ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Организация данных в файлах
Будем рассматривать файл как последовательность записей, причем каждая запись состоит из одной и той же совокупности полей. Поля могут иметь либо фиксированную, либо переменную длину.
В языке Паскаль предусмотрена работа с файлами, чьи записи имеют фиксированную длину. Они широко используются в системах управления базами данных для хранения данных сл сложной структурой. Наиболее часто для работы с файлами применяются следующие операторы.
1. INSERT вставляет определенную запись в определенный файл.
2. DELETE удаляет из определенного файла все записи, содержащие указанные значения в указанных полях.
3. MODIFY изменяет все записи в определенном файле, задав указанные значения определенным полям в тех записях, которые содержат указанные значения в других полях.
4. RETRIEVE отыскивает все записи, содержащие указанные значения в указанных полях.
Простейшим способом реализации перечисленных операторов работы с файлами является следующая. Поиск записи с указанными значениями в определенных полях осуществляется путем полного просмотра файла и проверки каждой его записи на наличие в ней заданных значений. Вставку в файл можно выполнить путем присоединения соответствующей записи к концу файла. В случае изменения записей необходимо просмотреть файл, проверить каждую запись и решить, соответствует ли она заданным условиям. Если соответствует, в запись вносятся требуемые изменения. В случае операции удаления ищутся записи, чьи поля соответствуют условиям удаления, а затем выбирается способ удаления требуемых записей.
Очевидным недостатком последовательного файла является то, что операторы с такими файлами выполняются медленно, т.к. выполнение каждой операции требует прочтения всего файла, а затем еще и выполнения перезаписи некоторых блоков. Однако существуют способы организации файлов, которые позволяют обращаться к записи, считывая в основную память лишь небольшую часть файла.
Такие способы организации файлов предусматривают наличие у каждой записи ключа, т.е. совокупности полей, которая уникальным образом идентифицирует каждую запись. Поиск записи, когда заданы значения ее ключевых полей, является типичной операцией. Еще одним непременным атрибутом быстрого выполнения операцией с файлами является возможность непосредственного доступа к блокам. Рассмотрим несколько способов ускорения операций с файлами.
Хешированные файлы
Хеширование – распространенный метод обеспечения быстрого доступа к информации, хранящейся во вторичной памяти. Основная идея этого метода подобна открытому хешированию, рассмотренному ранее. Записи файла распределяются между сегментами, каждый из которых состоит из связного списка одного или нескольких блоков внешней памяти.
Имеется таблица сегментов, содержащая В указателей, – по одному на каждый сегмент. Каждый указатель в таблице сегментов представляет собой физический адрес первого блока связного списка блоков для соответствующего сегмента. Сегменты пронумерованы от 1 до В. Хеш-функция h отображает каждое значение ключа в одно из целых чисел от 1 до В. Если х – ключ, то h(x) является номером сегмента, который содержит запись с ключом х, если такая запись вообще существует. Блоки, составляющие каждый сегмент, образуют связный список. Таким образом, заголовок i -ого блока содержит указатель на физический адрес (i +1)-ого блока. Последний блок сегмента содержит в своем заголовке nil -указатель. Такой способ организации показан на рис. 50. При этом в данном случае элементы, хранящиеся в одном блоке сегмента, не требуется связывать друг с другом с помощью указателей, связывать между собой нужно только блоки.
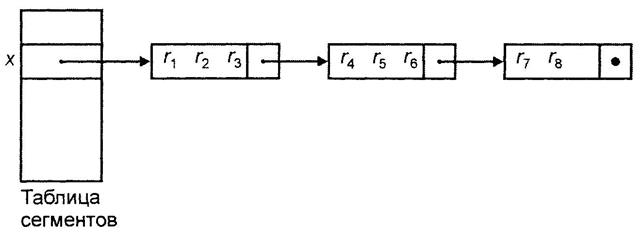
Рис. 50 – Сегменты, состоящие из связанных блоков
Если размер таблицы сегментов невелик, ее можно хранить в основной памяти, иначе ее можно хранить последовательным способом в отдельных блоках. Если требуется найти запись с ключом х, вычисляется h(x) и находится блок таблицы сегментов, содержащий указатель на первый блок сегмента h(x). Затем последовательно считываются блоки сегмента h(x), пока не обнаружится блок, содержащий запись с ключом х. Если исчерпаны все блоки в связном списке для сегмента h(x), делается вывод, что х не является ключом ни одной из записей.
Такая структура оказывается эффективной, если в выполняемом операторе указываются значения ключевых полей. Среднее количество обращений к блокам, требующееся для выполнения оператора, в котором указан ключ записи, приблизительно равняется среднему количеству блоков в сегменте, которое равно n/bk, если n – количество записей, блок содержит b записей, а k соответствует количеству сегментов. В результате, при такой организации данных операторы, использующие значения ключей, выполняются в среднем в к раз быстрее, чем в случае неорганизованного файла.
Чтобы вставить запись с ключом, значение которого равняется х, нужно сначала проверить, нет ли в файле записи с таким значением ключа. Если такая запись есть, то выдается сообщение об ошибке, поскольку предполагается, что ключ уникальным образом идентифицирует каждую запись. Если записи с ключом х нет, новая запись вставляется в первый блок цепочки для сегмента h(x), в который ее удается вставить. Если запись не удается вставить ни в один из существующих блоков сегмента h(x), файловой системе выдается команда найти новый блок, в который будет помещена эта запись. Затем новый блок добавляется в конец цепочки блоков сегмента h(x).
Для удаления записи с ключом х, требуется сначала найти эту запись, а затем установить ее бит удаления.
Удачная организация файлов с хешированным доступом требует лишь незначительного числа обращений к блокам при выполнении каждой операции с файлами. Если выбрана удачная функция хеширования, а количество сегментов приблизительно равно количеству записей в файле, деленному на количество записей, которые могут поместиться в одном блоке, тогда средний сегмент состоит из одного блока. Если не учитывать обращения к блокам, которые требуются для просмотра таблицы сегментов, типичная операция поиска данных, основанного на ключах, потребует одного обращения к блоку, а операция вставки, удаления или изменения потребуют двух обращений к блокам. Если среднее количество записей в сегменте намного превосходит количество записей, которые могут поместиться в одном блоке, можно периодически реорганизовывать таблицу сегментов, удваивая количество сегментов и деля каждый сегмент на две части.
Не нашли, что искали? Воспользуйтесь поиском: