ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Представление списков в виде БД
Списки и деревья – это наиболее часто используемые динамические структуры данных. Покажем, как может повыситься эффективность решения поставленной задачи, если применять эти структуры сообща для достижения поставленной цели. Рассмотрим задачу нахождения к -ого элемента списка, используя дерево. Значение в узле дерева – это количество элементов в левом поддереве данного узла.
Элементы исходного списка представляются листьями дерева, а узлы, не являющиеся листьями, представляются как часть внутренней структуры дерева. С каждым узлом связан счетчик числа листьев в левом поддереве. Элементы списка присваиваются листьям дерева в порядке симметричного просмотра.
В каждом узле р, не являющемся листом, алгоритм определяет по значениям r и ListCount(p), находится ли нужный лист в левом или в правом поддереве. Если лист в левом поддереве, то поиск ведется по этому поддереву без изменения значения r, а если в правом, то перед поиском по этому поддереву значение r уменьшается на ListCount(p). Рассмотрим реализацию изложенного способа на примере. Пусть дан список элементов (рис. 21). На рис. 22.а и 22.б приведены два дерева, удовлетворяющие требованиям алгоритма.

Рис. 21 – Список элементов для поиска

Рис. 22.а – Первый вариант дерева с элементами списка

Рис. 22.б – Второй вариант дерева с элементами списка
Код алгоритма нахождения к -ого элемента списка

Здесь Tree – указатель на корень дерева; ListCount(p) – счетчик числа листьев, связанных с узлом, на который указывает рабочий указатель р; r – рабочая переменная; Find – указатель найденного элемента; Left(p) и Right(p) – указатели на левого и правого сыновей текущего узла.
Эффективность поиска с помощью данного алгоритма растет с увеличением числа элементов списка. Для 1000 элементов достаточно 10 сравнений.
Прошитые БД
Эффективность прохождения дерева рекурсивными и нерекурсивными алгоритмами может быть увеличена, если использовать пустые указатели на отсутствующие поддеревья для хранения в них адресов узлов преемников, которые надо посетить при заданном порядке прохождения БД. Такой указатель называется нитью. Его следует отличать, например, с помощью отрицательных значений, от указателей в дереве, которые используются с левым и правым поддеревьями. Операция, заменяющая пустые указатели на нити, называется прошивка. Она может выполняться по-разному. Если нити заменяют пустые указатели в узлах с пустыми правыми поддеревьями, при просмотре в симметричном порядке, то БД называется симметрично прошитым справа. Абсолютная величина отрицательного значения нити узла Р есть индекс узла, являющегося преемником узла Р при просмотре в симметричном порядке. Похожим образом может быть определено БД, симметрично прошитое слева: дерево, в котором каждый пустой левый указатель изменен так, что он содержит нить – связь к предшественнику данного узла при просмотре в симметричном порядке. Симметрично прошитое БД – БД, которое симметрично прошито слева и справа. Однако БД, симметрично прошитое слева, не дает тех преимуществ, что БД, симметрично прошитое справа. На рис. 23 показано БД, симметрично прошитым справа. На нем пунктирными линиями обозначены прошивочные нити.
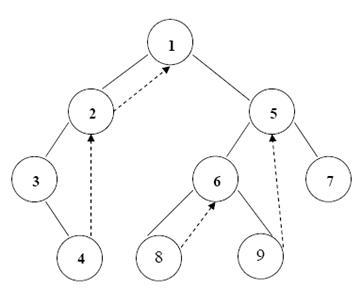
Рис. 23 – Симметрично прошитое справа БД
Также используются БД, прямо прошитые слева и справа. В них пустые правые и левые указатели узлов заменены соответственно на их преемников и предшественников при прямом порядке просмотра. Прошитые БД эффективно проходятся без использования стека.
Наряду с преимуществами прошитых деревьев: быстрый обход, отсутствие необходимости в стеке, можно определить предшественника и приемника вершины, существуют недостатки. Включение новой вершины в дерево занимает больше времени, т.к. необходимо поддерживать два типа связей: структурные и по нитям.
Рассмотрим вставку новой вершины слева от заданной в симметрично прошитое БД (рис. 24). На рис. 25 показано результирующее БД.

Рис. 24 – Исходное симметрично прошитое БД
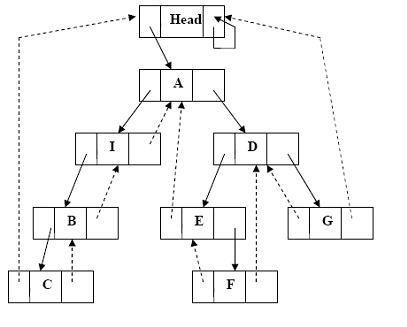
Рис. 25 – Прошитое дерево после вставки в него нового элемента
Здесь требовалось вставить вершину I вкачестве левого поддерева вершины А, если А не имеет левого поддерева. В противном случае новая вершина вставляется между А и ее левым сыном.
Для удобства создания и обхода дерева используется дополнительная головная вершина Head, которая служит при симметричном обходе предшественником его первой вершины и приемником всех его концевых вершин.
Лекция 10
План лекции:
1. Применение деревьев. Представление сообщений кодами Хаффмана.
Не нашли, что искали? Воспользуйтесь поиском: