ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
U:компьютерный,текст,обработка
U:анализ,текст
Эта категория позволояет идентифицировать в тексте соответствующие словосочетания.
Для того, чтобы сформировать новую категорию, введите в окне ввода словарного состава контекста необходимые слова. Каждое слово вводится в отдельной строке. Затем укажите диапазон контекста и тип упорядочения слов. Очевидно, что диапазон не может быть меньше, чем количество слов контекста минус единица. Когда все будет сделано, нажмите кнопку < Добавить строку >. В левом окне состава категории появится строка контекста. Для ввода следующей строки контекста нажмите кнопку < Очистить >. Это приведет к очистке окна ввода словарного состава контекста.
Если Вам понадобится удалить одну из строк категории, то просто выделите ее мышкой и нажмите кнопку < Удалить строку >. Если понадобится очистить всю категорию, то нажмите кнопку < Очистить категорию >.
Для сохранения сформированной категории на жесткий диск нажмите кнопку <Сохранить категорию>. Она будет сохранена в специальной директории ...\VAAL\Category в файле с тем именем, которое Вы указали, и с расширением cat.
Две оставшиеся кнопки < Помощь > и < Выход > не требуют особых комментариев.
Конфигурация категорий
Для удобства и наглядности представления результатов контент-анализа текста, категории объединяются в группы. Основаниями для этого служат различные содержательные соображения. Например, среди встроенных категорий есть группа категорий, представляющих различные акцентуации, другая группа представляет мотивы, которыми руководствуются люди в своих поступках, и т.д.
Пользователь имеет полный контроль над тем, как группировать категории. Это относится в том числе и ко встроенным категориям.
После выбора в меню системы пункта < Конфигурация категорий > появляется двустраничное диалоговое окно. Первая страница озаглавлена - Группы категорий, а вторая - Рабочие группы.
Группы категорий
На странице находятся:
¨ список всех доступных категорий;
¨ разворачивающийся список доступных групп;
¨ окно содержания группы категорий;
¨ статусную строку с указанием языка;
¨ кнопки < Удалить группу >, < Очистить группу >, < Сохранить группу >, < Помощь > и < Выход >.
Для того, чтобы сформировать группу категорий, необходимо перенести их из списка всех доступных категорий в окно содержания группы. Для того, чтобы удалить категорию из группы, перенесите ее в список всех категорий. Чтобы удалить все категории из группы, достаточно нажать кнопку < Очистить группу >.
 |
Чтобы изменить порядок категорий в группе, просто перетащите ее мышкой вверх или вниз.
Когда группа категорий будет сформирована, нажмите кнопку < Сохранить группу >. Вам будет предложено ввести ее имя.
Чтобы модифицировать ранее созданные группы категорий, раскройте список всех групп категорий, из которого выберите необходимую группу.
Чтобы удалить любую из групп категорий с диска, выберите в строке ввода имени группы категорий и нажмите кнопку < Удалить группу >.
Рабочие группы
На странице находятся:
¨ список всех доступных групп категорий;
¨ список рабочих групп категорий;
¨ кнопки < Очистить >, < Сохранить >, < Помощь > и < Выход >.
В левом списке всех доступных групп категорий Вы отмечаете требуемые категории и переносите их в правый список рабочих групп. Убрать любую группу из списка рабочих групп Вы можете путем переноса ее в список всех доступных групп. Чтобы очистить весь список рабочих групп, нажмите на кнопку < Очистить >.
 |
Порядок следования рабочих групп можно изменить, перетащив их мышкой вверх или вниз.
Когда работа будет завершена, нажмите на кнопку < Сохранить >, чтобы запомнить требуемую конфигурацию рабочих категорий.
Параметры контент-анализа
На странице находятся:
¨ список всех доступных контекстных категорий;
¨ переключатель типа ассоциативных связей;
¨ переключатель типа единиц контекста;
¨ кнопки < Анализ >, < Помощь > и < Отказ >.
 |
Понятие контекста является ключевым для реализованной в системе ВААЛ модели контент-анализа. Дело в том, что в одном и том же тексте могут одновременно присутствовать несколько предметов/тем обсуждения. Они могут описываться совершенно по-разному, и потому интегральная оценка всего текста не будет иметь никакого смысла, если целью анализа является выявление различий в представлении этих предметов/тем. Для решения этой задачи можно было бы вручную выбрать в тексте те предложения или абзацы, в которых содержатся упоминания интересующих предметов/тем и проанализировать их отдельно, но гораздо удобнее автоматизировать этот процесс. Что и сделано в ВААЛе.
Контекст анализа может:
¨ состоять из всего анализируемого текста;
¨ состоять из некоторых предложений текста;
¨ состоять из некоторых абзацев текста.
В первом случае из списка всех доступных контекстных категорий следует выбрать строку (Универсальный).
Во втором и третьем случаях для указания на интересующий заранее должна быть создана соответствующая категория. Например, для указания на контекст упоминания напитка Кока-кола заранее должна быть создана категория, состоящая из одного слова "Кока-кола". Именно эту категорию и следует выбрать в списке контекстных категорий. Затем следует установить переключатель типа единиц контекста - предложение или абзац.
Если контекст анализа не является универсальным, то может быть поставлена дополнительная задача выявления ассоциативных связей контекстной категории. Они выявляются путем составления специального частотного словаря анализируемых контекстов. При этом в словарь могут заноситься либо все слова анализируемых контекстов, либо лишь те, которые встречаются в этих контекстах существенно чаще, нежели во всем тексте. Этой цели как раз и служит переключатель типа ассоциативных связей.
Когда все установки сделаны, остается лишь нажать кнопку < Анализ >.
Нагрузка на категории
Анализ используемой человеком лексики и особенностей ее употребления позволяет получить много полезной информации. Путем такого анализа система ВААЛ позволяет оценить различные характеристики текста и его автора.
Таблица, представленная на первой странице, содержит общие категорно-статистические оценки текста:
Ø первая колонка - имя категории;
Ø вторая колонка - процент слов данной категории от общего объема текста;
Ø третья колонка - количество слов данной категории, встретившихся в анализируемом тексте;
Ø четвертая колонка - гистограмма для визуального представления количественных характеристик распределения;
Ø пятая колонка - оценка отклонения количества встретившихся слов данной категории от среднеязыковой нормы. Это традиционная оценка в контент-анализе, известная как z-score. Подсчитывается она по следующей формуле: (N-E)/(стандартное отклонение), где N - количество слов данной категории, встретившихся в анализируемом тексте, а E - ожидаемое число вхождений слов данной категории в текст;
Ø шестая колонка - гистограмма для визуального представления оценки отклонения количества встретившихся слов данной категории от среднеязыковой нормы. Красный цвет соответствует значительному превышению нормы, синий - значительному отклонению в меньшую сторону, серый - несущественному отклонению от нормы.
При подсчете ожидаемого числа слов некоторой категории в тексте учитывается длина этого текста (в словах) и нормальная частота встречаемости слов категории в языке. Так как частоты встречаемости слов меняются со временем, отличаются у различных слоев населения, профессиональных групп и пр., то для учета этого как раз и служат жанры в системе ВААЛ.
 |
Жанр, относительно которого производится оценка, указан в статусной строке окна. В основном жанре используются нормальные частоты из обязательной программы по литературе для поступающих в ВУЗы. Эти частоты сопоставлены на этапе создания системы только встроенным категориям. Поэтому, если Вы оцениваете текст относительно основного жанра, то для сформированных Вами категорий пятая и шестая колонки таблицы будут пусты. При оценке относительно производных жанров эти колонки будут заполнены, но в этом случае необходимо соблюдение некоторых предосторожностей, о которых сказано разделе помощи, посвященном созданию жанров.
Под таблицей находится флаг Нормализованный оценки. Если его установить, то оценки будут пересчитаны для текста той длины, которая указана самим пользователем. Это удобно для сравнения текстов различной длины.
Если вы хотите сохранить оценки текста в файл для последующего использования, то нажмите кнопку <Протокол>. В появившемся окне вам необходимо указать имя файла. Если указано имя уже существующего файла, то данные добавляются в его конец. Для хранения протоколов по умолчанию используется специальная директория ...\VAAL\Protocol.
В ряде случаев возникает задача вторичной математической обработки результатов оценки текстов. Для сохранения и накопления результатов оценки вы можете воспользоваться кнопкой < База данных >. При нажатии на нее вам будет предложено сохранить оценки текста в файле. Если указано имя уже существующего файла, то данные добавляются в его конец. Накопив в одном файле оценки текстов, вы можете затем их подвергнуть дополнительному анализу с использованием модуля визуализации системы ВААЛ, либо более изощренным видам анализа с использованием таких известных систем как Statistica и SPSS.
Файлы данных хранятся в специальной директории ...\VAAL\Data. При сохранении можно дополнительно указать следует ли сохранить проценты, частоты или коэффициенты Cf. В зависимости от сделанного выбора система сама присвоит файлу расширение dpr, dfr или dcf.
Дополнительно Вы имеете возможность распечатать таблицу на принтере.
Профили категорий
Очевидно, что слова различных категорий распределены в тексте неравномерно. Знание такого распределения позволяет получить информацию об акценте на те или иные категории в разных частях текста.
На второй странице имеются:
¨ окно профиля категорий;
¨ список категорий.
Для построения профиля категорий текст разбивается на 50 примерно равных по длине отрезков и для каждого из них подсчитывается, сколько раз встретились в нем слова той или иной категории. В зависимости от этого и вычерчивается график.
Чтобы получить профиль для конкретной категории, следует выбрать ее в списке справа.
 |
Установив курсор на один из столбиков профиля категории и дважды щелкнув левой кнопкой мышки, Вы можете закрыть окно и установить курсор в начало того куска текста, который соответствует выбранному столбику.
В ряде случаев возникает задача вторичной математической обработки профилей категорий. Для сохранения и накопления профилей вы можете воспользоваться кнопкой < База данных >. При нажатии на нее вам будет предложено сохранить профиль в файле. Если указано имя уже существующего файла, то данные добавляются в его конец. Накопив в одном файле профили категорий, вы можете затем их подвергнуть либо факторному анализу с использованием соответствующего модуля системы ВААЛ, либо более изощренным видам анализа с использованием таких известных систем как Statistica и SPSS. Файлы данных хранятся в специальной директории ...\VAAL\Data. Система сохраняет данные в файлах с расширением dof. Вам не нужно беспокоиться о правильном расширении файла. Система сделает это за Вас. Следует учесть при этом, что в отличие от протокола в файл сохраняется профиль лишь той категории, которая выбрана в списке.
Связи категорий
Что мы получим, если вычислим коэффициент корреляции между профилями двух категорий? Мы получим оценку силы и вида (положительной/отрицательной) связи между двумя этими категориями в анализируемом тексте (в голове автора текста).
Таблица, представленная на третьей странице, содержит оценки связи между категориями:
Ø первая колонка - имя категории;
Ø вторая колонка - коэффициент корреляции (от -1 до +1);
Ø третья колонка - график для визуального представления корреляционной силы связи между категориями. Красный цвет - положительная связь, синий - отрицательная, серый - связь незначимая.
Для того, чтобы получить связи конкретной категории с другими, достаточно выбрать ее в списке справа. Особенно интересными и информативными могут оказаться не связи между встроенными категориями, а между встроенными и сформированными пользователем категориями. Например, Вы можете создать категорию, представляющую известного политика, и оценить в некотором тексте ее связи с психологически нагруженными категориями. В этом случае Вы получите психологический портрет политика, каким его видит автор текста.
 |
Если вы хотите сохранить связи категорий в файл для последующего использования, то нажмите кнопку < Протокол >. В появившемся окне вам необходимо указать имя файла. Если указано имя уже существующего файла, то данные добавляются в его конец. Для хранения протоколов по умолчанию используется специальная директория ...\VAAL\Protocol.
В ряде случаев возникает задача вторичной математической обработки связей категорий. Для сохранения и накопления связей вы можете воспользоваться кнопкой < База данных >. При нажатии на нее вам будет предложено сохранить связи в файле. Если указано имя уже существующего файла, то данные добавляются в его конец. Накопив в одном файле связи категорий, вы можете затем их подвергнуть либо факторному анализу с использованием модуля визуализации системы ВААЛ, либо более изощренным видам анализа с использованием таких известных систем как Statistica и SPSS. Файлы данных хранятся в специальной директории ...\VAAL\Data. Система сохраняет данные в файлах с расширением dcn. Вам не нужно беспокоиться о правильном расширении файла. Система сделает это за Вас.
Дополнительно Вы имеет возможность распечатать таблицу на принтере.
Визуализация
Если при анализе текста используется много категорий, то бывает трудно охватить и осмыслить существующие между ними связи. Существуют два выхода из этой ситуации. Первый - сохранить результаты в Базу данных и затем проанализировать их с помощью одного из статистических пакетов. Второй - произвести непосредственную визуализацию связей.
Идея визуализации заключается в следующем. Возьмем произвольную категорию и назовем ее (горизонтальной) осью X. Вычислив корреляционные связи этой категории со всеми остальными, мы получим некоторые координаты от -1 до +1 этих категорий на оси X. Возьмем теперь другую категорию и назовем ее (вертикальной) осью Y. Вычислим корреляционные связи второй категории со всеми остальными и получим их координаты на оси Y.
Итак, мы получили координаты всех категорий в некотором двухмерном пространстве. Осталось их отобразить. Именно это и делается на странице визуализации.
Справа вверху имеются две строки с именами категорий, обозначенные буквами X и Y. Это две условных координатных оси. Имена категорий в строках легко изменить, выбрав их из выпадающих вниз списков.
Ниже находится список пронумерованных категорий.
Слева на фоне темно-серого квадрата изображены цифры, обведенные окружностями. Каждая цифра соответствует номеру категории. Визуализация производится в двухмерном пространстве.
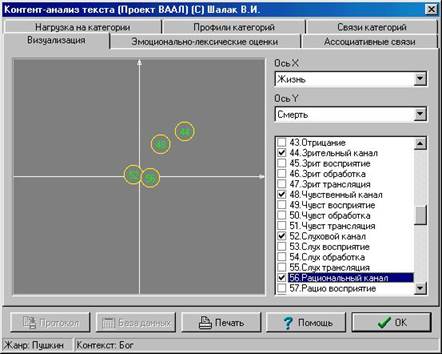 |
Пользователь имеет возможность указать системе на то, чтобы она отображала лишь некоторые категории. Для этого достаточно поставить галочку в квадратике слева от интересующей категории. Двойной щелчок мыши позволяет изменить отмеченность всех категорий на противоположную.
Дополнительно Вы имеет возможность распечатать пространственное отображение категорий на принтере.
Эмоционально-лексические оценки
Категории эмоционально-лексической оценки позволяют оценить эмоциональный фон текста. Эмоции включают непосредственное переживание значимости действующих на индивида явлений и ситуаций для осуществления его деятельности ("состояние"), прогноз результатов деятельности ("ожидания") и оценка личности, деятельности или результатов деятельности другими людьми ("оценка").
Эмоциональный контекст деятельности описывается людьми не только через использование соответствующих собственно эмоциональных (радость, радостный, грусть, грустный), но и "общеоценочных" (хорошо, плохо) слов. Также эмоциональный контекст задается номинализациями, используемыми для называния других участников ситуации. Строго говоря, использование эмоциональных слов для описания ситуации (события) является следствием проекции и антропофикации самой ситуации (т.е. рассматривание ситуации как субъекта самой себя, типичная фраза "… ситуация развивалась сама по себе"), предметов, природных явлений и т.д., так или иначе считающихся важным говорящим для описания ситуации. Соответственно, для выявления эмоционального фона ситуации необходим учет следующих групп слов:
¨ общеоценочные слова (хорошо, плохо, тяжело и т.д.);
¨ прилагательные и номинализации, используемые для описания и оценки человека, включая наиболее распространенные метафоры;
¨ глаголы, описывающие эмоциональные реакции человека.
 |
В отличии от других мотивационных категорий, отнесение конкретного слова к той или иной категории весьма затруднительно по многозначности большинства слов описания "эмоций". Кроме того, для описания эмоций больше подходит не "категоризационная" схема описания, а "континуальная", т.е. не отнесение слова к той или иной смысловой категории, а определение значения слова на определенной смысловой шкале (как правило, биполярной, но не обязательно симметричной). В качестве таких "смысловых шкал" нами использовались 15 факторов, выделенных А.Г.Шмелевым и В.И.Похилько (1982-1988, программа ТЕЗАЛ). При такой подходе каждое слово оценивается по всем пятнадцати шкалам, а "эмоциональный" профиль деятельности задается оценкой участников, их переживаниями, ожиданиями и т.д.
В качестве примеров в таблице представлены слова, имеющие максимальные, минимальные значения по шкале ("пример полюса"), и слова, которые по данной шкале имеют "нулевые значения" (т.е. этот критерий к ним не применим). Использование факторной модели избавило нас от введения многочисленных категорий (по данным А.Г.Шмелева, их может быть не менее 112) и проблем, связанных с известным сравнением "умных" и "красивых".
| Смысловая шкала | Пример полюса (-) | Центр шкалы (0) | Пример полюса (+) |
| Доброжелательность | Злой, бесчеловечный | Говорун, конспиратор | Добрый, сердечный |
| Интеллект | Глупый, тупица | Отщепенец, филантроп | Думающий, просвещенный |
| Экстраверсия | Апатичный | Немилосердный, противный | Оживленный |
| Самоконтроль | Небрежный | Отчаянный, кровосос | Обязательный |
| Независимость | Слабый, тряпка | Жадина, циник | Сильный, боец |
| Агрессивность | Покладистый, спокойный | Безвольный, безгрешный | Невыдержанный |
| Практичность | Наивный | Бука, волокита | Опытный, практичный |
| Правдивость | Лгун | Бодрый, веселый | Незапятнанный, праведный |
| Доминантность | Соглашатель | Белоручка, бравый | Неуступчивый |
| Демонстративность | Непритязательный | Балбес, безграмотный | Избалованный, капризный |
| Деятельность | Волокитчик | Артистичный, бандит | Дельный, деловой |
| Скрытность | Раскрепощенный | Бесконфликтный, вор | Нелюдимый |
| Эгоизм | Непритязательный | Безудержный, ветренный | Гордец, самолюбивый |
| Утонченность | Наглый, невежливый | Безответственный, бродяга | Изысканный, музыкальный |
| Необычность | Типичный | Аккуратный, беспощадный | Необычный |
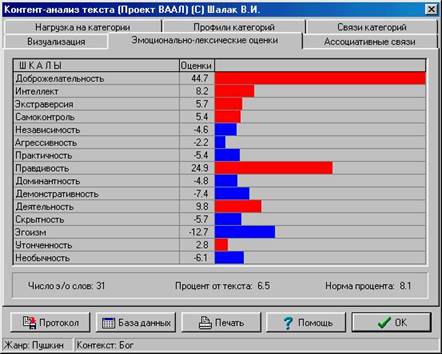
При анализе по факторам эмоциональной оценки появляется возможность определить основные критерии и значения по ним, применяемые автором текста.
Эмоционально-лексические оценки вычисляются путем подсчета средних величин по каждой из шкал. Если полученная оценка положительна, то строка гистограмм ыимеет красный цвет, если отрицательна - синий. В нижней части окна приведены:
¨ количество эмоционально-оценочных слов в тексте;
¨ процент эмоционально-оценочных слов от всех слов анализируемого текста;
¨ нормальный процент эмоционально-оценочных слов в русском языке/жанре.
Если вы хотите сохранить эмоционально-лексические оценки в файл для последующего использования, то нажмите кнопку < Протокол >. В появившемся окне вам необходимо указать имя файла. Если указано имя уже существующего файла, то данные добавляются в его конец. Для хранения протоколов по умолчанию используется специальная директория ...\VAAL\Protocol.
В ряде случаев возникает задача вторичной математической обработки эмоционально-лексических оценок. Для их сохранения и накопления Вы можете воспользоваться кнопкой < База данных >. При нажатии на нее вам будет предложено сохранить оценки в файле. Если указано имя уже существующего файла, то данные добавляются в его конец. Накопив в одном файле связи категорий, вы можете затем их подвергнуть либо факторному анализу с использованием модуля визуализации системы ВААЛ, либо более изощренным видам анализа с использованием таких известных систем как Statistica и SPSS. Файлы данных хранятся в специальной директории ...\VAAL\Data. Система сохраняет данные в файлах с расширением del. Вам не нужно беспокоиться о правильном расширении файла. Система сделает это за Вас.
Дополнительно Вы имеет возможность распечатать таблицу на принтере.
Ассоциативные связи
На странице приведена таблица слов, которые входят в анализируемый контекст.
Для каждого слова указаны следующие оценки:
n - частота слова в контексте;
n% = (n/длина контекста)*100;
N - частота слова во всем тексте;
N% = (N/длина всего текста)*100;
Z = (n-E)/(стандартное отклонение), где E - ожидаемое число появлений слова в
 |
ассоциативном контексте. Z - это традиционная оценка в контент-анализе, известная как z-score.
Список слов Вы можете упорядочить одним из четырех способов:
¨ лексикографически;
¨ по частоте n;
¨ по частоте N;
¨ по оценке Z..
Нажав на кнопку < Протокол >, Вы можете сохранить результаты анализа в текстовом файле протокола. Для этого достаточно всего лишь ввести имя нового протокола или выбрать уже существующий. В последнем случае данные будут дописаны в конец файла.
Также Вы можете распечатать таблицу на принтере.
Маркирование предложений
Иногда возникает необходимость найти в тексте и каким-либо образом выделить предложения, в которых встречаются слова некоторой категории. Это позволяет оценить контексты, в которых встречается данная категория. Система предлагает удобные средства для решения этой задачи. А именно, Вы можете:
¨ выбрать целевую категорию, слова которой должны быть выделены в тексте;
¨ указать, не менее скольки слов целевой категории должно встретиться в предложении для его выделения;
¨ выбрать шрифт с подчеркиванием;
¨ выбрать курсивный шрифт;
¨ выбрать жирный шрифт;
¨ изменить размер шрифта;
¨ установить разрядку между буквами слова;
¨ установить смещение слов относительно строки;
¨
 |
выбрать цвет выделения.
Возможна любая комбинация из перечисленных опций.
Маркирование слов категорий
 |
Иногда возникает необходимость найти в тексте и каким-либо образом выделить слова некоторой категории. Система предлагает удобные средства для решения этой задачи. А именно, Вы можете:
¨ выбрать целевую категорию, слова которой должны быть выделены в тексте;
¨ выбрать шрифт с подчеркиванием;
¨ выбрать курсивный шрифт;
¨ выбрать жирный шрифт;
¨ изменить размер шрифта;
¨ установить разрядку между буквами слова;
¨ установить смещение слов относительно строки;
¨ выбрать цвет выделения.
 |
Возможна любая комбинация из перечисленных опций.
Визуализация данных
Первая страница визуализации данных содержит:
- таблицу отображаемых данных;
- кнопки < Загрузить >, < Сохранить >, < Помощь > и < Выход >.
Прежде всего необходимо загрузить данные. Для этого нажмите на кнопку < Загрузить >. В открывшемся диалоговом окне выберите тип файла данных, которые Вас интересуют, и затем уже выберите нужный файл.
Операции с таблицей данных
1. Редактирование ячейки данных.
Для того, чтобы отредактировать ячейку данных, установите на ней фокус ввода (серая рамка) и щелкните мышью или нажмите на клавишу < Enter >. После этого введите с клавиатуры необходимые данные и опять нажмите на клавишу < Enter >. Обращаем внимание на то, что разделителем между целой и дробной частью является точка <. >. Редактирование просиходит лишь в таблице, но не в файле данных на диске. Чтобы сохранить изменения в файле, нажмите кнопку < Сохранить >.
 |
2. Выделение столбца.
Выделены могут быть лишь те (кроме первого) столбцы, все ячейки которых содержат числовые данные. Для этого нажмите на клавишу < Ctrl > и, удерживая ее, щелкните мышью по первой (серой) ячейке столбца. Повторная операция приводит к снятию выделения данного столбца.
3. Выделение строки.
Выделена может быть любая (кроме первой) строка. Для этого нажмите на клавишу < Ctrl > и, удерживая ее, щелкните мышью по первой (серой) ячейке строки. Повторная операция приводит к снятию выделения данной строки.
4. Снятие выделения сразу со всех строк и столбцов.
В любом месте таблицы данных сделайте двойной щелчок мышью.
5. Удаление строк.
Выделите строки, которые должны быть удалены. Нажмите правую кнопку мыши. В появившемся меню выберите пункт < Удалить выделенные строки >. Строки удаляются лишь в таблице, но не в файле данных на диске. Чтобы сохранить изменения в файле, нажмите кнопку < Сохранить >.
Пользователь имеет возожность:
¨ провести факторный анализ данных;
¨ провести корреляционный анализ данных;
¨ отобразить данные в виде различных диаграмм.
Для этого выделите те столбцы данных, которые должны участовать в анализе, и перейдите на одну из других страниц окна < Факторный анализ >, < Корреляционный анализ >, < Диаграммы >.
Факторный анализ
 |
Тексты и слова оценивают сразу по многим параметрам, котррые трудно охватить одним взглядом, чтобы сказать насколько похожи или насколько отличаются друг от друга эити слова и тексты. Факторный анализ данных позволяет не только уменьшить размерность пространства признаков, но и выявить среди них наиболее информативные.
В системе ВААЛ производится сведение пространства признаков к трем наиболее информативным факторам. Это позволяет достаточно наглядно визуализировать результаты анализа в псевдо-трехмерном пространстве.
Справа в таблице находятся пронумерованные имена из первого столбца таблицы данных. Слева на фоне темно-серого квадрата нарисованы цифры, обведенные окружностями. Каждая цифра соответствует номеру имени. Визуализация производится в псевдо-трехмерном пространстве. Диаметр окружности вокруг цифры соответствует степени близости к Вам.
Кнопки слева внизу позволяют Вам производить вращение в пространстве. Это позволяет более интуитивно представить взаиморасположение имен в пространстве. Скорость вращения можно регулировать. Три левых крайних кнопки соответствуют трем фиксированным проекциям в двумерное пространство.
Вы имеете возможность распечатать результаты факторного анализа на принтере.
Факторизация производится методом центроидов. Более подробная информация о методе факторного анализа и его практическом применении содержится в специальной литературе.
Корреляционный анализ
 |
Так как слова и тексты оцениваются сразу по многим параметрам, то бывает трудно охватить и осмыслить существующие между ними связи. Существуют два выхода из этой ситуации. Первый - сохранить результаты в Базу данных и затем проанализировать их с помощью одного из статистических пакетов. Второй - произвести непосредственную визуализацию связей.
Идея визуализации заключается в следующем. Возьмем произвольную строку из таблицы данных и назовем ее (горизонтальной) осью X. Вычислив корреляционные связи этой строки со всеми остальными, мы получим некоторые координаты от -1 до +1 этих строк на оси X. Возьмем теперь другую строку и назовем ее (вертикальной) осью Y. Вычислим корреляционные связи второй строки со всеми остальными и получим их координаты на оси Y.
Итак, мы получили координаты всех строк в некотором двухмерном пространстве. Осталось их отобразить. Именно это и делается на странице визуализации.
Справа вверху имеются две строки с именами строк из первого столбца таблицы, обозначенные буквами X и Y. Это две условных координатных оси. Имена легко изменить, выбрав их из выпадающих вниз списков.
Ниже находится список пронумерованных имен из первого столбца таблицы.
Слева на фоне темно-серого квадрата изображены цифры, обведенные окружностями. Каждая цифра соответствует номеру имени. Визуализация производится в двухмерном пространстве.
Пользователь имеет возможность указать системе на то, чтобы она отображала лишь некоторые имена. Для этого достаточно поставить галочку в квадратике слева от интересующего имени. Двойной щелчок мыши позволяет изменить отмеченность всех имен на противоположную.
Дополнительно Вы имеет возможность распечатать пространственное отображение имен на принтере.
Диаграммы
Страница содержит:
¨ список имен выделенных столбцов;
¨ поле ввода степени аппроксимирующего полинома;
¨ диаграмму;
¨ кнопки < Параметры >, < Печать >, < Помощь > и < Выход >.
 |
В списке имен выделенных столбцов Вы можете выбрать тот, диаграмма которого Вас интересует.
Если анализируемые данные упорядочены во времени, то интерес представляет их аппроксимация полиномами различных степеней. Изменить степень полинома можно нажимая мышкой на стрелки вверх (увеличить) и вниз (уменьшить).
Параметры диаграммы и линии тренда всегда можно изменить, нажав на кнопку < Параметры >.
Дополнительно Вы имеете возможность распечатать диаграмму на принтере.
Параметры диаграмм
В данном окне Вы можете отдельно задать параметры как самой диаграммы, так и линии тренда. Для этого достаточно лишь установить требуемую комбинацию переключателей и нажать кнопку < Принять >.
 |
Параметры печати
Вы имеете возможность выбрать следующие параметры печати:
¨ шрифт;
¨ размер шрифта;
¨ стиль шрифта;
¨
 |
поля отступа на странице;
¨ межстрочного интервал.
Изменение параметров отображается на панели образца.
Кнопки
¨ < Помощь > - вызов контекстной справки
¨ < Принять > - начало печати с выбранными параметрами
¨ < Отказ > - отказ от печати
Темы
В каждом тексте присутствуют, как правило, от одной до нескольких тем. На определенном уровне абстракции каждая тема может быть представлена набором ключевых слов.
Система ВААЛ позволяет выделять ключевые слова анализируемого текста и ключевые слова представленных в тексте тем. На основе выделенных слов могут быть сформированы категории, которые позволят применить к тексту метод контекстного контент-анализа.
Параметры выделения тем
Окно задания параметров содержит:
¨ список категорий исключений
¨ список доступных частотных словарей
¨ кнопки < Принять >, < Помощь > и < Отказ >
 |
Категория исключений - это список слов, которые не включаются в анализ. В области автоматической обработки текстов такие слова еще иногда называют стоп-словами. Как правило к ним относят частицы, предлоги, союзы и другие служебные слова.
Если частотный словарь не указан, то ключевыми словами данного текста считаются первые 500 наиболее частотных слов текста с частотой не менее 4.
Если частотный словарь указан, то ключевыми словами данного текста считаются первые 500 наиболее частотных слов текста с частотой не менее 4, которая с вероятностью не менее 0.99 не случайно превосходит частоту этого же слова в выбранном словаре. Т.е. мы берем из частотного словаря норму встречаемости данного слова, подсчитываем для анализируемого текста ожидаемую частоту встречаемости данного слова и сравниваем ее с фактической частотой. Если фактическая частота превосходит 4, превосходит ожидаемую частоту и это отличие от ожидаемой частоты с вероятностью 0.99 не случайно, то данное слово заносится в список ключевых слов анализируемого текста.
Для правильного выбора параметров необходимо их понимание.
Ключевые слова
Страница содержит:
¨ список ключевых слов анализируемого текста;
¨ переключатель типа упорядочения ключевых слов;
¨ мусорную корзину;
¨ кнопки < Общая категория >, < Выделение тем >, < Помощь > и <Выход>.
 |
В списке ключевых слов последние три столбика содержат статистическиме характеристики ключевых слов. В столбике, обозначенном F, указана частота слова в частотном словаре. В столбике f - частота слова в тексте. В столбике Z указана оценка слова, вычисляемая по формуле Z = (f-E)/(стандартное отклонение), где E - ожидаемое число появлений слова в анализируемом тексте. Z - это традиционная оценка в контент-анализе, известная как z-score.
Список ключевых слов может быть упорядочен одним из семи способов. Для этого достаточно соответствующим образом установить переключатель.
Если по Вашему мнению некоторые слова попали в число ключевых неправильно, Вы можете их удалить перетащив мышью в мусорную корзину.
Ключевые слова репрезентируют весь текст в целом. Это особенно верно, если при выборе параметров выделения тем был указан подходящий частотный словарь. Нажав на кнопку <Общая категория>, Вы можете сформировать простую категорию, состоящую из всех ключевых слов.
Чтобы выделить присутствующие в тексте темы, следует нажать на кнопку < Выделение тем >.
Темы в тексте
Страница содержит:
¨ многострочное поле редактирования тем
¨ поле диапазона контекста
¨ поле значимости связи
¨ кнопки < Пересчет тем >, < Категория 1 >, < Категория n >, < Сохранить темы >, < Печать >, < Помощь > и < Выход >.
 |
Поле редактирования тем содержит список всех обнаруженных тем. Темы отделены друг от друга пустой строкой. Каждая тема - это некоторый набор слов, состоящий из главного слова и сильно связанных с ним подчиненных слов. Главное слово в теме стоит на первом месте. Тема не может состоять менее чем из двух слов. При желании темы могут быть Вами отредактированы.
Поле диапазона контекста служит для указания того, как близко должны отстоять в тексте подчиненные слова темы от главного слова. Очевидно, что минимальным может быть расстояние в 1, а в качестве максимального принято расстояние 100. При этом под расстоянием понимается разница номеров позиций слова в тексте. Увеличение контекста в общем случае ведет к укрупнению тем и уменьшению их количества.
Поле значимости связи служит для указания критерия, с какой вероятностью можно утверждать, что связь между главным словом темы и подчиненными не является случайной. Принято, что минимальным может быть значение 0.9, а максимальным - 0.99999. Увеличение значимости связи в общем случае ведет к уменьшению размера тем и к уменьшению их количества.
Изменив диапазон контекста или значимость связи, Вы можете дать команду пересчитать темы для новых параметров. Для этого достаточно нажать на кнопку < Пересчет тем >.
На основании выделенных тем могут быть сформированы сложные категории. Возможны два варианта:
¨ формирование сложной категории на основании отдельной темы;
¨ формирование сложной категории на основании сразу всех тем.
В первом случае для этого требуется установить курсор на соответствующую тему и после этого нажать на кнопку < Категория 1 >. В результате будет сформирована сложная категория формата:
d:U:<главное_слово_темы>,<подчиненное_слово_1>
...
d:U:<главное_слово_темы>,<подчиненное_слово_k>
Во втором случае для этого требуется просто нажать на кнопку < Категория n >. В результате будет сформирована сложная категория формата:
d:U:<главное_слово_темы_1>,<подчиненное_слово_1>
...
d:U:<главное_слово_темы_1>,<подчиненное_слово_k1>
...
...
...
d:U:<главное_слово_темы_n>,<подчиненное_слово_1>
...
d:U:<главное_слово_темы_n>,<подчиненное_слово_kn>
Также Вы имеете возможность сохранить темы в файл и распечатать их на принтере.
АВТОРЫ
В системе ВААЛ использованы научные результаты следующих авторов:
1. Белянин Валерий Павлович, доктор филологических наук, профессор МГУ, член международных научных организаций (МАПРЯЛ, ISAPL, AAASS).
E-mail: vbelyanin@usa.net
2. Дымшиц Михаил, генеральный директор консультационной фирмы "ДЫМШИЦ и ПАРТНЕРЫ"
E-mail: dmsh@online.ru
3. Шалак Владимир Иванович, кандидат философских наук, старший научный сотрудник Института философии РАН.
E-mail: shalack@mail.ru
Дополнительную информацию о системе ВААЛ Вы можете получить в Интернете на сайте http://www.vaal.ru/.
| <== предыдущая лекция | | | следующая лекция ==> |
| Маршрут похода и график движения | | | Клавиша «Esc». Читается как «Эскейп». |
Не нашли, что искали? Воспользуйтесь поиском: