблюдении условий, сформулированных
Другое, более раннее название этого СМ — lingua mentalis («язык мысли»).
Раздел П. Лексическая семантика
в (2), см. в [Лакофф 1988: 44-45], а объяснение того, чего недостает описанию в (4), чтобы претендовать на полноту, см. в [Вежбицка 1996: 202-204]). Очевидно, что описание в виде постулатов значения — более осмотрительный способ формулирования семантических гипотез. Вместе с тем, от такого описания, в том случае, когда мы уверены, что выявили все семантические связи данного слова с другими словами и / или с миром, легко перейти к описанию в виде полной декомпозиции значения (толкованию). Если мы уверены, что каждое из условий, входящих в формулировку постулата, порознь необходимо, а в совокупности они достаточны для объяснения семантических свойств данного слова, то знак импликации в формулировке постулата (-»•) может быть заменен знаком двухсторонней импликации (<->), который для целого ряда семантических задач может отождествляться со знаком равенства (ср. определение отношения синонимии в терминах двухсторонней импликации в [Лай-онз 1978: 474-475]).
Различаются СМ и по характеру информации, описываемой с помощью данного языка и по исследовательской цели, для которой строится метаязык. Подробнее о различиях между существующими семантическими метаязыками речь пойдет в разделе Ш.З, специально посвященном языкам для описания плана содержания предложения.
Литература
1. Бендикс Э.Г. Эмпирическая база семантического описания // Новое в зарубежной лингвистике. М., 1983. Вып.ХГУ. С. 75-107.
2. Вежбицка А. Из кн. «Семантические примитивы». Введение // Семиотика. М., 1983. С. 225-252.
3. ЛайонзДж. Введение в теоретическую лингвистику. М., 1977. Гл. 10.
4. Мельчук И. А. Опыт теории лингвистических моделей «Смысл •*=>■ Текст». М., 1974. С. 52-140.
5. Найда Ю. Процедуры анализа компонентнойной структуры референционного значения // Новое в зарубежной лингвистике. М., 1983. Вып.ХГУ. С. 61-74.
6. Якобсон Р. О. О лингвистических аспектах перевода // Якобсон Р. О. Избранные работы. М., 1985. С. 362.
Глава 6
Тезаурус как модель парадигматической структуры плана содержания языка
В предыдущем разделе мы рассматривали один из возможных под-чидов к описанию лексико-семантического уровня языковой системы — метод компонентного анализа лексического значения. Теперь мы обра-шмся к другому, не менее авторитетному и распространенному подходу i «писанию системных отношений в лексике — тезаурусному методу, или i\te году построения словарей-тезаурусов.
Своим названием этот метод и этот тип словарей обязан широко и тестному словарю Роже, или Роджета (Roget's International Thesaurus of I nglish Words & Phrases). Словарь был составлен англичанином П. М. Род-isi'tom «для облегчения выражения понятий (ideas) и для помощи при написании сочинений» и опубликован в Лондоне в 1852 году.
С тех пор появился целый ряд словарей, подобных Тезаурусу Роже, и слово «тезаурус» применительно к словарям стало из имени собственно-П) именем нарицательным, обозначающим определенный тип словарей. Чнсны Кембриджского лингвистического кружка, которые использовали пчаурус Роже в работах по автоматическому переводу, писали по этому поводу, что на вопрос о том, что такое тезаурус, проще всего было бы птетить, показав несколько существующих словарей-тезаурусов, например хорошо известный словарь Роджета, и сказать, что тезаурус — это шобая система классификации слов языка, относящаяся к такому же шпу и имеющая такую же форму, как и этот словарь. Тезаурус Роже представляет собой собрание слов английского языка, сгруппированных и шесть крупных тематических классов/категорий:
1. Абстрактные отношения. 4. Разум.
2. Пространство. 5. Воля.
3. Материя. 6. Чувственные и моральные силы.
Эти классы подразделяются на 24 подкласса. Например, в клас-м" Пространство выделяется 4 подкласса: 2.1. Пространство вообще. 12. Измерение. 2.3. Форма. 2.4. Движение. В рамках этих подклассов пыделяются более мелкие подклассы и т. д., вплоть до самых мелких, ылее не подвергающихся членению тематических групп, которых насчи-плвается около тысячи. (Ниже, на схеме 2, вы можете увидеть, в какие крупные тематические классы и группы попадают в тезаурусе Роже гла-тлы, обозначающие речевые действия).
Раздел II. Лексическая семантика
Глава 6. Тезаурус как модель парадигматической структуры 125
Тезаурус снабжен указателем, в котором все включенные в него слова расположены в алфавитном порядке и каждому слову приписаны i номера тематических групп, в которые оно входит.
Какое из ранее рассмотренных нами понятий, используемых при описании лексико-семантической системы языка, напоминает тематическая группа? Конечно, семантическое поле, точнее, семантическое микрополе. Действительно, семантическое поле мы определяли как совокупность языковых единиц, объединенных общностью содержания (и отражающих понятийное, предметное или функциональное сходство обозначаемых ими явлений). Следовательно, тезаурус можно рассматривать как систему семантических полей данного языка.
Словари такого типа называются также идеологическими, идеографическими или концептуальными словарями. В отличие от толковых словарей, в которых на входе мы имеем слова, упорядоченные по некоторому формальному принципу, чаще всего по алфавиту, а на выходе — описание значения слова в виде дефиниции или толкования, в идеологическом словаре — словаре-тезаурусе — на входе мы имеем «идеи», т. е. семантические, содержательные категории, упорядоченные с помощью той или иной классификации, а на выходе — слова, выражающие данную содержательную категорию. В литературе по семантике принято различать два подхода к описанию соответствия между формой и содержанием в языке. Подход, при котором исследователь, отталкиваясь от формы, идет к установлению ее содержания, называется семасиологическим, а подход, при котором исходным пунктом служат единицы содержания, а конечным — способы формального выражения этого содержания — ономасиологическим. Очевидно, что толковые словари, предназначенные для поиска значений по заданным словам, соответствуют семасиологическому принципу описания, а идеологические, предназначенные для поиска слов по заданным значениям, — ономасиологическому. Получается, что тезаурусы — это, в определенном смысле, обращенные толковые словари.
Одно и то же слово в общем случае может входить в несколько классов тезауруса, во-первых, потому, что оно может иметь несколько разных узуальных значений, а во-вторых потому, что даже в одном из своих узуальных значений оно может быть связано не с одной, а с несколькими понятийными сферами. Так, например, слово переговоры в тезаурусе [Караулов и др. 1982], с одной стороны, входит в класс слов, связанных общим понятием ЯЗЫК, с другой стороны — в класс слов, связанных с идеей ПОСРЕДНИЧЕСТВА; слово finish «заканчивать» в тезаурусе Роже входит в группы слов, объединяемых идеями 'времени', 'изменения', 'дискретности' и целый ряд других. Поэтому каждое слово можно охарактеризовать с помощью определенного набора индексов или адресов классов, в которые оно входит в данном тезаурусе. В тезаурусах ', обычно имеется алфавитный указатель слов с их адресами, отсылающими ко всем тем семантическим или понятийным полям, в которые оно входит.
Уточняя введенное представление о тезаурусе, мы должны сказать, ч ю стандартный тезаурус имеет, как правило, четыре входа:
1) К -> К, вход от концепта к концепту, от одного понятия к другому, воплощенный в схеме вертикально и горизонтально связанных друг с другом понятий, т. е. понятий, связанных родо-видовыми (гипоними-ческими), видо-видовыми и другими видами корреляций. Такая схема, нежащая в основе тезауруса, называется синоптической схемой.
2) К -> 3, вход от концепта к знаку, от понятия к слову — основная часть тезауруса.
3) 3 -> К, вход от знака к концепту, соответствующий алфавитному списку слов с указанием их адресов в понятийных полях тезауруса.
4) 3-43, вход от знака к знаку, необходимый для тех тезаурусов, II которые наряду со словами входят и словосочетания, и в связи с этим от слов, входящих в словосочетание, дается отсылка к отдельным словам, например от слова автоматический к слову автоматизация.
Остановимся поподробнее на первом входе в тезаурус — на синоптической схеме, т.е. общей схеме взаимосвязи понятий.
В каждом из известных тезаурусов имеется такая схема, причем схемы разных тезаурусов отличаются друг от друга. Откуда же берутся ткие схемы? Что они отражают? Ответить на этот вопрос можно по-разному. Во-первых, можно считать, что в основу тезауруса должна быть моложена система понятий, соответствующая научной картине мира.
Термин «научная картина мира» прочно вошел в современную ли-1ературу по методологии и истории науки. Содержание этого понятия мы вслед за В. Ф. Черноволенко определим как систему знаний, синте-жрующую результаты «исследования конкретных наук со знанием миро-поззренческого характера, представляющим собой целостное обобщение совокупного практического и познавательного опыта человечества» (цит. по [Караулов и др. 1982: 43]). Однако в настоящее время общенаучная картина мира еще не разработана. Ее построение предполагает синтез научных картин мира, разработанных в отдельных областях знания: в фишке, астрономии, обществоведении и т. д. Но их обобщению в единую и целостную систему препятствует не только нерешенная проблема синтеза частных картин мира, но и неравномерность развития отдельных отраслей научного знания. Так, если в физике произошла уже смена трех картин мира — аристотелевской, механической, электродинамической, п господствующей в настоящее время стала четвертая — квантово-поле-ная, то в биологии, например, имела место только одна смена: первая картина мира — дарвиновская — была в последнее время заменена моле-кулярно-генетической, в которой используются уже достижения физики, чимии и других наук. Однако взаимосвязь между такими картинами мира, как квантово-полевая и молекулярно-генетическая, можно проследить только по отдельным аспектам, для создания же единой картины

|
Схема 1
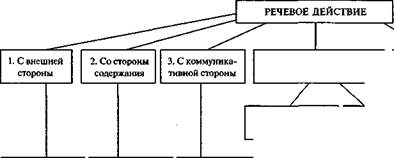
Структура семантического поля речевых действий по Л. М. Васильеву*
|
| 6. Выражение эмоционального отношения и оценки |
| 4. Речевое взаимодействие и контакт |
| Эмоциональная оценка |
| Взаимодействие |
| Контакт |
| 1. Обижание 2. Насмешка 3. Этикетные речевые действия |
Эмоциональное отношение
| 1. Разговор 2. Договор 3. Спор 4. Обсужде- |
| 1.Произнесение 2. Издавание звуков 3. Письмо 4. Чтение 5. Именование |
| 1. Высказывание 2. Болтовня 3. Шутка 4. Острословие 5. Любезничанье 6. Обман 7. Философствование |
| 1. Сообщение 2. Обещание 3. Совет 4. Объяснение 5. Доказательство |
| 1. Вопрос 2. Ответ 3. Согласие 4. Возражение 5. Отрицание 6. Обращение |
| 1. Общая 2. Отрицательная 3. Положительная |
1. Приказание
2. Поручение
3. Подстрекательство
4. Просьба
5. Приглашение
6. Подзывание
7. Посылание
8. Склонение
9. Разрешение
10. Запрещение
* Приводимая схема построена в точном соответствии с той классификацией, которая дана в [Васильев 1971]. При этом для обозначения микрополей в большинстве случаев используется существительное, образованное от глагола, являющегося доминантой микрополя.
Ш Р
51
Со
:»;
S
Е
§
о-
а
s
С CD О
?*
О
Sc
о-
Структура семантического поля речевых действий по тезаурусу Роже *
Схема 2
| |l.Предупреждсиие| | 1.Совет | |
| Общее |
| 1. Приказание |

| Способ передачи |
| Средства передачи |
1. Вопрос 2. Ответ
Характер мысли
| 1. Двусмысленность | 1. Информиро- | 1. Произнесение |
| 2. Интерпретация | вание | 2. Молчание |
| 3. Неправильная | 2. Признание | 3. Говорение |
| интерпретация | 3. Утверждение | 4. Говорение |
| 4. Отрицание | с дефектом | |
| 5. Правдивость | 5. Болтовня | |
| 6. Лживость | 6. Немного словность 7. Обращение | |
| 8. Разговор | ||
| 9. Разговор | ||
| с самим собой | ||
| 10. Письмо | ||
| 11. Описание |
1. Острословие
2. Насмешка
3. Прославление
4. Поношение
5. Хвастовство
1. Разрешение
2. Запрещение
3. Согласие
4. Предложение
5. Отказ
6. Просьба
1. Приветствие
2. Поздравление
3. Благословение
4. Проклинание
5. Угроза
6. Благодарение
7. Прощение
1. Обещание
2. Договор
3. Обсуждение
1. Одобрение
2. Осуждение
3. Лесть
4. Клевета
5. Обвинение
6. Оправдание
7. Приговаривание
U
о
U
X -с а> о
о
<ъ
О)
* В схему включены все микрополя, глагольная часть которых состоит преимущественно из ядерных глаголов речи. Микрополя, состоящие преимущественно из периферийных глаголов речи (напр., отмена), не учитывались. Название классов, данных Роже, сохранились, если они могут пониматься как имя действия (напр., Отрицание, Обещание). Если в качестве названия микрополя выступало не имя действия, то оно заменялось соответствующим по значению именем действия (напр., Голос —¥ Произнесение), а при отсутствии подходящей замены сохранялось без изменения (напр., Двусмысленность).

Структура семантического поля речевых действий по Баху и Харнишу
Схема 3
1.  Ассертивы
Ассертивы
2. Предиктивы
3. Ретродиктивы
4. Дескриптивы
5. Аскриптивы
6. Информативы
7. Конфирмативы
8. Концессивы
9. Ретрактивы
10. Ассентивы
П.Диссентивы
12.Диспутативы
13. Респонсивы
14. Суттестивы
15. Суп позитивы
1. Реквистивы
2. Вопросы
3. Требования
4. Прогибитивы
5. Пермиссивы
6. Советы
1. Обещания
2. Предложения
1. Приветствия
2. Сочувствия
3. Отношения
4. Извинения
5. Благодарности
6. Пожелания
1. Изменив служебного положения или социального статуса
2. Изм. институционального статуса объекта (дарить, посвящать и т. п.)
3. Инститциональ-ные реквестивы, пермиссивы и прогибитивы (санкционировать и т. п.)
4. Изм. самих об-щест. институтов и т. д. (распускать, легализовать
и т. п.)
1. Символизация
2. Оценка
1. Поддразнивание
2. Рассказывание
3. Шутки
4. Пародирование
5. Декламация
и т. д.
1. Наме-кание и т. д.
1. Экивоки
2. Перемена темы
и т. д.
I
51
со
§ о-
В
О)
С CD
I
St
О
I
А
To
 Глава 6. Тезаурус как модель парадигматической структуры 131
Глава 6. Тезаурус как модель парадигматической структуры 131
па внеязыковой картине мира, будет словарем лингвистическим, отражающим семантическую структуру данного языка.
Тем более это относится к тезаурусам, синоптические схемы которых ныводятся из анализа лексики данного языка. Построенные таким обра-юм схемы наглядно отражают наивную картину мира, запечатленную в семантической структуре данного языка. Так, Р.Халлиг и В. Вартбург [Hal-lig, Wartburg 1952], разрабатывая систему понятий для идеологического словаря, поставили перед собой цель отразить в ней «то представление о мире, которое характерно для среднего интеллигентного носителя языка и основано на донаучных общих понятиях, предоставляемых в его распоряжение языком». Это представление о мире они назвали «наивным реализмом». По сути дела, те же идеи легли в основу разработки семантических метаязыков для описания значений слов. Достаточно вспомнить lingua mentalis Вежбицкой, воплощающий, по замыслу автора, понятийную основу «наивной картины мира».
Существуют и попытки объединить при построении тезауруса обе ориентации. Так, синоптическая схема русского тезауруса, разработанная под руководством Ю. Н. Караулова, основана на синтезе современных знаний о структуре лексики и некоторых представлений о научной картине мира (см. [Караулов и др. 1982: 45]).
Идеографический словарь, или тезаурус, является средством описания парадигматической структуры плана содержания языка, потому что в тезаурусе эксплицитным образом отражен факт наличия парадигматической семантической связи между лексическими единицами путем объединения связанных единиц в поля с общим смысловым признаком, и тем самым определено место каждой лексемы внутри системно организованного смыслового континуума. Важно подчеркнуть, что в общеязыковом тезаурусе каждое слово сопоставляется со всем словарем и получает определение на основе полного объема значений, выражаемых в данном языке.
Как мы уже говорили, каждое слово в тезаурусе характеризуется набором адресов тех семантических полей, в которые оно входит. Такая характеристика значения слова называется тезаурусной презентацией, или тезаурусным определением лексического значения. Остановимся поподробнее на этом способе представления значения слова.
Классификационный признак, выраженный в названии класса, семантически противопоставляет слова, принадлежащие данному классу, прочим словам, т. е. является дифференциальным и описывает значения слов данного класса с точностью до принадлежности к данному классу. Тезаурус не является разбиением, его классы пересекаются, т. е. существуют слова, входящие сразу в несколько рядов противопоставлений. Если мы укажем все парадигматические классы каждого такого слова, то получим совокупность элементов, характеризующих его значение.
В качестве примера тезаурусной презентации лексического значения можно привести характеристику слова возникать из экспликационного
Раздел II. Лексическая семантика
Глава 6. Тезаурус как модель парадигматической структуры 133
тезауруса, построенного в диссертации М. Ф. Толстопятовой [Толстопя-това 1976] для целей алгоритмического семантического анализа текстов управленческих документов:
возникать — 1.6.1 & 1.12.1, где 1.6.1 — «Существование, бытие, наличие», 1.12.1 — «Начало».
Вы можете заметить, что тезаурусная презентация лексического значения очень похожа на представление значения в виде набора семантических компонентов, связанных конъюнктивно или дизъюнктивно. И это естественно, поскольку оба способа представления лексического значения отражают одну и ту же реальность — парадигматические отношения между значениями слов в системе языка. Отличие одного способа представления от другого состоит в том, что при компонентном анализе учитываются и моделируются отношения между словами, образующими одно микрополе, т. е. самый мелкий класс в тезаурусной классификации, тогда как в тезаурусе отношения между элементами одного микрополя не эксплицируются. Поэтому в общем случае компонентный анализ дает более полное и точное описание значения, чем тезаурусная презентация.
Естественно, если тезаурусы различаются между собой по лежащей в их основе синоптической схеме, то и презентация значения одного и того же слова в этих тезаурусах будет различной. В качестве примера рассмотрим значение глагола спрашивать (или его переводного эквивалента в английском языке — глагола ask), увиденное через призму разных классификаций (см. схемы 1-4). Семантическая характеристика слова в тезаурусе задается прежде всего иерархической цепочкой имен классов, в которые оно входит, где имя класса репрезентирует соответствующую понятийную область или отдельное понятие. В классификации Л. М. Васильева глагол спрашивать представлен следующей цепочкой: РЕЧЕВОЕ ВЗАИМОДЕЙСТВИЕ Э КОНТАКТ D ВОПРОС. Тем самым акцентируется интерактивный, социативныи аспект значения данного слова. Несколько иначе представлено место того же глагола в лексико-семантической системе в словаре под редакцией В. В. Морковкина: ЧЕЛОВЕК Э ЧЕЛОВЕК В ОБЩЕСТВЕ Э КОММУНИКАЦИЯ МЫСЛЕЙ И ЧУВСТВ D РЕЧЕВОЕ ОБЩЕНИЕ Э ВОПРОС. Помимо интерактивного аспекта выделен и коммуникативный. Глагол ask в тезаурусе Роже представлен цепочкой ИНТЕЛЛЕКТ D ФОРМИРОВАНИЕ ИДЕЙ Э ПРЕДВАРИТЕЛЬНЫЕ УСЛОВИЯ И ОПЕРАЦИИ Э ВОПРОС. Очевидно, что на первом плане здесь оказывается связь спрашивания с познавательной деятельностью. Наконец, у Баха и Харниша ask репрезентируется цепочкой ИЛЛОКУЦИЯ Э КОММУНИКАЦИЯ Э ПОБУЖДЕНИЕ Э ВОПРОС, т. е. спрашивание трактуется как разновидность воздействия на адресата (побуждение сообщить информацию).
Итак, мы видим, что, имея тезаурус, можно на его основе получить описание значения слов, своего рода толкования. Можно поставить перед
i обой и противоположную задачу: как, имея описание значений всех слов, i е. толковый словарь, получить на его основе тезаурус.
Пусть мы имеем описание значений слов в виде набора семантических элементов. Такие описания мы получаем методом компонентного ннализа. И пусть у нас есть синоптическая схема, задающая иерархию понятий. Мы должны получить семантические группировки слов, соответствующие понятиям, образующим терминальные, т. е. самые нижние узлы синоптической схемы, т. е. группы слов, раскрывающие понятие, предста-нленное некоторым «заглавным словом», т. е. словом, которое в данном и зыке служит как основное средство выражения данного понятия. Пусть)го будет слово давать. Возьмем толкование этого слова: 'каузировать иметь'. Ясно, что для получения класса слов, которые в данном языке используются для выражения идеи «давания», надо выбрать все те слова, которые содержат в своей дефиниции ту же конфигурацию смысловых компонентов: брать, одалживать, передавать, дарить, продавать и т. д.
Ю. Н. Караулов поставил перед собой задачу, действуя путем, описанным выше, автоматически получить тезаурус на основе толкований обычного толкового словаря. Если устранить синонимию и омонимию и множестве слов, фигурирующих в толкованиях, точнее, основ таких слов, то мы получим набор однозначных семантических единиц — семантических множителей. Переписав все дефиниции толкового сло-иаря в терминах семантических множителей, мы получаем возможность автоматически выбрать из толкового словаря все слова, в дефиниции которых встречаются множитель или группа множителей, соответствующая любому слову, которое мы назначим дескриптором (= «заглавным словом» тематической группы тезауруса). В результате проведения этого масштабного эксперимента появился «Русский семантический словарь» [Караулов, Молчанов и др.], содержащий группировки слов, полученные вышеописанным способом. В качестве примера приведем тематическую группу слов, соответствующую дескриптору МАТРАЦ вместе со списком тех семантических мномножителей, по которым она была выделена:
599 М А Т Р А Ц
семантические множители: 1.матра—1, 2.стега—1, З.тюф—1, 4. крова—2, 5. подсти—2, б.постел—2, 7. сен—2, 8. солом—2, 9.наби—3, 10. мешо—6, 11. толе—7, 12. шерст—7, 13. трав—11, 14. мягк—18.
Число слов, включенных в статью дескриптора — 23.
желудок 5*10 злаковые 9*8 карман 12*10
кровать12*1,4,6 лежать 16*6 матрац 8*1,2,4,5,11,14
медведь 8*11,12 мешок 15*10,14 одеяло 5*6
пакет 7*10 плотный 14*9,11 подстилка 2*5
подушка 12*9,10 постелить10*6 постель 6*6
простыня 9*6 пузырь 21*10 пух 16*12,14
Не нашли, что искали? Воспользуйтесь поиском: