ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Понятие об ООП. Отличие ООП подхода к программированию от структурного.
Концепция объектно-ориентированного программирования складывается из 3 ключевых понятий: абстракция данных, наследование и полиморфизм.
Абстракция данных позволяет инкапсулировать множество объектов данных
24. Инкапсуляция (encapsulation) - это механизм, который объединяет данные и код, манипулирующий зтими данными, а также защищает и то, и другое от внешнего вмешательства или неправильного использования.
25. Наследование (inheritance) - это процесс, посредством которого один объект может приобретать свойства другого.
26. Полиморфизм (polymorphism) (от греческого polymorphos) - это свойство, которое позволяет одно и то же имя использовать для решения двух или более схожих, но технически разных задач.
27. Основные требования к организации БД
1. Установление многосторонних связей.
2. Производительность.
3. Минимальные затраты.
4. Минимальная избыточность.
5. Возможности поиска.
6. Целостность.
Необходимо учитывать возможность возникновения ошибок и различного рода случайных сбоев. Хранение данных, их обновление, процедуры включения данных должны быть такими, чтобы система в случае возникновения сбоев могла восстанавливать данные без потерь.
7. Безопасность и секретность.
Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это право, от неавторизованной модификации данных или их уничтожения.
Секретность определяют как право отдельных лиц или организаций определять, когда, как и какое количество соответствующей информации может быть передано другим лицам или организациям.
Основные положения, особенно важные с точки зрения обеспечения безопасности данных в базе данных:
данные защищаются от искажения, хищения и других форм уничтожения,
данные должны быть восстанавливаемыми,
обеспечивается возможность контроля данных,
система недоступна для вмешательства в неё,
должна быть установлена процедура идентификации пользователя базы данных,
в системе предусматривается контроль действий пользователя по обработке данных с точки зрения санкционирования их выполнения,
контроль за работой пользователя осуществляется так, чтобы его ошибочные действия были с большой вероятностью обнаружены.
Вопросы обеспечения секретности данных и их безопасности принципиально тесно связаны между собой.
8. Связь с прошлым.
9. Связь с будущим.
Должны существовать три отдельных представления организации базы данных:
1). Физическое представление,
2). Общее логическое представление базы данных,
3). Представление данных в отдельных прикладных программах.
10. Настройка.
Реконструкция базы данных с целью улучшения её производительности называется настройкой базы данных. Эффективность настройки определяется двумя требованиями:
1). Физической независимости данных,
2). Автоматического управления базами данных, обеспечивающего возможность выполнения требуемой настройки.
11. Перемещение данных.
Процесс регулирования хранения данных в соответствии с уровнем спроса на них называется перемещением данных. Иногда эта операция являетсячастью процесса настройки базы данных. В некоторых системах перемещение выполняется автоматически.
12. Простота.
Средства, которые используются для представления общего логического описания данных, должны быть простыми.
28. Назначение и основные компоненты системы баз данных
Система БД включает два основных компонента: собственно базу данных и систему управления (рис. 1.3). Большинство СОД включают также программы обработки данных, которые обращаются к данным через систему управления.
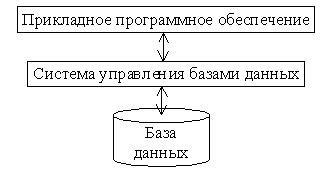
Рис.1.3. Компоненты системы баз данных
В соответствии с рис. 1.3. система управления базами данных (СУБД) обеспечивает выполнение двух групп функций: предоставление доступа к базе данных пользователям (или прикладному программному обеспечению, ППО) и управление хранением и обработкой данных в БД.
БД является информационной моделью внешнего мира, некоторой предметной области. В ней, как правило, хранятся данные об объектах, их свойствах и характеристиках. Во внешнем мире объекты взаимосвязаны, поэтому в БД эти связи должны быть отражены. Если связи между данными в БД отсутствуют, то имеет смысл говорить о нескольких независимых БД, имеющих раздельное хранение.
В памяти ЭВМ создаётся динамически обновляемая модель предметной области, что обеспечивает соответствие базы данных текущему состоянию ПО (периодически или в режиме реального времени). Одни и те же данные БД могут быть использованы для решения многих прикладных задач. Этим база данных принципиально отличается от любой другой совокупности данных внешней памяти ЭВМ.
29. Этапы проектирования баз данных
Этап 1. Уточнение задач
На первом этапе составляется список всех основных задач, которые в принципе должны решаться этим приложением, - включая и те, которые не нужны сегодня, но могут появиться в будущем. Под "основными" задачами понимаются функции, которые должны быть представлены в формах или отчетах приложения.
Этап 2. Последовательность выполнения задач
Для того, чтобы приложение работало логично и удобно, лучше всего объединить основные задачи в тематические группы и затем упорядочить задачи каждой группы так, чтобы они располагались в порядке их выполнения. Может получиться так, что некоторые задачи будут связаны с разными группами или, что выполнение некоторой задачи должно предшествовать выполнению другой, принадлежащей к иной группе.
Этап 3. Анализ данных
После формирования списка задач, наиболее важным этапом является составление подробного перечня всех данных, необходимых для решения каждой задачи. Некоторые данные понадобятся в качестве исходных и меняться не будут. Другие данные будут проверяться и изменяться в ходе выполнения задачи. Некоторые элементы данных могут быть удалены или добавлены. И наконец, некоторые данные будут получены с помощью вычислений: их вывод будет частью задачи, но в базу данных вноситься они не будут.
Этап 4. Определение структуры данных
После предварительного анализа всех необходимых элементов данных нужно упорядочить их по объектам и соотнести объекты с таблицами и запросами базы данных. Для реляционных баз данных типа Access используется процесс, называемый нормализацией, в результате которого вырабатывается наиболее эффективный и гибкий способ хранения данных.
Этап 5. Разработка макета приложения и пользовательского интерфейса
После задания структуры таблиц приложения, в Microsoft Access легко создать его макет с помощью форм и связать их между собой, используя несложные макросы или процедуры обработки событий. Предварительный рабочий макет легко продемонстрировать заказчику и получить его одобрение еще до детальной реализации задач приложения.
Этап 6. Создание приложения
В случае очень простых задач созданный макет является практически законченным приложением. Однако довольно часто приходится писать процедуры, позволяющие полностью автоматизировать решение всех намеченных в проекте задач. Поэтому, понадобится создать специальные связующие формы, которые обеспечивают переход от одной задачи к другой.
Этап 7. Тестирование и усовершенствование
После завершения работ по отдельным компонентам приложения необходимо проверить функционирование приложения в каждом из возможных режимов. Необходимо проверить работу макросов, для этого использовав пошаговый режим отладки, при котором будет выполняться одна конкретная макрокоманда. При использовании Visual Basic для приложений в вашем распоряжении имеются разнообразные средства отладки, позволяющие проверить работу приложения, выявить и исправить ошибки.
По мере разработки автономных разделов приложения желательно передать их заказчику для проверки их функционирования и получения мнения о необходимости внесения тех или иных изменений. После того как заказчик ознакомится с работой приложения, у него практически всегда возникают дополнительные предложения по усовершенствованию, какой бы тщательной не была предварительная проработка проекта. Пользователи часто обнаруживают, что некоторые моменты, о которых в процессе постановки задач, они говорили как об очень важных и необходимых, на самом деле не играют существенной роли при практическом использовании приложения. Выявление необходимых изменений на ранних стадиях разработки приложения позволяет существенно сократить время на последующие переделки.
30. Модель данных – это совокупность структур данных и операций их обработки.
Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области. Они содержат информацию о классах объектов, их свойствах и взаимосвязях, описания структур данных без привязки к какой-либо конкретной СУБД. Инфологические (или семантические) модели отражают в естественной и удобной для разработчиков и других пользователей форме информацию о предметной области в процессе разработки структуры будущей базы данных.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных списков. Кроме того, современные СУБД широко используют страничную организацию данных. В этом случае база данных представлена минимальным количеством файлов, а задачи поиска, чтения и записи данных выполняет сама СУБД, а не операционная система. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, ориентированные на формат документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Гораздо более простой и удобный, чем SGML, язык HTML (HyperText Markup Language – язык разметки гипертекста) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. В настоящее время все большую популярность приобретает язык XML (eXtensible Markup Language – расширяемый язык разметки), позволяющий описывать документы произвольной структуры и содержания.
Тезаурусные модели основаны на принципе организации словарей. Они содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескриптпорные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базе данных. Например, для БД, содержащей описание патентов, дескриптор содержит название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных ведется исключительно по дескрипторам, то есть по тем параметрам, которые характеризуют патент, а не по самому тексту патента.
Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов. Реляционная модель будет подробно рассмотрена далее.
Модели возможно не правильные.
Не нашли, что искали? Воспользуйтесь поиском: