ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Но для начала надо вспомнить, что такое многопоточность (aka multithreading).
Думаю, практически любой человек, работавший с Windows, знает, что это многозадачная ОС (нет, я почти не иронизирую, когда это пишу). Для простого смертного сие обычно означает, что он может одновременно паковать zip-архив, слушать музыку и при этом еще и набивать текст в Word. Если говорить строго формально, с точки зрения операционной системы, то в данном случае одновременно работает несколько процессов. Процесс — это, грубо говоря, «программа», главной особенностью которой является выделенное только ей одной собственное виртуальное пространство в памяти, изолированное от аналогичных пространств других процессов в системе (это сделано для того, чтобы ошибки одной программы не сказывались на работе других программ, работающих с ней одновременно). Так вот, на самом деле описанная выше иллюзия одновременной работы нескольких программ достигается не на уровне отдельных процессов, а на более низком уровне — на уровне так называемых потоков, или нитей (aka threads). Нить — это независимый поток исполнения команд процессором. Каждый процесс в системе имеет минимум один такой поток, но на практике обычно нитей больше чем одна. Для того, чтобы узнать, сколько у того или иного процесса нитей, можно воспользоваться «диспечером задач». Нажмите Ctrl-Alt-Del, выберите вкладку «процессы». В меню «вид», «выбрать столбцы» выберите столбец «счетчик потоков». Теперь можно узнать, у какого процесса сколько потоков. Например, в момент написания этой заметки у процесса explorer.exe (это всем известный «проводник») создано 11 нитей.
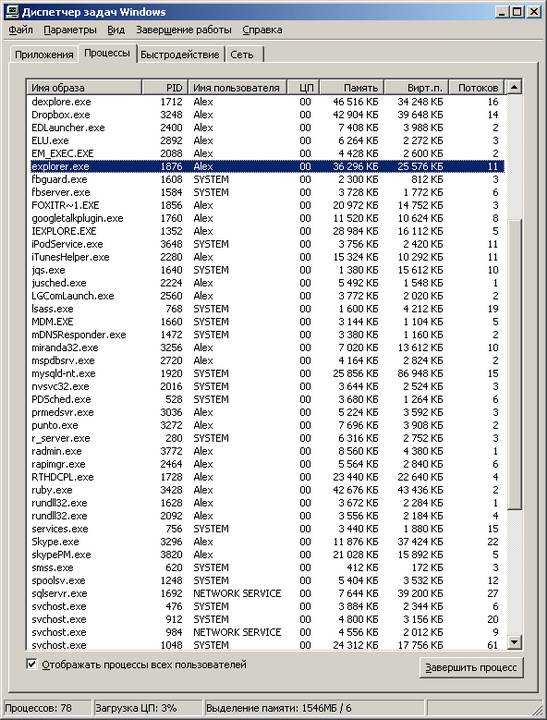
Концепция нитей и само понятие многопоточности были придуманы очень и очень давно. Еще во времена, когда все процессоры были исключительно одноядерными, а про частоты, на которых они при этом работали, даже смешно говорить. Придумано это было вот зачем. Во-первых, с помощью такого механизма операционная система создавала пользователю описанную выше иллюзию многозадачности. Во-вторых, есть целый ряд случаев, когда механизм очень сильно помогает программисту даже в рамках работы одной программы — именно поэтому типичный процесс в Windows редко имеет всего лишь один поток.
По второму пункту приведу несколько простых и понятных примеров.
Вы открыли несколько вкладок в браузере, и они грузятся одновременно. Процесс загрузки одной веб-страницы — действие независимое и самодостаточное, поэтому обычно загрузку каждой вкладки обслуживает как минимум один поток, специально созданный для этой цели.
Вы набираете или просматриваете текст в Word, при этом в фоне происходит проверка орфографии. Код проверки текста обычно обслуживается отдельным потоком, также специально для этого предназначенным.
Вы смотрите на окно музыкального плеера. Музыку играет отдельный поток. А визуализацию (например, спектр сигнала) рисует другой поток.

Многие даже не задумываются, насколько непросто «сделать красиво». И только мрачные программисты знают всю правду
Существуют и более сложные примеры. Так, в операционных системах реального времени (RTOS) с помощью механизма вытесняющей многопоточности определяют важность реагирования и обслуживания того или иного события во внешнем мире (речь при этом идет о приоритетах исполнения того или иного потока).
Еще раз замечу, что технология многопоточности была придумана очень давно и тогда же отлично себя зарекомендовала. На уровне программы, выполняющей несколько потоков, абсолютно все равно, сколько реальных физических ядер в компьютере, на котором она в данный момент выполняется.
Количество физических ядер в процессоре сказывается лишь на одном факте — сколько разных потоков одновременно (по-честному одновременно!) система может исполнять в один момент времени.
Если ядро у вас только одно, а потоков, которые необходимо исполнять, много, ОС создает иллюзию того, что эти потоки выполняются одновременно. Делается это самым банальным образом — какой-то небольшой промежуток времени (обычно порядка 50-100 мс) выполняется один поток, потом на точно такой же промежуток времени управление передается другому потоку и так далее. Если ядер у нас N, то наблюдается аналогичная картина — потоки по очереди выполняются на всех доступных ядрах. При этом надо помнить, что процесс переключения с потока на поток отнюдь не «бесплатен», и сам факт такого переключения снижает общий КПД потоков.

Интересная задачка для иностранных маркетологов: рассчитать — сколько эквивалентов мощности компьютера AGC, обслуживавшего первый полет человека на Луну, умещается в четырехъядерном кристалле Sandy Bridge при полном использовании его потенциала
Для чего программисты в своих приложениях используют потоки естественным образом, я написал выше, а сейчас хотел бы рассказать, как на практике распараллеливаются изначально линейные (монолитные) задачи.
Представим себе, что необходимо решить следующую задачу: посчитать среднюю температуру (нет, не по больнице) воздуха за последние 100 дней (и не спрашивайте меня, зачем программистам дают такие глупые задания!).
Наши исходные данные (сотня значений температуры) хранятся в массиве. Для прогульщиков информатики объясняю: массив — это такой упорядоченный набор данных, где по индексу (фактически, порядковому номеру элемента массива) можно получить значение этого элемента. Если наш массив называется temperatures, то temperatures[1] даст нам первое значение, а temperatures[100] — соответственно — последнее.
Все, что нам нужно сделать, чтобы решить эту очень сложную задачу, это просуммировать все значения в массиве и разделить их на 100 (именно так считается, если что, среднее арифметическое).
В коде это будет выглядеть примерно так:
temperatures[100] (по слухам, в этом массиве лежат наши значения температуры)
sum = 0 (переменная для накопления суммы всех элементов массива)
for i = 1 to 100 do sum = sum + temperatures[i] (i меняется от 1 до 100, таким образом, мы пробегаемся по каждому
элементу массива и добавляем его к нашей сумме)
result = sum / 100 (ответ — это наша сумма, деленная на 100)
print(result) (печатаем на экран результат!)
Теперь представим себе, что мы хотим решить нашу задачу в два потока.
Мы должны написать что-то в таком роде:
temperatures[100] (вы должны помнить, что это такое, из предыдущего примера)
sum1 = 0, sum2 = 0 (переменные для накопления суммы первой и второй половины массива)
thread1 = RunSumInThread(temperatures, 1, 50, sum1) (создать поток, который посчитает сумму элементов массива
temperatures от 1-го до 50-го и запишет результат в sum1)
thread2 = RunSumInThread(temperatures, 51, 100, sum2) (то же самое, но считаем элементы с 51 по 100-й и пишем в sum2)
WaitFor(thread1 and thread2) (дожидаемся, пока наши потоки thread1 и thread2 сделают свою грязную работу)
result = (sum1 + sum2) / 100 (старательно рассчитываем среднее, учитывая, что общая сумма элементов массива
есть sum1 + sum2)
print(result) (программа без print, как свадьба без мордобоя!)
Спешу вас обрадовать! Если вы поняли хотя бы треть из вышеприведенной абракадабры, то, при внезапном увольнении с текущей работы, с голода вы точно не помрете — можете смело идти работать программистом 1С!
Еще раз пробежимся по второму примеру (только не говорите, что вы не поняли даже первый). Смысл в том, что мы запускаем расчет суммы массива в два разных потока, один считает сумму первой половины массива (первые 50 элементов), второй — сумму второй половины (мне подсказывают, это элементы с 51-го по сотый).
Теперь самое интересное.
Программа будет работать равноуспешно на системе с любым количеством ядер. В случае если у вас всего лишь одно ядро, то программа будет работать чуть хуже, чем наш первый однопоточный вариант. Зато если у вас два ядра, то — теоретически — задачу вы посчитаете в два раза быстрее, так как в системе появляется два потока (главный поток, создавший эти два потока-задания, ложится спать, ожидая окончания выполнения потоков), каждый из которых можно отдать на исполнение физическому ядру процессора, то есть выполнять их одновременно. PROFIT!

Еще в мае прошлого года Intel показывала работающий прототип 48-ядерного процессора с архитектурой x86, которому вполне хватало воздушного охлаждения. То-то простора для программистских экспериментов!
Перед тем как выполнять все эти скучные температурные расчеты, вы можете спросить у операционной системы, на которой в данный момент работает ваша программа, а сколько, собственно, процессорных ядер у нее за душой? Она говорит — ядер у нас N. Тогда вы разбиваете исходный массив на N частей, считаете его в N потоков и тем самым загружаете процессор полностью! (Поздравляю! Теперь вы 1С-программист, который еще и умет писать эффективные многопоточные приложения!)
Но шутки в сторону! Практическая часть этой заметки подошла к концу, и мы с вами переходим к заключительной части.
Ложка дегтя
На первый взгляд, даже измученному сессией студенту-филологу может показаться, что писать программки для метеорологов, на 100% использующие возможности современных многоядерных процессоров, проще простого. Огорчу вас. Это, мягко говоря, не так.
Во-первых, само по себе многопоточное программирование довольно сложная и коварная штука, и у многих программистов есть проблемы с возможностью представить себе в голове, как программа будет работать на самом деле. Вследствие этого, многопоточные приложения обычно подвержены появлению в них очень тонких и неочевидных ошибок, которые трудно воспроизвести и обнаружить (любознательные бегут в поисковик с запросами deadlock и race condition).
Момент второй — переход от линейного решения задачи к многопоточному его варианту, который был бы при этом еще и эффективнее линейного, чаще всего есть весьма и весьма нетривиальная задача. Код такого решения почти всегда объемнее и сложнее линейного кода, а значит его дольше писать, сложнее отлаживать и дороже сопровождать. Более того, в мире существует огромное число задач, которые крайне неохотно поддаются распараллеливанию (даю подсказку, это такие, где каждый последующий шаг вычисления жестко завязан на результат работы предыдущего).

В общем, умение писать хорошо масштабирующие по количеству ядер программы — это целое искусство.
Лучшие умы человечества бьются над тем, чтобы упростить написание подобного рода программ. К примеру, есть целый класс языков программирования (так называемые функциональные языки), код на которых автоматически можно выполнять на любом количестве ядер. Одна проблема — языки эти довольно специфичны, они не очень хорошо подходят для решения целого ряда задач, и их доля на рынке колеблется в районе жалких пары процентов. Замечу, что, в противоположность экзотическим функциональным языкам программирования, существует целый ряд современных и популярных языков, которые вообще не поддерживают эффективную многопоточную модель. Например, к таким относится Python и Ruby.

Наверное, непросто будет устоять, когда такие красивые орудия маркетологов начнут убеждать нас в необходимости многоядерного смартфона?
А теперь хотелось бы вернуться к тому, с чего я начал этот материал — к теме двухъядерных мобильных устройств. Почему производители начали растить свои процессоры вширь, а не в высоту, я подробно описал в первой части, теперь надо объяснить — почему по этой же проторенной дорожке вынуждены пойти производители мобильных решений. Как мы знаем, потолок частоты, которого достигли сегодня в мобильных одноядерных системах с ядром ARM, чуть больше 1 ГГц. Вроде бы не так много, по меркам 3+ ГГц, за которые мы шагнули на десктопах. Однако в мобильном мире есть два важных нюанса, предопределивших переход на многоядерность именно на этом рубеже.
Первое — вопрос охлаждения. Мало того, что вы не можете использовать кулеры внутри корпуса современного смартфона, толщина которого составляет каких-то 10 мм, вы даже более-менее солидный радиатор вряд ли уместите.

Начинка двухъядерного смартфона LG нуждается в весьма внушительном по мобильным меркам радиаторе
Второе — энергопотребление. Тут постоянно ищется баланс между мощностью процессора и потребляемой мощностью. Повышать частоты на текущем витке технологических возможностей означает, что ваш любимый «гуглофон» будет умирать не через 6 часов активного использования, а через каких-то жалких два.
В общем, от прогресса никуда не убежишь — добрый дедушка Мур исправно дает каждые два года новую порцию транзисторов, и производители мобильных решений решили использовать ее для реализации второго ядра общего назначения (помимо всего прочего, немалая часть этих тразисторов в современных SoC идет на GPU, который, как мы помним, масштабируется куда как веселее).

Фантазируя по поводу смысла появления многоядерности в мобильных устройствах, маркетологи иногда придумывают совсем уж странные задачи, вроде транслирования HD-картинки с планшетного ПК на телевизор…
Не нашли, что искали? Воспользуйтесь поиском: