ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
РЕГРЕССИОННЫЙ АНАЛИЗ
Предположим, что в результате вероятностного эксперимента E фиксируются две случайные величины X и Y. Тогда между X и Y может существовать статистическая зависимость.
Статистической зависимостью между СВ Х и СВ Y называется правило, которое каждому числу x Î Х ставит в соответствие условное распределение Y.
Пример 8. Пусть X - рост человека, Y - размеры обуви. Величина Х распределена на интервале 0,5м - 2,50 м. Каждому x Î Х соответствует некоторое распределение размеров обуви. Возьмем рост x = 175см, тогда, например, 37% людей с данным ростом имеет размер обуви 42, 25% - размер обуви 43 и так далее. Рассматривать для каждого значения x Î Х все распределение F(Y/X) на практике неудобно, поэтому вместо всего распределения обычно рассматривают математическое ожидание этого распределения, т.е. M(Y/X).
Зависимость среднего значения некоторой случайной величины от другой величины называют регрессией.
Заметим, что регрессия является обычной функциональной зависимостью. Уравнение регрессииимеет вид
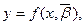 (12)
(12)
где 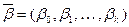 - совокупность некоторых параметров
- совокупность некоторых параметров
Для получения уравнения (12) необходимо иметь всю информацию о ГС. На практике такой информации обычно нет, есть только выборка, состоящая из n пар (xi, yi). На основании этой информации получают эмпирическое уравнение регрессии, являющееся некоторой оценкой уравнения (12)
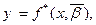 (13)
(13)
где 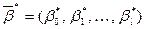 .
.
Для получения уравнения (13) поступают следующим образом
1) Результаты наблюдений (xi, yi) изображают в виде точек в декартовой или иной системе координат. Полученная точечная диаграмма называется корреляционным полем. С помощью корреляционного поля или других соображений выдвигается гипотеза о виде функции (13).
2) С помощью метода наименьших квадратов (МНК) или метода наибольшего правдоподобия находят по данным выборки значения параметров 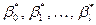 .
.
3) Проверяют согласие эмпирического уравнения регрессии с экспериментальными значениями.
Рассмотрим наиболее простой случай - линейную регрессию. В этом случае уравнение (13) примет вид
Yx =  + x. (14)
+ x. (14)
Найдем коэффициенты и по методу наименьших квадратов. Для этого рассмотрим сумму квадратов отклонений эмпирических значений y i от предполагаемых теоретических (описываемых формулой (14)).

Подберем неизвестные параметры и  так, чтобы функция S( , ) приняла минимальное значение. Для этого можно воспользоваться методами дифференциального исчисления. После ряда выкладок (см./2, 3/) получается линейная система уравнений для определения и :
так, чтобы функция S( , ) приняла минимальное значение. Для этого можно воспользоваться методами дифференциального исчисления. После ряда выкладок (см./2, 3/) получается линейная система уравнений для определения и :
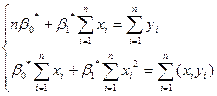 (15)
(15)
Решая эту систему, находим значения и . Подставляя эти значения в уравнение (14), получаем эмпирическое уравнение регрессии.
Затем с помощью эмпирического коэффициента корреляции или с помощью других статистик проводится проверка согласия полученного уравнения с экспериментальными данными (см./2, 3, 6/).
4 ДИСПЕРСИОННЫЙ АНАЛИЗ
Дисперсионным анализом называется раздел математической статистики, в котором проводится анализ количественных результатов, зависящих от качественных факторов. К примеру, дисперсионный анализ может быть использован для выявления совместного влияния экономических факторов, не поддающихся количественному измерению, на изучаемый экономический показатель и так далее.
Рассмотрим ряд примеров.
Пример 9. Пусть проводилось выборочное обследование производительности труда рабочих одинаковых профессий пяти ателье по ремонту обуви. Производительность выражена в относительных единицах по отношению к базовой, принятой за единицу. Требуется установить, существенно ли различаются средние значение производительности труда в этих ателье. Здесь количественный фактор – производительность труда зависит от качественного фактора – принадлежности групп рабочих к тому или иному предприятию, этот фактор имеет пять уровней. Если выяснится, что различие существенно, то в дальнейшем могут быть выявлены причины этого с целью повышения производительности труда в отстающих ателье.
Пример 10. Пусть выпускается один и тот же фасон платья из одной и той же ткани, но 6 разных цветов. Можно провести статистическое исследование спроса на эти платья в зависимости от цвета. Здесь качественный фактор – цвет платья, у этого фактора 6 уровней. Количественным фактором будет спрос на платья, данного цвета. Если выяснится, что фактор – цвет является существенным, можно изменить план производства, подстраиваясь под спрос, что приведет к улучшению экономических показателей предприятия.
Пример 11. Пусть в примере 2 выпускаются платья 6 ти разных цветов и 5 ти разных фасонов, все остальное такое же. Тогда у нас два качественных признака (фактора) – цвет и фасон и один количественный – спрос. В этом случае мы имеем дело с двухфакторным дисперсионным анализом. У первого фактора 6 уровней, у второго 5 уровней. Очевидно, что данный пример легко обобщается и можно рассматривать трехфакторную, четырехфакторную и так далее модели.
Метод дисперсионного анализа позволяет проверить, оказывают ли влияние на математическое ожидание случайных величин определенные факторы, которые можно произвольно изменять в ходе эксперимента, выбирать наиболее важные из них и оценивать степень их влияния.
Если на математическое ожидание оказывает влияние только один фактор, то соответствующей критерий значимости называется однофакторным дисперсионным анализом. Идея однофакторного дисперсионного анализа заключается в разбиении общей дисперсии случайной величины Х на два независимых слагаемых – факторную дисперсию и остаточную дисперсию. Факторная дисперсия порождается действием исследуемого фактора А, остаточная дисперсия зависит от ряда других факторов. Таким образом
Dобщ=Dфакт+Dост (16)
Если влияние исследуемого фактора существенно, то доля Dфакт в Dобщ достаточно велика. Сравнение факторной и остаточной дисперсии проводят с помощью критерия Фишера.
Рассматривается отношение
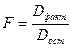 (17)
(17)
Чем больше это отношение, тем большее влияние оказывает фактор А на результат, если же это отношение близко к нулю, то влияние фактора малосущественное и им можно пренебречь. Это несколько неточное рассуждение будет уточнено в дальнейшем.
Сформулируем основные предположения и ограничения, лежащие в обосновании дисперсионного анализа в виде вероятностной модели.
Пусть некоторый количественный результат, по нашему предположению, зависит от некоторого качественного фактора А. Пусть фактор А может принимать к разных уровней (уровней, а не значений!). Результаты экспериментов разобьем на к групп в зависимости от уровней фактора. В каждую группу входят все эксперименты, отвечающие данному уровню фактора. Пусть количество экспериментов в каждой группе n i, i = 1,2 ,…,k. Обозначим результаты измерений через xij, где i – номер уровня фактора, j – номер результата измерения на данном уровне. Результаты измерения на каждом уровне i будем рассматривать как выборку из генеральной совокупности X i, распределенной по нормальному закону: X iÎ N (ai, si). Параметры ai, si неизвестны, но предполагается, что 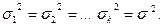 Выполнение этого равенства можно проверить по критерию Бартлетта /см 2/.
Выполнение этого равенства можно проверить по критерию Бартлетта /см 2/.
Представим результаты измерений хij в виде суммы двух слагаемых: xij=ai+eij, где ai – математическое ожидание случайной величины Хi, eij – случайная ошибка (остаток) характеризующая влияние на результаты xij неучтенных и случайных факторов. Предполагается, что, eij распределены нормально, точнее eij Î N( 0, s). В качестве eij можно рассматривать отклонение от средних размеров, вызванных действием многочисленных малых источников погрешностей, в том числе отклонение физико-химических свойств заготовок от номинала, биения вибраций механической части оборудования, вариации параметров электрической части оборудования, погрешности в работе электронной управляющей части и т.п.
Далее вычисляем по выборочным данным следующие величины.
1) Групповые средние арифметические
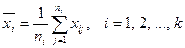 (18)
(18)
2) Общую среднюю арифметическую
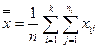 (19)
(19)
3) Факторную дисперсию по формуле
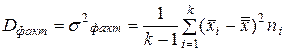 (20)
(20)
4) Остаточную дисперсию по формуле
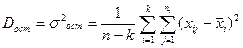 (21)
(21)
5) Выборочную статистику Fнабл по формуле
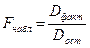
Теперь на основе имеющейся информации можно проверить нулевую гипотезу Н 0 – все математические ожидания одинаковые, против альтернативной гипотезы На – не все математические ожидания равны между собой.
Приступим к проверке нулевой гипотезы Н 0. Зададимся уровнем значимости и найдем табличное значение Fтабл(a, v 1, v 2 ), где v 1 =k- 1, v 2= n-k. Таблицы функции F (распределение Фишера) есть практически во всех учебниках по теории вероятностей и математической статистике. Величины v 1 и v 2 называются степенями свободы. Если Fнабл ³ Fтабл(a, v 1, v 2 ) то нулевая гипотеза Н 0 отклоняется, то есть считается, что фактор А является существенным. Если Fнабл< Fтабл(a, v 1, v 2 ), то принимается нулевая гипотеза, то есть считается, что фактор А не оказывает влияние на результат и им можно пренебречь.
Не нашли, что искали? Воспользуйтесь поиском: