ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Экономические интеллектуальные информационные системы
2.4.1 Общие понятия интеллектуальных информационных систем
Искусственный интеллект (ИИ) – область, которая изучает интеллектуальное поведение людей, используя инструментальные средства –теоретические и экспериментальные – информатики. Данная область выступает в качестве связующего звена между одной из наиболее глубоких научных проблем, такой как природа интеллекта, и прагматическими разработками интеллектуальных систем.
Искусственный интеллект – это научные и практические вопросы, связанные с постановкой и решением задач аппаратного и программного моделирования тех видов человеческой деятельности, которые традиционно считаются интеллектуальными (творческими).
Интеллектуальная информационная система – это система обработки информации, способная решать задачи, считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти интеллектуальной системы.
Системы искусственного интеллекта ориентированы в основном на решение большого класса задач, называемых неформализуемыми (трудно формализуемыми), к которым относят задачи, обладающие одной или несколькими из следующих особенностей:
– алгоритмическое решение задачи неизвестно или не может быть использовано из-за ограниченности ресурсов;
– задача не может быть определена в числовой форме и ей требуется символьное представление;
– цели решения задачи не могут быть выражены в терминах точно определённой функции;
– большая размерность пространства решения;
– динамически изменяющие данные и знания о предметной области, которые обладают неполнотой, неоднозначностью и/или противоречивостью.
Существенными чертами интеллектуальной информационной системы является наличие знаний, способности логического вывода и системы управления знаниями. Способность производить выводы основывается на знаниях, причём знания различаются по форме, начиная от простых фактов, хранящихся в обычной базе данных, до сложных высказываний о реальном или моделируемом мире.
С точки зрения искусственного интеллекта знания можно определить как формализованную информацию, которая используется в логическом выводе в процессе решения задачи.
Знания в отличие от данных хранятся не в базах данных, а в базах знаний. Базу знаний можно определить как совокупность знаний, которые описаны с использованием выбранной формы их представления.
Типичными моделями представления знаний являются следующие:
– логические модели;
– продукционные модели;
– семантические сети;
– фреймовые модели.
В интеллектуальных информационных системах используют следующие основные технологии обработки данных:
– технологии, основанные на использовании нечёткой логики;
– нейронные сети;
– генетические алгоритмы.
2.4.2 Обзор моделей представления знаний
2.4.2.1 Логические модели
В основе построения логических моделей представления знаний лежит идея о том, что вся информация, необходимая для решения прикладных задач, рассматривается как совокупность фактов и утверждений, которые представляются как формулы в некоторой логике. Совокупность таких формул отображает имеющиеся знания, а получение новых знаний сводится к реализации процедур логического вывода.
Основой логических моделей является классический аппарат математической логики. Однако человеческая логика не укладывается в рамки классической логики и в этом случае при работе с неструктурированными знаниями применяется модель с нечёткой структурой.
Важной особенностью логических моделей является также то, что в базах знаний можно хранить лишь множество аксиом, а все остальные знания можно получать из хранящихся с использованием правил вывода.
2.4.2.2 Продукционные модели
Психологические исследования процессов принятия решений человеком показали, что рассуждая и принимая решения, человек использует правила продукций или продукционные правила. Ньюэлл и Саймон были первыми исследователями в области искусственного интеллекта, предложившими схему, известную как набор порождающих (продукционных) правил. Эти правила называют также правилами «условие – действие» или «ситуация – действие». Это связано с тем, что такие правила обычно используются для представления эмпирических ассоциативных связей между данными, предъявляемыми системе, и действиями, которые система должна предпринять в ответ.
В экспертных системах такие правила обычно задают, что нужно сделать с символической структурой, представляющей текущее состояние проблемы, чтобы перейти к представлению, более близкому к решению. Структурированная совокупность таких правил в теории искусственного интеллекта называется продукционной моделью представления знаний.
Основная идея продукционной модели заключается в ассоциировании с соответствующими действиями набора условий в виде правил типа «если-то» называемых также продукциями, которые можно представить в виде:
ЕСЛИ условие y1 удовлетворяется с истинностью x1 и … и условие m с истинностью xm,
ТО прийти к заключению1 со степенью уверенности z1 и … и заключениюm со степенью уверенности zn.
Здесь степень уверенности, связанная с каждым заключением, является функцией от оценок истинности соблюдения условий и уровня соответствия, отражающего степень уверенности эксперта при формулировке первичных правил.
Каждое продукционное правило является самостоятельным элементом знаний и отдельные правила могут быть связаны между собой только при их обработке. Поэтому правила в базу знаний могут быть добавлены, удалены или изменены независимо от других, но только при условии поддержания их взаимной непротиворечивости.
Продукционные модели близки к логическим моделям и чаще всего применяются в промышленных экспертных системах. Эти модели отличаются своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений, а также простотой логического вывода.
2.4.2.3 Семантические модели
В основе этих моделей лежит понятие сети, образованной помеченными вершинами и дугами. Вершины сети представляют некоторые сущности (объекты, события, процессы, явления), а дуги-отношения между сущностями, которые они связывают. Наложив ограничения на описание вершин и дуг, можно получить сети различного вида. Если вершины не имеют собственной внутренней структуры, то соответствующие сети называют простыми сетями. Если вершины обладают некоторой структурой, то такие сети называют иерархическими сетями. На начальном этапе разработки интеллектуальных систем использовались только простые сети, сейчас в большинстве приложений, использующих семантические сети, они являются иерархическими.
В зависимости от типов связей или дуг различают:
– классифицирующие сети, в которых дуги представляют собой отношения структуризации, позволяющие строить различные иерархии в структуре базы знаний;
– функциональные сети, в которых связями являются функциональные отношения, позволяющие описывать процедуры вычислений одних информационных единиц через другие;
– сценарии, в которых дуги отражают причинно-следственные отношения, а также отношения типов «средство – результат», «орудие – действие» и т.д.
Наличие нескольких типов связей в одной сетевой модели позволяет называть её семантической сетью. Семантическая сеть – это модель, основой для которой является формализация знаний в виде ориентированного графа с размеченными вершинами и дугами. Вершинам соответствуют объекты, понятия или ситуации, а дугам – отношения между ними.
Процедурой поиска знаний в семантической сети является поиск по образцу, который представляет собой либо полностью определённый фрагмент знаний, либо содержит свободные переменные. При возникновении информационной потребности, определяющей содержание и цель запроса, формируется сеть запроса, построенная по тем же правилам и с использованием тех же объектов и отношений, что и система знаний. Поиск ответа на запрос реализуется сопоставлением сети запроса с фрагментами семантической сети, представляющей систему знаний. Результатом поиска может быть один из ответов на запрос или все ответы сразу. В случае необходимости получения всех ответов результат может быть получен путём обнаружения всех сопоставляемых с сетью запроса фрагментов.
2.4.2.4 Фреймовые модели
Фреймовые модели возникли из интуитивных предположений, касающихся механизмов психологической деятельности человека. Предполагается, что человек имеет представление понятий в виде набора определенных категории сущностей, которые не требуют строго формулирования свойств. При этом категории не имеют четких определений, а носят характер весьма расплывчатых понятий.
Каждая категория сущностей ассоциируется у человека с объектами, свойства которых наиболее ярко отражают тот класс объектов, к которому они относятся. Такие объекты были названы «прототипическими объектами», или прототипами.
Фреймовая модель представляет собой систематизированную в виде единой теории технологическую модель памяти человека и его сознания. В основе этой модели лежит понятие фрейма представляющего собой структуру данных для представления стереотипных ситуаций. Эта структура наполняется разнообразной информацией об объектах и событиях, которые следует ожидать в этой ситуации, и о том, как использовать информацию, имеющуюся во фрейме. Идея состояла в том, чтобы сконцентрировать все знания о данном классе объектов или событий в единой структуре данных.
Представление знаний, основанное на фреймах, является альтернативным по отношению к системам продукций: оно дает возможность хранить родовидовую иерархию понятий в базе знаний в явной форме. Фреймом состоит из характеристик описываемой им ситуации и их значений, характеристики называются слотами, а значения – заполнителями слотов. Слот может содержать не только конкретное значение, но и имя процедуры, позволяющей вычислить его по заданному алгоритму, а также одну или несколько продукций (эвристик), с помощью которых это значение можно найти. В слот может входить не одно, а несколько значений. Иногда слот включает компонент, называемый фасетом, который задает диапазон или перечень его возможных значений. Фасет указывает также граничные значения заполнителя слота.
Особенностью фрейма является то, что он объединяет в себе декларативные и процедурные знания о некоторой сущности в структуру записей, которая состоит из слотов и наполнителей. Слоты играют ту же роль, что и поля в записи, а наполнители - это значения, хранящиеся в полях.
Каждый фрейм имеет специальный слот, заполненный наименованием сущности, которую он представляет. Другие слоты заполнены значениями разнообразных атрибутов, ассоциирующихся с объектом, а также процедурами, которые необходимо активизировать всякий раз, когда осуществляется доступ к фрейму или его обновление. Идея состоит в том, чтобы выполнение большей части вычислений, связанных с решением проблемы, явилось побочным эффектом передачи данных во фрейм или извлечения данных из него.
Фундаментальная идея фреймовой модели состоит в том, что свойства и процедуры фреймов, расположенных выше в системе фреймов, являются более или менее фиксированными, поскольку они представляют понятия, истинные для определённой сущности, в то время как фреймы более нижних уровней имеют слоты, которые должны быть заполнены наиболее динамической информацией, подверженной частым изменениям. Если такого рода динамическая информация отсутствует из-за неполноты информации о наиболее вероятном состоянии дел, то слоты фреймов более нижних уровней заполняются данными, унаследованными от фреймов более верхних уровней, которые носят глобальный характер.
Данные, которые передаются в процессе функционирования системы от посторонних источников знаний во фреймы нижних уровней, имеют более высокий приоритет, чем данные, унаследованные от фреймов более верхних уровней.
Вывод во фреймовой модели осуществляется благодаря выполнению присоединённых процедур, сцепленных со слотами. Активация выполнения таких процедур производится при добавлении, удалении и изменении данных, содержащихся во фреймах. Также возможно наличие процедур, которые будут вызываться для получения ответов на конкретные запросы, задаваемые для получения определённых знаний.
Основными достоинствами фреймовой модели являются способность отражения концептуальной основы организации памяти человека, возможность заполнения неизвестных значений слотов значениями по умолчанию, а также естественность и наглядность представления знаний.
2.4.3 Основные интеллектуальные технологии обработки данных
2.4.3.1 Технологии, основанные на использовании нечёткой логики
В тех случаях, когда задача не имеет точного и компактного аналитического описания или затраты на его создание превосходят предполагаемый эффект от системы, то целесообразным является создание нечёткой экспертной системы. Создание таких систем подразумевает использование нечёткой логики, которая позволяет применять концепцию неопределённости в логических выводам.
Основной особенностью нечёткой логики является то, что вместе со значениями «ложь» и «истина» она имеет возможность оперировать значениями между ними.
Нечеткое правило логического вывода представляет собой упорядоченную пару (А, В), где А - нечеткое подмножество пространства входных значений X, В - нечеткое подмножество пространства выходных значений Y. Система нечеткого вывода – это отображение Iразм(Х) в Iразм(Y), где разм(Z) – оператор определения размерности пространства Z. Число элементов в Iразм(Х) и Iразм(Y) бесконечно велико, поэтому невозможно задать правила нечеткого вывода соответствующими парами точек. Однако они могут быть описаны в терминах теории нечетких множеств.
Нечёткие правила имеют следующую структуру: «Если..., то....». Например, «Если стаж менеджера маленький и количество успешных проектов (проведённых им) много и возраст менеджера молодой, то число трудовых ресурсов, необходимое для выполнения проекта под управлением менеджера среднее».
Нечеткие правила вывода образуют базу правил. Важно то, что в нечеткой экспертной системе в отличие от традиционной работают все правила одновременно, но степень их влияния на выход может быть различной. Принцип вычисления суперпозиции многих влияний на окончательный результат лежит в основе нечетких экспертных систем.
Процесс обработки нечетких правил вывода в экспертной системе состоит из четырёх этапов.
На первом этапе проводится вычисление степени истинности левых частей правил (между «если» и «то»), то есть определение степени принадлежности входных значений нечетким подмножествам, указанным в левой части правил вывода.
Второй этап состоит из модификации нечетких подмножеств, указанных в правой части правил вывода (после «то»), в соответствии со значениями истинности, полученными на первом этапе.
На третьем этапе следует произвести объединение (суперпозицию) модифицированных подмножеств.
На заключительном этапе требуется осуществить скаляризацию результата суперпозиции. Четвертый этап представляется собой переход от нечетких подмножеств к скалярным значениям.
Для определения степени истинности левой части каждого правила нечёткая экспертная система вычисляет значения функций принадлежности нечетких подмножеств от соответствующих значений входных переменных.
Полученное значение истинности используется для модификации нечеткого множества, указанного в правой части правила. Для выполнения такой модификации используют один из двух методов: «минимума» (correlation-min encoding) и «произведения» (correlation-product encoding). Первый метод ограничивает функцию принадлежности для множества, указанного в правой части правила, значением истинности левой части. Во втором методе значение истинности левой части используется как коэффициент, на который умножаются значения функции принадлежности.
Результат выполнения правила - нечеткое множество. Другими словами, происходит ассоциирование переменной и функции принадлежности, указанных в правой части.
Выходы всех правил вычисляются нечеткой экспертной системой отдельно, однако в правой части нескольких из них может быть указана одна и та же нечеткая переменная. Как было сказано выше, при определении обобщенного результата необходимо учитывать все правила. Для этого система производит суперпозицию нечетких множеств, связанных с каждой из таких переменных, эта операция называется нечетким объединением правил вывода. Традиционно суперпозиция функций принадлежности нечетких множеств m1F(x),m2F(x),…,mnF(x) определяется как: msum F(x)=max{ miF(x)}, iÎ[1,n]. Другой метод суперпозиции состоит в суммировании значений всех функций принадлежности.
Конечный этап обработки базы правил вывода - переход от нечетких значений к конкретным скалярным. Процесс преобразования нечеткого множества в единственное значение называется «скаляризацией» или «дефазификацией» (defuzzification). Чаще всего в качестве такого значения используется «центр тяжести» функции принадлежности нечеткого множества (centroid defuzzification method). Другой распространенный подход - использование максимального значения функции принадлежности (modal defuzzification method). Конкретный выбор методов суперпозиции и скаляризации осуществляется в зависимости от желаемого поведения нечеткой экспертной системы. Наиболее точным методом скаляризации является метод «центра тяжести».
Наиболее часто используются нечеткие системы двух типов - Мамдани и Сугэно. В системах типа Мамдани база знаний состоит из правил вида:“Если x1=низкий и x2=средний, то y=высокий”. В системах типа Сугэно база знаний состоит из правил вида “Если x1=низкий и x2=средний, то y=a0+a1x1+a2x2". Таким образом, основное отличие между системами Мамдани и Сугэно заключается в разных способах задания значений выходной переменной в правилах, образующих базу знаний. В системах типа Мамдани значения выходной переменной задаются нечеткими термами, в системах типа Сугэно - как линейная комбинация входных переменных.
Задачи принятия решений в управлении, диагностике, многокритериальной оценке и многофакторном анализе можно рассматривать как задачи идентификации, обладающие следующими общими свойствами:
1) для принятия решения необходимо установить зависимость между входными и выходной переменной;
2) выходная переменная ассоциируется с объектом идентификации, т.е. с видом принимаемого решения;
3) входные переменные ассоциируются с параметрами состояния объекта идентификации;
4) выходная и входные переменные могут иметь количественные и качественные оценки;
5) структура взаимосвязи между выходной и входными переменными описывается правилами ЕСЛИ <входы>, ТО <выход>, использующими качественные оценки переменных и представляющими собой нечеткие базы знаний.
Исходной информацией для построения функций принадлежности могут служить данные статистики, экспертные оценки, например, экспертные парные сравнения. Чем выше профессиональный уровень эксперта, тем выше адекватность нечеткой модели, построенной на этапе грубой настройки. Эта модель названа чистой экспертной системой, поскольку для ее построения используется только экспертная информация. Однако, никто не может гарантировать совпадение результатов нечеткого логического вывода (теория) и экспериментальных данных. Поэтому необходим второй этап, на котором осуществляется тонкая настройка нечеткой модели путем ее обучения по экспериментальным данным.
Суть этапа тонкой настройки состоит в подборе таких весов нечетких правил ЕСЛИ-ТО и таких параметров функций принадлежности, которые минимизируют различие между желаемым (экспериментальным) и модельным (теоретическим) поведением объекта.
Этап тонкой настройки формулируется как задача нелинейной оптимизации, которая может решаться различными методами, среди которых наиболее универсальным является наискорейший спуск. Однако, при большом количестве входных переменных и нечетких термов в базе знаний, применение метода наискорейшего спуска требует поиска минимума из разных начальных точек, что существенно увеличивает затраты машинного времени. Для решения этой проблемы можно использовать тонкую настройку нечеткой базы знаний с применением генетических алгоритмов оптимизации. Эти алгоритмы являются аналогом случайного поиска, который ведется одновременно из разных начальных точек, что сокращает время поиска оптимальных параметров нечеткой модели.
Для настройки нечетких моделей типа Сугэно можно использовать подход, основанный на применении адаптивных нейро-нечетких систем - ANFIS (Adaptive Neuro-Fuzzy Inference System). ANFIS является одним из первых вариантов гибридных нейро-нечетких сетей - нейронной сети прямого распространения сигнала особого типа. Архитектура нейро-нечеткой сети изоморфна нечеткой базе знаний. В нейро-нечетких сетях используются дифференцируемые реализации треугольных норм (умножение и вероятностное ИЛИ), а также гладкие функции принадлежности. Это позволяет применять для настройки нейро-нечетких сетей быстрые алгоритмы обучения нейронных сетей, основанные на методе обратного распространения ошибки. Нейро-нечеткую сеть можно рассматривать как одну из разновидностей систем нечеткого логического вывода типа Сугэно. При этом функции принадлежности синтезированных систем настроены (обучены) так, чтобы минимизировать отклонения между результатами нечеткого моделирования и экспериментальными данными.
2.4.3.2 Нейронные сети
В интеллектуальных системах возможно применение нейронных сетей, которые можно рассматривать в качестве простых математических моделей мозгоподобных систем, функционирующих как параллельные распределенные вычислительные сети. В нейронных сетях используется преимущественно-поведенческий подход к решаемой задаче: сеть возможно обучать на различных примерах и в результате обучения происходит настройка параметров сети на основе разработанных алгоритмов.
Искусственные нейроны связаны и сопоставляют образцы на множестве примеров и обучаются на этих примерах, регулируя веса связей. Выходные образцы используются для классификации нового множества примеров, способны распознавать образы, даже если данные содержат помехи, неоднозначны, искажены или имеют много разновидностей.
Различают статические нейроны, в которых сигнал передаётся без задержки, и динамические, где учитывается возможность таких задержек.
Обучаемые нейросетевые конструкции можно описать:
– используемой архитектурой;
– организацией нейронов;
– функцией состояния;
– функцией преобразования;
– обучающим алгоритмом.
Архитектура описывает как связаны элементарные элементы. Обычно используется архитектура с прямой связью Больцмана. Нейронные сети с такой архитектурой состоят из статических нейронов, так что сигнал на выходе сети появляется в тот же момент, когда сигнал подаётся на вход.
Организация (топология) сети может быть различной. В случае, ели не все составляющие её нейроны являются выходными, то сеть содержит скрытые нейроны. Наиболее общим типом архитектуры является сеть, в которой все нейроны связаны друг с другом. В конкретных случаях нейроны сгруппированы в слои.
Существуют три типа уровней элементов сети: входной уровень, скрытые уровни и выходной уровень. Одни исследователи рассматривают количество уровней, как часть архитектуры, другие рассматривают количество уровней и узлов в уровне скорее как атрибуты сети, а не как часть архитектуры.
Структура нейрона описывается следующими компонентами:
– множество взвешенных входных связей;
– пороговое значение;
– функция состояния;
– нелинейная функция преобразования.
Значение входного сигнала определяется либо предыдущим нейроном, либо внешней средой. Пороговое значение не связано с другими нейронами в сети и определяется для входной величины, равной 1 для функции суммирования.
Каждый вход нейрона, включая пороговое значение, имеет связанный с ним вес. Он представляет собой вещественное число, определяющее степень входных взаимодействий нейрона.
Функция состояния является наиболее общей формой – это простая функция суммирования. Выход функции состояния является входом для функции преобразования. Функция преобразования – это нелинейная математическая функция, которая преобразовывает данные к определенному масштабу.
Существует два базисных типа функций преобразования: непрерывный и дискретный. Обычно используемые непрерывные функции преобразования - пилообразная, sign(x), ArcTg и гиперболический тангенс. Непрерывные функции иногда называются функциями сжатия. Обычно используемые дискретные функции преобразования, которые иногда называют функциями активизации.
Функции активации могут быть различных видов:
– линейные: выходной сигнал нейрона равен его потенциалу;
– ступенчатые: нейрон принимает решение, выбирая один из двух вариантов (активен/неактивен);
– линейная с насыщением: нейрон выдает значения, промежуточные между двумя предельными значениями A и B;
– многопороговая: выходной сигнал может принимать одно из q значений, определяемых (q-1) порогом внутри предельных значений A и B;
– сигмоидальная: с выходными значениями в промежутке (0,1) и с выходными значениями от -1 до 1.
Обучение – это процесс настраивания параметров нейросети. На этапе обучения происходит вычисление синаптических коэффициентов в процессе решения нейронной сетью задач, в которых необходимый ответ определяется не по правилам, а с помощью примеров, сгруппированных в обучающие множества. Такое множество состоит из ряда примеров с указанным для каждого из них значением выходного параметра, которое было бы желательно получить. Выходное значение находится путём сопоставления входного образца с правильным ответом. Множество примеров (обучающая выборка) с известными выходами (адресатами) неоднократно вводится в сеть, чтобы «обучить» сеть. Этот процесс обучения продолжается до тех пор, пока разность между входными и выходными образцами для обучающей выборки достигнет подходящего значения.
Различают алгоритмы обучения с учителем и без учителя. Обучение с учителем предполагает, что для каждого входного значения существует требуемое выходное значение. Вместе они называются обучающей парой. Обычно сеть обучается на некотором числе таких обучающих пар, которые представляют собой обучающую выборку.
При подаче значения на вход вычисляется выход сети и сравнивается с соответствующим целевым значением, разность (ошибка) с помощью обратной связи подается в сеть и веса изменяются в соответствии с алгоритмом, стремящимся минимизировать ошибку. Пары из обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
Алгоритмы с учителем нашли широкое применение на практике, но с точки зрения биологии эти алгоритмы не являются правдоподобными. Сложно вообразить, что человеческий мозг имеет механизм, который при сравнении желаемых и действительных значений выполняет коррекцию весов с помощью обратной связи. Поэтому обучение без учителя является намного более правдоподобной моделью обучения в биологической системе.
Алгоритмы обучения без учителя не нуждается в целевых значениях для выходов и, следовательно, не требуют сравнения с предопределенными идеальными ответами. Обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход значений из данного класса даст определенный выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Эту задачу возможно решить с помощью идентификации связей между входами и выходами.
Нейронные сети на современном этапе развития интеллектуальных информационных систем являются наиболее перспективным способом представления и организации знаний.
2.4.3.3 Генетические алгоритмы
Генетический алгоритм – это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нём используется как аналог механизма генетического наследования, так и аналог естественного отбора, происходящего в процессе эволюции живых организмов.
Суть естественного отбора состоит в том, что выживают те особи, которые оказываются более приспособленными к условиям обитания окружающей их среды. Эти особи имеют больше возможностей для выживания и размножения, и тем самым оставляют после себя больше потомства, чем плохо приспособленные особи. Потомки наследуют от своих родителей основные их качества благодаря передаче генетическое информации, то есть генетическому наследованию. По той причине, что более приспособленные особи оставляют после себя больше потомства, то доля сильных потомков в общей массе особей будет возрастать.
Генетические алгоритмы применимы к широкому классу задач, так как их применение в качестве информации об оптимизируемой функции использует только её значения в определённых точках пространства поиска. Следовательно, применение генетических алгоритмов возможно для функций, не имеющих аналитического описания.
Генетические алгоритмы моделируют те процессы в популяциях, которые являются существенными для развития. Они работают с совокупностью «особей» – популяцией, каждая из которых представляет возможное решение данной проблемы. Каждая особь оценивается мерой ее «приспособленности» согласно тому, насколько «хорошо» соответствующее ей решение задачи. Наиболее приспособленные особи получают возможность «воспроизводить» потомство с помощью «перекрестного скрещивания» с другими особями популяции. Это приводит к появлению новых особей, которые сочетают в себе некоторые характеристики, наследуемые ими от родителей. Наименее приспособленные особи с меньшей вероятностью смогут воспроизвести потомков, так что те свойства, которыми они обладали, будут постепенно исчезать из популяции в процессе эволюции.
Так и воспроизводится вся новая популяция допустимых решений, выбирая лучших представителей предыдущего поколения, скрещивая их и получая множество новых особей. Это новое поколение содержит более высокое соотношение характеристик, которыми обладают хорошие члены предыдущего поколения. Таким образом, из поколения в поколение, хорошие характеристики распространяются по всей популяции. Скрещивание наиболее приспособленных особей приводит к тому, что исследуются наиболее перспективные участки пространства поиска. В конечном итоге, популяция будет сходиться к оптимальному решению задачи.
Под термином «генетические алгоритмы» понимается достаточно широкий класс алгоритмов, которые иногда могут сильно отличаться друг от друга. Вызвано это тем, что исследователи работают с различными типами представлений, операторов кроссовера и мутации, специальных операторов, и различных подходов к воспроизводству и отбору.
Модель эволюционного развития, применяемая в генетических алгоритмах, сильно упрощена по сравнению со своим природным аналогом. Однако, генетический алгоритм является достаточно мощным средством и может применяться для широкого класса прикладных задач. Применение генетических алгоритмов не всегда гарантирует нахождение глобального решения задачи, но несомненным его достоинством является то, что с его помощью возможно найти допустимое решение задачи и сделать это достаточно быстро.
Генетические алгоритмы целесообразно применять для решения сложных задач, не имеющих специальных методов решения. Применение генетических алгоритмов в сочетании со специальные методы решения сложных задач может быть достаточно эффективным. Однако, решение задачи этими способами по отдельности покажет однозначное превосходство специальных методов над применением генетических алгоритмов.
В интеллектуальных системах благодаря генетическим алгоритмам можно производить оптимизационную настройку функций принадлежности нечетких множеств, которые задаются параметризованной функцией формы. Применяя генетические алгоритмы возможно оптимизировать и состав больших баз нечетких продукций, и структуру нейронной сети для генетических нечетких нейронных сетей.
2.4.4 Архитектура экспертных систем
Экспертная система (ЭС) – это компьютерная программа, которая использует принципы искусственного интеллекта и знания эксперта для обработки оперативной информации и принятия обоснованных решений в анализируемой области.
Архитектура экспертной системы содержит следующие основные компоненты:
– решатель (процедуры вывода);
– динамически изменяемая база знаний;
– рабочая память.
С точки зрения практического применения к ЭС предъявляются следующие требования:
1) способность вести диалог о решаемой задаче на языке, удобном пользователю (эксперту), и, в частности, приобретать в ходе диалога новые знания;
2) способность при решении задачи следовать линии рассуждения, понятной пользователю (эксперту);
3) способность объяснять ход своего рассуждения на языке, удобном для пользователя (эксперта), что необходимо как при использовании, так и при совершенствовании системы (т.е. при отладке и модификации базы знаний).
Первое требование реализуется лингвистическим процессором ЭС и компонентой приобретения знаний, а для выполнения второго и третьего требований в ЭС вводится объяснительная компонента. Кроме того, второе требование накладывает ограничения на способ решения задачи – ход рассуждения в процессе решения должен быть понятен пользователю (эксперту). Данное ограничение приводит к тому, что в экспертных системах, как правило, неприменимы, например, статистические методы.
В типичную экспертную систему входит следующий набор компонент:
– база знаний, хранящая множество продукций (в общем случае правил);
– рабочая память, хранящая данные (база данных);
– интерпретатор, решающий на основе имеющихся в системе знаний предъявленную ему задачу;
– лингвистический процессор, осуществляющий диалоговое взаимодействие с пользователем (экспертом) на естественном для него языке (естественный язык, профессиональный язык, язык графики и т.п.);
– компонента приобретения знаний;
– объяснительная компонента, дающая объяснение действий системы и отвечающая на вопросы о том, почему некоторые заключения были сделаны или отвергнуты.
Экспертная система работает в двух режимах: в режиме приобретения знаний и в режиме решения задач. В режиме приобретения знаний в общении с экспертной системой участвует эксперт (через посредство инженера по знаниям). В этом режиме эксперт наполняет систему знаниями (правилами), которые позволят ей в режиме решения самостоятельно решать задачи из области экспертизы, отметим, что режиму приобретения знании в традиционном подходе к разработке программ соответствуют этапы алгоритмизации, программирования и отладки, выполняемые программистом. Таким образом, в отличие от традиционного подхода, в ЭС разработку программ осуществляет не программист, а специалист в области экспертизы, не владеющий программированием.
В режиме решения задач в общении с экспертной системой участвует пользователь, которого интересует результат и (или) способ получения решения. Необходимо отметить, что в зависимости от назначения ЭС пользователь может либо не быть специалистом в данной проблемной области (в этом случае он, не умея получить ответ сам, обращается к ЭС за советом), либо быть специалистом (в этом случае пользователь может и сам получить результат, но обращается к ЭС с целью ускорить процесс получения результата или с целью возложить на ЭС рутинную работу). Схема обобщенной экспертной системы представлена на рисунке 2.1.
В режиме приобретения знании эксперт вводит в систему правила из области экспертизы. Такие правила представляются на естественном для пользователя языке. Объединение вновь вводимых правил с базой знаний осуществляется компонентой приобретения знаний. Для того чтобы убедиться в достаточности знаний (т.е. убедиться в том, что процесс отладки задачи завершен), эксперт дает системе тестовые примеры. В случае, если результат, полученный системой, не удовлетворяет эксперта, он с помощью объяснительной компоненты получает сведения о том, как был сформирован результат. По окончании процесса отладки система передается в эксплуатацию пользователям.
В режиме решения данные о задаче пользователя после обработки их лингвистическим процессором поступают в рабочую память. Лингвистический процессор выполняет следующие действия:
– преобразует входные данные, представленные на ограниченном естественном языке, в представление на внутреннем языке системы;
– преобразует сообщения системы, выраженные на внутреннем языке, в сообщения на ограниченном естественном языке.
Интерпретатор на основе входных данных, продукционных правил и общих фактов о проблемной области формирует решение задачи. Если ответ системы не понятен пользователю, то он может потребовать, чтобы система объяснила, как этот ответ был получен. Обычно объяснительный блок сообщает следующее:
– как правила используют информацию пользователя;
– почему использовались (не использовались) данные правила;
– какие были сделаны выводы.
Все объяснения даются на ограниченном естественном языке.


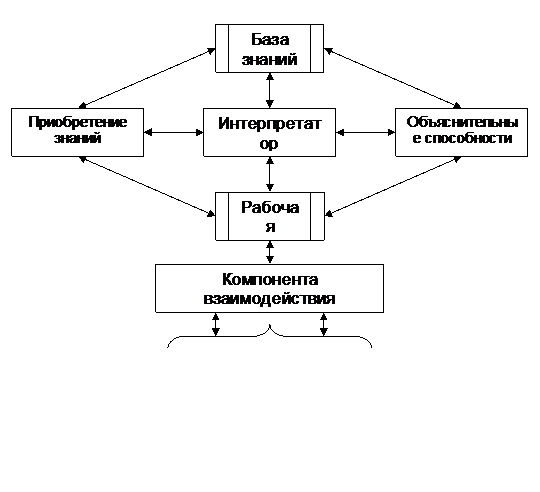
Рисунок 2.1 – Схема обобщённой экспертной системы
Рекомендуемые структура и содержание дипломных проектов по проектированию экспертной системы
(Примерный вариант 3а)
Введение
1 Аналитическая часть
1.1 Идентификация проблемы
1.1.1 Общая характеристика проблемной области
1.1.2 Определение ресурсов на разработку ЭС
1.1.3 Определение источников разработки ЭС
1.1.4 Цели и классы решаемых задач
1.2 Концептуализация проблемы
1.3 Выбор метода формализации знаний и инструментальных средств разработки ЭС
1.4 Определение перечня оригинальных компонентов программного обеспечения ЭС, подлежащих разработке
2 Проектная часть
2.1 Формализация базы знаний и оригинальных компонентов ЭС, подлежащих разработке
2.2 Проектирование базы данных
2.3 Программная реализация экспертной системы
2.3.1 Программная реализация базы знаний и оригинальных компонентов программного обеспечения ЭС
2.3.2 Описание дерева вызова программ (или блок-схемы) и спецификации оригинальных программных средств ЭС
2.3.3 Определение параметров генерации и настройки механизмов вывода, приобретения и объяснения знаний, интеллектуального интерфейса
2.4 Тестирование экспертной системы
2.4.1 Данные для контрольного примера
2.4.2 Описание технологического процесса решения задач экспертизы
2.4.3 Анализ полученных результатов экспертизы
3 Обоснование экономической эффективности проекта
3.1 Выбор и обоснование методики расчета экономической эффективности
3.2 Расчет показателей экономической эффективности проекта
4 Безопасность жизнедеятельности проекта
Заключение
Список использованных источников
Приложения
Аналитическая часть
Подраздел 1.1 "Идентификация проблемы" включает в себя определение назначения и сферы применения экспертной системы (ЭС), выделение ресурсов, постановку и параметризацию решаемых задач.
Этап идентификации связан, прежде всего, с осмыслением тех задач, которые предстоит решить будущей ЭС, и формированием требований к ней. Результатом данного этапа является ответ на вопрос, что надо сделать и какие ресурсы необходимо задействовать (идентификация задачи, определение участников процесса проектирования и их роли, выявление ресурсов и целей).
В пункте 1.1.1 определяют проблемную область, рассматриваются характеристики и особенности проблемной области, обосновывают необходимость разработки экспертной системы в проблемной области. Обычно разработка ЭС в той или иной сфере деятельности связана с затруднениями лиц, принимающих решение, что сказывается на эффективности функционирования проблемной области. Эти затруднения могут быть обусловлены недостаточным опытом работы в данной области, сложностью постоянного привлечения экспертов, нехваткой трудовых ресурсов для решения простых интеллектуальных задач, необходимостью интеграции разнообразных источников знаний.
Идентификация сферы применения ЭС осуществляется на основе анализа узких мест функционирования проблемной области. Например, плохой маркетинг, большие материальные и трудовые издержки, низкая ритмичность производства и т.д. Сфера применения ЭС должна четко идентифицировать участок деятельности экспертов и классы объектов и ситуаций, на которые этот участок распространяется.
Идентификация проблемы заключается в составлении неформального (вербального) описания, в котором указываются: общие характеристики задачи; подзадачи, выделяемые внутри данной задачи; ключевые понятия (объекты), их входные (выходные) данные; предположительный вид решения, а также знания, относящиеся к решаемой задаче.
В пункте 1.1.2 определяются необходимые ресурсы для разработки ЭС: время, люди, ЭВМ и т. д. Обычно в разработке ЭС участвуют не менее трех-четырех человек — один эксперт, один или два инженера по знаниям и один программист, привлекаемый для модификации и согласования инструментальных средств. Также к процессу разработки ЭС могут по мере необходимости привлекаться и другие участники. Например, инженер по знаниям может пригласить других экспертов, чтобы убедиться в правильности своего понимания основного эксперта, представительности тестов, демонстрирующих особенности рассматриваемой задачи, совпадения взглядов различных экспертов на качество предлагаемых решений. Кроме того, для сложных систем считается целесообразным привлекать к основному циклу разработки несколько экспертов. Однако в этом случае, как правило, требуется, чтобы один из экспертов отвечал за непротиворечивость знаний, сообщаемых коллективом экспертов.
В этом пункте формируются также основные пользовательские требования к интерфейсу ЭС.
При проектировании ЭС типичными ресурсами являются время разработки, вычислительные средства и объем финансирования. При определении времени разработки обычно имеется в виду, что сроки разработки и внедрения ЭС составляют, как правило, не менее года (при трудоемкости 5 чел.-лет). Определение объема финансирования оказывает существенное влияние на процесс разработки, так как, например, при недостаточном финансировании предпочтение может быть отдано не разработке оригинальной новой системы, а адаптации существующей.
В процессе идентификации задачи инженер по знаниям и эксперт работают в тесном контакте. Начальное неформальное описание задачи экспертом используется инженером по знаниям для уточнения терминов и ключевых понятий. Эксперт корректирует описание задачи, объясняет, как решать ее и какие рассуждения лежат в основе того или иного решения. После нескольких циклов, уточняющих описание, эксперт и инженер по знаниям получают окончательное неформальное описание задачи.
В пункте 1.1.3 описываются источники знаний, необходимые для разработки ЭС: существующие аналогичные ЭС, используемые методические материалы, технические отчеты, публикации в печати, книги, методики, дополнительные эксперты и т.п.. Для эксперта источниками знаний служат его предшествующий опыт по решению задачи, книги, известные примеры решения задач, а для инженера по знаниям — опыт в решении аналогичных задач, методы представления знаний и манипулирования ими, программные инструментальные средства.
В пункте 1.1.4 при идентификации целей важно отличать цели, ради которых создается ЭС, от задач, которые она должна решать. Примерами возможных целей являются: формализация неформальных знаний экспертов; улучшение качества решений, принимаемых экспертом; автоматизация рутинных аспектов работы эксперта (пользователя); тиражирование знаний эксперта.
Как правило, назначение экспертной системы связано с одной из следующих областей:
- обучение и консультация неопытных пользователей;
- распространение и использование уникального опыта экспертов;
- автоматизация работы экспертов по принятию решений;
- оптимизация решения проблем, выдвижение и проверка гипотез.
Сфера применения экспертной системы характеризует тот круг задач, который подлежит формализации, например, "оценка финансового состояния предприятия”, “выбор поставщика продукции”, “формирование маркетинговой стратегии” и т.д. Обычно сложность решаемых в экспертной системе проблем должна соответствовать трудоемкости работы эксперта в течение нескольких часов. Более сложные задачи имеет смысл разбивать на совокупности взаимосвязанных задач, которые подлежат разработке в рамках нескольких экспертных систем.
В подразделе 1.2 «Концептуализация знаний» находится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. Этот этап завершается созданием модели предметной области (ПО), включающей основные концепты и отношения. На этапе концептуализации определяются следующие особенности задачи: типы доступных данных; исходные и выводимые данные, подзадачи общей задачи; используемые стратегии и гипотезы; виды взаимосвязей между объектами ПО, типы используемых отношений (иерархия, причина — следствие, часть — целое и т.п.); процессы, используемые в ходе решения; состав знаний, используемых при решении задачи; типы ограничений, накладываемых на процессы, используемые в ходе решения; состав знаний, используемых для обоснования решений.
Существует два подхода к процессу построения модели предметной области, которая является целью разработчиков ЭС на этапе концептуализации. Признаковый или атрибутивный подход предполагает наличие полученной от экспертов информации в виде троек объект — атрибут — значение атрибута, а также наличие обучающей информации. Этот подход развивается в рамках направления, получившего название формирование знаний или "машинное обучение" (machine learning).
Второй подход, называемый структурным (или когнитивным), осуществляется путем выделения элементов предметной области, их взаимосвязей и семантических отношений.
Для атрибутивного подхода характерно наличие наиболее полной информации о предметной области: об объектах, их атрибутах и о значениях атрибутов. Кроме того, существенным моментом является использование дополнительной обучающей информации, которая задается группированием объектов в классы по тому или иному содержательному критерию. Тройки объект — атрибут — значение атрибута могут быть получены с помощью так называемого метода реклассификации, который основан на предположении что задача является объектно-ориентированной и объекты задачи хорошо известны эксперту. Идея метода состоит в том, что конструируются правила (комбинации значений атрибутов), позволяющие отличить один объект от другого. Обучающая информация может быть задана на основании прецедентов правильных экспертных заключений, например, с помощью метода извлечения знаний, получившего название "анализ протоколов мыслей вслух".
При наличии обучающей информации для формирования модели предметной области на этапе концептуализации можно использовать весь арсенал методов, развиваемых в рамках задачи распознавания образов. Таким образом, несмотря на то, что здесь атрибутивному подходу не уделено много места, он является одним из потребителей всего того, что было указано в главе, посвященной распознаванию образов и автоматического группирования данных.
Структурный подход к построению модели предметной области предполагает выделение следующих когнитивных элементов знаний: 1. Понятия. 2. Взаимосвязи. 3. Метапонятия. 4. Семантические отношения.
Выделяемые понятия предметной области должны образовывать систему, под которой понимается совокупность понятий, обладающая следующими свойствами: уникальностью (отсутствием избыточности); полнотой (достаточно полным описанием различных процессов, фактов, явлений и т.д. предметной области); достоверностью (валидностью — соответствием выделенных единиц смысловой информации их реальным наименованиям) и непротиворечивостью (отсутствием омонимии).
В подразделе 1.3 рассматриваются методы представления знаний, осуществляется выбор метода формализации знаний, в рамках которого осуществляется проектирование структуры базы знаний. Выбор метода формализации знаний (формализма) обусловливается следующим: особенностями знаний, методов решения проблем, требованиями пользователей к эксплуатации и интерфейсу ЭС. В соответствии с выбранным методом представления знаний выбираются инструментальные средства разработки ЭС. В качестве инструментальных средств разработки ЭС, в зависимости от особенностей проблемной области и стадии разработки могут быть оболочки ЭС, генераторы ЭС, языки представления знаний и языки программирования. В данном подразделе кратко описываются характеристики и возможности выбранных инструментальных средств.
В подразделе 1.4 на основе выбранного инструментального средства определяется перечень разрабатываемых программных компонентов, которые должны расширить функциональные возможности механизмов вывода, приобретения, объяснения знаний и интеллектуального интерфейса выбранного инструментального средства.
Проектная часть
В подразделе 2.1 описывается проектирование базы знаний ЭС и разрабатываемых оригинальных компонент.
В этом подразделе описывается формализованное представление концепций предметной области, представленных в подразделе 1.2 на основе языка представления знаний (ЯПЗ), который либо выбирается из числа уже существующих, либо создается заново. Все ключевые понятия и отношения, определенные на этапе концептуализации в пункте 1.2 выражаются на ЯПЗ. Другими словами, в данном пункте определяются состав средств и способы представления декларативных и процедурных знаний, осуществляется это представление и в итоге формируется описание решения задачи ЭС на предложенном (инженером по знаниям) формальном языке или в соответствии с выбранным в подразделе 1.3 инструментальным средством.
Выходом этапа формализации является описание того, как рассматриваемая задача может быть представлена в выбранном или разработанном формализме. Сюда относится указание способов представления знаний (фреймы, сценарии, семантические сети и т.д.), определение способов манипулирования этими знаниями (логический вывод, аналитическая модель, статистическая модель и др.) и интерпретации знаний.
Подраздел 2.2 "Проектирование базы данных" предусматривается в случае использования больших объемов исходных данных, которые не могут быть введены в процессе диалога с ЭС. Подраздел 2.2 соответствуют пунктам раздела 2.1 проектной части первого варианта содержания ДП. Процесс проектирования базы данных может быть выполнен вручную в соответствии с имеющимися методиками, либо с помощью CASE-систем. В данном разделе должна быть представлена информационная модель базы данных.
В подразделе 2.3 описывается программное обеспечение ЭС. Программное обеспечение экспертной системы включает настраиваемую системную и программируемую оригинальную части.
В пункте 2.3.1 описывается программная реализация базы знаний и оригинальных программных компонент, используемых стратегий ввода, приобретения, объяснения знаний, организации диалога.
В пункте 2.3.2дается описание дерева вызова программ (или блок-схемы) и спецификации оригинальных программных средств ЭС.
Для описания алгоритма могут быть использованы также и другие средства. Правила оформления блок-схем приведены в разделе 4 настоящего пособия.
В пункте 2.3.3определяются параметры генерации и настройки механизмов вывода, приобретения и объяснения знаний, интеллектуального интерфейса.
В приложениях должны быть представлены распечатки схем настройки необходимых механизмов и разработанных программных модулей.
В подразделе 2.4 построенная экспертная система тестируется, т.е. оценивается с позиции точности работы и полезности. Тестируется правильность делаемых заключений, адекватность базы знаний проблемной области, соответствие методов решения проблем экспертным, легкость и естественность взаимодействия с системой, надежность, производительность и адаптивность.
В пункте 2.4.1 в качестве тестовых примеров должны быть выбраны задачи с апробированными эталонными результатами. Тестовые примеры проверяют также все возможные граничные значения получаемых результатов.
В пункте 2.4.2 приводится схема технологического процесса решения основных задач экспертизы, описываются все режимы взаимодействия пользователей с ЭС. Правила оформления схем технологического процесса решения приведены в разделе 4 "Методические указания к выполнению графических работ".
В пункте 2.4.3 представляются результаты прогонов контрольных примеров, которые анализируются с позиции описываемых выше критериев. Распечатки контрольных прогонов приводятся в приложении.
Обоснование экономической эффективности проекта
В разделе 3 производится расчет экономической эффективности проекта; при этом предлагается произвести сравнение стоимостных затрат на эксплуатацию ЭС со стоимостными затратами экспертизы некоторого базового варианта: ручного или альтернативного с использованием других инструментальных средств и технологических решений.
В подразделах 3.1-3.2 при обосновании экономической эффективности необходимо учитывать затраты на приобретение и освоение инструментальных средств, а также проектирования. При расчете затрат на проектирование экспертной системы следует помнить, что процесс проектирования занимает до 75% суммарного времени, затраченного на создание системы.
Результаты расчета показателей экономической эффективности проекта, получаемые в данном подразделе, необходимо представить в форме таблиц, графиков, рекомендуемых методическими материалами.
Содержание раздела 4 аналогично содержанию раздела 5 первого варианта.
Оформление графической части ДП (плакатов)
Требования к графической части ДП, выполненного по данному варианту, являются аналогичными требованиям к ДП, выполненному по первому варианту.
Рекомендуемые структура и содержание дипломных проектов по созданию интеллектуальной системы
(Примерный вариант 3б)
Введение
1 Экономико-математическая постановка задачи, решаемой интеллектуальной системой
1.1 Идентификация проблемы
1.2 Концептуализация проблемы
1.3 Выбор метода формализации знаний и инструментальных средств разработки интеллектуальной системы
1.4 Перечень эксклюзивных компонентов интеллектуальной системы, подлежащих разработке
2 Проектирование интеллектуальной информационной системы
2.1 Теоретико-множественная постановка задачи
2.2 Проектирование базы знаний
2.3 Программная реализация интеллектуальной системы
2.3.1 Программная реализация базы знаний и эксклюзивных компонентов интеллектуальной системы
2.3.2 Описание интерфейса пользователя и схемы работы интеллектуальной системы
2.3.3 Разработка и описание справочной подсистемы по руководству пользователя
2.4 Анализ результатов тестирования интеллектуальной системы
3 Безопасность труда
3.1 Анализ и обеспечение безопасных условий труда
3.2 Расчёт интегральной балльной оценки категорий тяжести труда
3.3 Возможные чрезвычайные происшествия
4 Обоснование экономической эффективности от внедрения интеллектуальной информационной системы
4.1 Исходные данные для расчёта экономической эффективности системы
4.2 Расчёт стоимости интеллектуальной информационной системы
4.3 Определение затрат до внедрения интеллектуальной информационной системы
4.4 Определение затрат после внедрения интеллектуальной информационной системы
4.5 Расчёт экономического эффекта
Заключение
Список использованных источников
Приложения
Аналитическая часть
Содержание подразделов 1.1 – 1.4 данного варианта аналогично соответствующим подразделам варианта 3а.
Проектная часть
В подразделе 2.1 «Теоретико-множественная постановка задачи» описывается теоретико-множественная интерпретация задачи с учётом объектов предметной области, представленных в подразделе 1.2. Указанные в подразделе 1.2 объекты должны получить в подразделе 2.1 формализованное представление в соответствии с методом формализации знаний, выбранном в подразделе 1.3.
Подраздел 2.2 «Проектирование базы знаний» должен содержать описание структуры базы знаний с учётом выбранной модели представления знаний, технологии обработки данных и выбранного инструментального средства. В этом подразделе должно быть приведено описание каждого объекта базы знаний с указанием всех его атрибутов с выбранными типами данных или вызываемых процедур и указателей в случае выбора фреймовой модели представления знаний.
Подраздел 2.3 «Программная реализация интеллектуальной системы» содержит описание выбранного программного обеспечения и тех эксклюзивных программных компонент, которые были созданы разработчиком.
В пункт 2.3.1 «Программная реализация базы знаний и эксклюзивных компонентов интеллектуальной системы» должно быть приведено описание структуры базы знаний, приведённой в подразделе 2.2, уже на физическом уровне с учётом выбранного инструментального средства.
В этом же подпункте должно быть проведено описание механизмов, с помощью которых происходит формирование базы знаний на физическом уровне и описание алгоритмов, формирующих отношения объектов в разработанной базе знаний. В случае использования фреймовой модели представления знаний, например, обязательным является описание алгоритмов разработанных присоединённых процедур.
Пункт 2.3.2 «Описание интерфейса пользователя и схемы работы интеллектуальной системы» должен содержать описание этапов работы с интеллектуальной системой, структуры меню системы и особенности формирования выходных печатных форм, а также описание возможности задавать вопросы и получать на них ответы в удобной для пользователя форме.
Пункт 2.3.3 «Разработка и описание справочной подсистемы по руководству пользователя» должен содержать описание этапов разработки справочной системы, достоинства и обоснование полезности её наличия в интеллектуальной системе, а также основные особенности использования её пользователем для получения справочной информации при работе с разработанной системой.
Подраздел 2.4 «Анализ результатов тестирования интеллектуальной системы» содержит описание выбранных для контрольного примера входных данных и результирующие данных, полученные с помощью работы интеллектуальной системы. Также в этом подразделе должно быть приведено обоснование результата решения задачи, а также описаны возможности работы объяснительной компоненты для выдачи данных для контрольного примера.
Не нашли, что искали? Воспользуйтесь поиском: