ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Алгоритм обнаружения голосовой активности говорящего (voice activity detector -VAD) по телекоммуникационным каналам связи
Л-Фараби атындағы Қазақ Ұлттық Университеті
Физика-техникалық факультеті
Атты дене физикасы және бейсызық физика кафедрасы
Ндірістік тәжірбиеден өту нәтижелері туралы есеп беру
Студент: Сағыныш Сағындық
Курс:4
Мамандығы: «5В071900- Радиотехника, электроника және телекоммуникациялар»
Кафедрадан практика жетекшісі:
Мұхаметқали Бауыржан
Алматы, 2016 ж.
Телекоммуникациялық байланыс каналы бойынша сөйлеушінің дауыстық белсенділігін (voice activity detector -VAD) табудың алгоритмі
Алгоритм обнаружения голосовой активности говорящего (voice activity detector -VAD) по телекоммуникационным каналам связи
План
Введение
VAD (Voice activity detector)
ЧАСТОТНЫЙ АНАЛИЗ
ДЕТЕКТОР РЕЧЕВОЙ АКТИВНОСТИ (VAD)
АЛГОРИТМ ОБНАРУЖЕНИЯ АКТИВНОСТИ ГОЛОСА
РЕАЛИЗАЦИЯ АЛГОРИТМОВ ОБНАРУЖЕНИЯ РЕЧЕВОЙ АКТИВНОСТИ (VAD)
Список материалов
VAD (англ. Voice Activity Detection), а также Silence Suppression (англ. подавление тишины) — обнаружение голосовой активности во входном акустическом сигнале для отделения активной речи от фонового шума или тишины. Голос, интерпретированный как шум, может порождать «вырезки» из разговора (chipping). Фон, интерпретируемый как голос, приводит к снижению эффективности компрессии (например, в DTX).
Преимущества и использование
При оцифровке голоса, фрагменты сигнала, классифицируемые как активная речь, могут в дальнейшем кодироваться и сжиматься любым аудиокодеком (например,CELP
) при использовании в ПО для различения в кодируемой речи человеческого голоса и фонового шума.Использование механизма VAD (или Silence Suppression) позволяет экономить на передаче данных по каналу связи, так как перерыв в речи (определяется по уровню сигнала) не оцифровывается и не кодируется и таким образом «пустые» пакеты с тишиной не передаются по сети. Это очень важно для пакетной передачи (каковой является передача в сетях TCP/IP), так как кроме самих данных каждый протокол всех уровней модели OSI (транспортный, сетевой и т.д.) дописывает свою собственную служебную информацию в каждый пакет с данными. В результате размер пакета значительно вырастает. Таким образом исключение «пустых» пакетов с мелкими шумами - простой способ экономить трафик и, как следствие, увеличить пропускную способность канала. По этой причине механизм VAD довольно часто применяется наряду с различными кодеками эффективного сжатия в IP-телефонии.
Недостатки и метод их устранения
Проблема VAD в том, что в результате подавления тишины (на самом деле звука низкого уровня) слушающий не слышит вообще никаких опознавательных сигналов (дыхания, сопения и других мелких шумов, сопровождающих живую речь). Это создаёт некоторые проблемы, ведь в обычной разговорной речи слышно всё. Отсутствие привычного шума во время воспроизведения голоса вызывает неприятные ощущения и снижает уровень восприятия, понимания.
Для решения данной проблемы на стороне второго абонента (или слушателя) может применяться эмуляция сопроводительных звуков, получившая название генерации комфортного шума (CNG) (обратный процесс для VAD).
Частотный анализ, частотный криптоанализ — один из методов криптоанализа, основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей как в открытом тексте, так и в шифротексте, которое, с точностью до замены символов, будет сохраняться в процессе шифрования и дешифрования.
Упрощённо, частотный анализ предполагает, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом в случае моноалфавитного шифрования если в шифротексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двубуквенным последовательностям), триграммам и т.д. в случаеполиалфавитных шифров.
Метод частотного криптоанализа известен с IX-го века (работы Ал-Кинди), хотя наиболее известным случаем его применения в реальной жизни, возможно, является дешифровка египетских иероглифов Ж.-Ф. Шампольоном в 1822 году. В художественной литературе наиболее известными упоминаниями являются рассказы «Золотой жук» Эдгара По, «Пляшущие человечки» Конан Дойля, а также роман «Дети капитана Гранта» Жюль Верна.
Начиная с середины XX века большинство используемых алгоритмов шифрования разрабатываются устойчивыми к частотному криптоанализу, поэтому он применяется, в основном, для обучения.
Voice activity detector (VAD) – детектор активности речи – технология сжатия речевого сигнала, за счет кодирования пауз. В телекоммуникационных системах связи наиболее дорогостоящим элементом являются не станционные сооружения: коммутаторы, усилительные пункты, системы энергообеспечения и т.п., а линейные сооружения, связывающие элементы сети. Системы телефонной связи не являются исключением. Поэтому эффективность системы связи определяется в первую очередь эффективностью использования линий связи. Для увеличения объемов передаваемой информации применяются множество различных методов, например, частотное и временное уплотнение сигналов. В системах голосовой связи, к которым относятся и системы сотовой связи применяются различные системы сжатия. Речь как природный источник информации обладает избыточностью, т.е. в ней содержится множество данных не несущих смысловую нагрузку. В связи с этим, было создано множество различных алгоритмов, которые устраняют избыточность речи, пытаясь выделить только значимые параметры речи. Обычно одновременно применяются несколько технологий компрессии речевых данных, и они объединяются под общим название голосовой кодек или вокодер. Наиболее распространенным способом сжатия речевых данных является удаление пауз между фразами, словами, отдельными звуками. Как показали многочисленные исследования, в речи (монологе) может содержаться до 50 % пауз, а в диалоге их объем может достигать 70%. Если учесть, что телефонное соединение – это, как раз, разговор двух лиц, то появляется возможность сжатия в 2-3 раза без потери качества. Именно на основании этого свойства и реализован механизм детектора активности речи.
Алгоритм VAD работает не сам по себе, а как одна из операций в процессе кодирования речевого сигнала перед его отправкой в телекоммуникационную систему. Обычно, наличие пауз определяется на основе анализа оцифрованных пакетов речевых данных, которые представляют собой отрезки сигнала. Как именно определить паузу, т.е. подобрать критерий, который позволил бы с высокой долей вероятности предсказывать, что данный пакет содержит паузу, а не речь – самый сложный аспект в алгоритме VAD. Ценой неверно принятого решения будет потеря части речевых данных. В наиболее простой реализации наличие паузы в наборе цифровых отсчетов определяется на основе сравнения суммарной энергии пакета речевых данных с некоторым пороговым значением, которое отделяет паузу от пакета с голосом. В таком случае необходимо подобрать порог так, чтобы не допустить слишком часто устранение ошибочных пауз, что может привести к потере полезных данных и ухудшению характеристик качества обслуживания (Quality of Service), а с другой стороны предотвратить многочисленный пропуск пауз, что может послужить снижению эффективности алгоритма VAD. Обычно, для определения пауз, применяется сложный алгоритм, учитывающий не только энергию пакета, но и энергию спектральных составляющих отрезка сигнала. Кроме того, в расчет берется и скорость изменения (нарастания или убывания) энергии данного отрезка с предыдущими. Также в случае со сложной шумовой обстановкой эффективность работы VAD может быть обеспечена периодической оценкой параметров фонового шума.
На приемной стороне, работает другая часть VAD цель которой восстановить исходный сигнал. Суть восстановления состоит не просто в заполнении пауз отрезками с нулевой энергией. Как показали исследования, человек ассоциирует тишину в динамике своего телефона как пропадание связи и создает дискомфорт. Поэтому паузы между голосовыми отрезками заполняют шумом. Здесь возможны два варианта. Во-первых, шум может создаваться генератором белого шума. Это наиболее эффективный способ, т.к. в данном случае от источника передается только информация о длительности пауз. В другом случае, пауза на передающей стороне сильно сжимается, но общие параметры, описывающие громкость, частоту и т.п. остаются. На приемной стороне генератор воссоздает паузу на основании этих дополнительных данных. Этот вариант требует передачу дополнительных объемов информации, т.е. снижает общую эффективность VAD, но с другой стороны позволяет добиться наибольшей естественности голоса, что практически убирает «следы» работы детектора активности речи. На практике, как правило, используют второй вариант пусть более затратный, но и более комфортный.
Алгоритм VAD используется практически во всех телекоммуникационных системах, где передается речь в цифровом виде. В частности, он нашел широкое применение в технологии VoIP, ТфОП, ISDN, безусловно, в сотовых системах связи начиная со второго поколения. Увеличение эффективности работы системы, доступное и использованием VAD позволяет прогнозировать и дальнейшее его применение, а также продолжение работ по поиску более совершенного механизма детектирования пауз в речи.
Детектор речевой активности (VAD)
Для шумоподавления используется устройство детектирования голосовой активности (Voice Activity Detection, VAD). VAD представляет собой апаратний или программный модуль, который фиксирует голос на входном акустическом канале и отделяет его от фонового шума. VAD также способствует экономии ресурсов канала: если речевой сигнал в данный момент времени не поступает, то данные в сеть не передаются. В противном случае, при отсутствии VAD, в сети передаются данные о шуме, который увеличивает объем передаваемой информации в канале.
Область применения детекторов речевой активности также включает устройства для аудио конференций, слуховые аппараты, бортовые системы безопасности полетов. Типовая структурная схема VAD изображена на рисунке 2.

Рисунок 2 – Структурная схема VAD
На вход системы поступает входящий речевой сигнал с микрофона f(t). Элемент «Определение наличия шума» определяет наличие шума во входном сигнале. Эта процедура выполняется с помощью различных алгоритмов обнаружения порога шума и речи. Примером являются алгоритмы, основанные на информационном подходе (применение расчета энтропии сигнала) или статистической модели (постановка гипотез о наличии шума или языка). После того, как шум обнаружено, рассчитывается его спектр и происходит вычитание спектра шума от спектра входного сигналу. На выходе системы получаем сигнал f '(t), который содержит только язык.
Общим свойством VAD-алгоритмов является то, что они включают в себя обучение (вычисление характеристик шума) и спектральное вычитание. Чаще всего в качестве признаков, определяющих начало и конец слова, избираемых энергетические и спектральные характеристики сигнала, а также число переходов через нуль [ 8–9 ].
Модель VAD с использованием вейвлет-преобразования была разработана в среде matlab (Приложение А). Также использовался wavelet toolbox данной среды. На вход модели поступает зашумленный звуковой wav сигнал с частотой дискретизации 44100 Гц – это слова «you'll see very soon», произнесенные женским голосом.
Длительность сигнала – 3 секунды. Каждый фрейм содержит 454 отсчета (20 мс при частоте дискретизации 44100 Гц). В качестве шума в программе используется функция matlab awgn с вариативным равным отношение сигнал-шум (SNR).
Алгоритм работы модели выполняется в три этапа (рис. 3).

Рисунок 3 – Схема работы модели
На блок «Обучение системы» поступает входящий зашумленный сигнал f (t). В качестве шума используется Гауссов белый шум. Известно, что первые пять фреймов сигнала содержат языка и представляют собой шум. На этом этапе определяется среднее значение спектральной энтропии H(f_threshold) первых пяти фреймов и обозначается как предельное.
В блоке «Классификация фреймов» рассчитывается спектральная энтропия следующих фреймов и сравнивается по предельному значению:

где  – спектральная плотность k-ой компоненты спектра, Xk – спектральные коэффициенты БПФ, или вейвлет-коэффициенты [ 4–5 ].
– спектральная плотность k-ой компоненты спектра, Xk – спектральные коэффициенты БПФ, или вейвлет-коэффициенты [ 4–5 ].


где n – спектральная энтропия n-го фрейма.
В блоке «Вычитание спектра шума» происходит вычитание детализирующих коэффициентов шума из входного сигнала.
В качестве критерия эффективности в работе выступает вероятность верного определения фрейма, содержащий голос, при заданном уровне отношения сигнал- шум:

В ходе эксперимента изменялось значение отношения сигнал-шум от 0 до 50 dB с шагом 5 dB. Результаты исследования изображены на рисунке 4.

Рисунок 4 – График зависимости вероятности верного определения голосового фрейма P_voice от отношения сигнал-шум (SNR)
Как видно из результатов исследования, выигрыш применения вейвлет-преобразования вместо быстрого преобразования Фурье в энтропийном методе распознавания речи составляет до 20%. Этот выигрыш замечается при относительно шумном сигнале – при отношении сигнал-шум менее, чем 15 dB. Однако, более комплексный подход расчета порога детектора G.729 дает выигрыш до 20% над предложенной в данной работе системой.
Алгоритм обнаружения активности голоса (Voice Activity Detection, далее VAD) очень важный метод в приложениях обработки речи и аудио. Эффективность большинства, если не всех методов обработки речи/аудио сильно зависит от эффективности применяемого алгоритма VAD. Идеальный детектор активности голоса должен быть независимым от области применения приложения, от уровня шума и быть наименее зависимым от максимума параметров приложения, в котором его используют. В этой статье предлагается близкий к идеальному алгоритм VAD, который одновременно легок в реализации и устойчив к шуму. Предложенный метод использует такие кратковременные характеристики как Spectral Flatness (SF) (спектральная плоскостность, ровность) и Short-term Energy, что делает метод целесообразным для применения в реальном времени. Этот метод был проверен на нескольких записях с разным уровнем шума и сравнивался с недавно преложенными методами. Эксперименты показали удовлетворительные результаты при разных уровнях шума.
Voice Activity Detection(VAD) то-есть обнаружение тишины в речевом или аудио сигнале — это очень важная задача для многих приложений, которые работаю с аудио или речью, включая кодирование, распознавание, повышения разборчивости речи, и индексации аудио. Например, в стандарте GSM 729 [1] используется два VAD модуля для кодирования с разным количеством бит в сэмпле. Устойчивость VAD к шуму также очень важна для распознавания речи (Automatic Speech Recognition ASR). Хороший детектор улучшит точность и скорость любого ASR в шумном окружении.
Согласно [2], необходимые характеристики для идеального детектора активности голоса это: надежность, устойчивость, точность, адаптивность, простота, возможность применения в реальном времени, без информации о присутствующем шуме. Достичь устойчивости к шуму сложнее всего. В условиях высокого SNR (Signal-to-noise ratio), простейшие VAD алгоритмы работают удовлетворительно, но при условиях низкого SNR все алгоритмы VAD деградируют до определенной степени. В тоже время, алгоритм VAD должен оставаться простым, для удовлетворения требования применимости в реальном времени. Поэтому простота и устойчивость к шуму — это две существенные характеристики практичного детектора активности речи.
Было предложено много алгоритмов VAD, главное отличие которых в используемых характеристиках. Среди всех характеристик, Short-term Energy и zero-crossing rate из-за своей простоты использовались чаще. Однако, они сильно деградируют при наличии шумов. Для того что бы исправить этот недостаток были предложены разные устойчивые акустические характеристики на основе — функции автокорреляции [3, 4], спектра(spectrum based) [5], мощности на узкополосном отрезке (power in the band-limited region) [1, 6, 7], MFCC (Mel-frequency Cepstral Coefficients [4] — Кепстральные коэффициенты тональной частоты. Почитать можно в книге spbu), дельт спектральных частот (delta line spectral frequencies)[6] и статистик высшего порядка [8]. Эксперименты показали, что использование этих характеристик приводит к увеличению устойчивости VAD к шумам. В некоторых работах предлагается использование разных характеристик в комбинации с некоторыми моделирующими алгоритмами как CART (Classification and Regression Tree)[9] и ANN (Artificial Neural-Network) [10], однако эти алгоритмы по сложности сравнимы с самим VAD.
C другой стороны, некоторые методы используют модели шумов [11], или используют улучшенный спектр речи, полученный после статистической фильтрации шумов фильтром Винера (Wiener filter) [7, 12]. Большинство характеристик предполагают наличие стационарного шума в течении определенного периода, поэтому они чувствительны к изменениям в SNR обрабатываемого сигнала. Некоторые работы предлагают вычисление шума и адаптацию для улучшения устойчивости VAD [13], но эти методы имеют большую вычислительную сложность.
Также, существуют стандарты VADs, которые используются для создания новых методов детектирования. Среди них GSM 729 [1], ETSI AMR [14] и AFE [15]. Например, стандарт GSM 729 использует линейный спектр пары частот, full-band energy и low-band energy, zero-crossing rate и применяет классификатор с использованием фиксированных границ в ограниченном пространстве [1].
В этой работе предложен алгоритм VAD, который одновременно легок в реализации и может быть использован для обработки речи/аудио в реальном времени, а также дает удовлетворительную устойчивость к шумам. В секции 3 детально разбирается алгоритм предложенного VAD.
2. SHORT-TERM FEATURE (кратковременные характеристики)
В предложенном методе мы используем три разных характеристики для каждого фрэйма. Первая характеристика это краткосрочная энергия (Е). Энергия — наиболее часто используемая характеристика в определении речи/тишины. Однако, она становится неэффективной в условиях шума, особенно при низких SNR. Поэтому, мы используем еще две характеристики, которые вычисляются из частот.
Вторая характеристика это мера спектральной плоскостности (SFM — Spectral Flatness Measure). Мера зашумленности спектра хорошо себя показывает в Голосовом/Неголосовом детекритовании и обнаружении тишины.
Считается SFM по следующей формуле:
SMFdb= 10log10(Gm / Am)
Где Am и Gm это соответственно среднее арифметическое и среднее геометрическое спектра речи.
Кроме этих двух характеристик было обнаружено, что составляющая фрэйма речи с преобладающими частотами (most dominant frequency component) может быть очень полезна для различения фрэймов с речью и тишиной. В этой работе эта характеристика обозначена через F. Она легко вычисляется через нахождения такой частоты, которая соответствует максимальному значению величины спектра | S(k) |.
В предложенном методе для детектирования голосовой активности все три характеристики вычисляются одновременно для каждого фрейма.
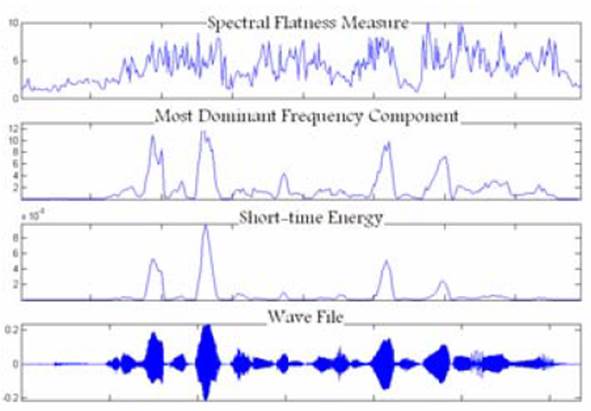
Изображение 1. Значения характеристик на чистом речевом сигнале

Изображение 2. Значение характеристик на сигнале, поврежденном белым шумом

Изображение 3. Значение характеристик на сигнале, поврежденном шумом лепета
Изображения 1-3 представляют эффективность этих трех характеристик на чистом и поврежденном шумом сигнале.
Реализация алгоритмов обнаружения речевой активности (VAD)
Реализация алгоритмов обнаружения речевой активности (VAD) базируется на следующих положениях:
· речь является нестационарным сигналом. Форма ее спектра обычно изменяется через короткие отрезки времени – 20…30 с.;
· фоновый шум обычно стационарен на более длинном отрезке времени, немного изменяясь со временем;
· уровень речевого сигнала обычно выше уровня фонового шума (в противном случае речь была бы неразборчивой).
Структурная схема VAD приведена на
Рис.3. Ее работа основана на различии спектральных характеристик речи и шума. VAD определяет спектральные отклонения входного воздействия от спектра фонового шума. Это осуществляется инверсным фильтром, коэффициенты которого устанавливаются применительно к воздействию на входе фонового шума.
При наличии на входе речи и шума инверсный фильтр осуществляет подавление компонентов шума и снижает его интенсивность. Энергия смеси сигнала и шума на выходе инверсного фильтра сравнивается с порогом, который устанавливается в период воздействия на входе только шума. Этот порог находится выше уровня энергии шумового сигнала. Превышение порогового уровня принимается за наличие на входе реализации сигнал+шум.

Рис. 3. Структурная схема VAD
Исходными данными для работы алгоритма определения голосовой активности являются  коэффициент автокорреляции и четыре коэффициента запаздывания долгосрочного предсказателя (один для каждого из четырех подфреймов), которые вычисляются на каждом фрейме кодером источника RPE-LTP (где
коэффициент автокорреляции и четыре коэффициента запаздывания долгосрочного предсказателя (один для каждого из четырех подфреймов), которые вычисляются на каждом фрейме кодером источника RPE-LTP (где  – порядок LPC-анализа). Решение VAD принимается для каждого фрейма в конце текущей последовательности процессов обработки.
– порядок LPC-анализа). Решение VAD принимается для каждого фрейма в конце текущей последовательности процессов обработки.
Остаточная энергия LPC может быть определена при инверсной LPC-фильтрации текущего фрейма входного сигнала с дальнейшим суммированием площадей остаточного сигнала. Процесс включает в себе два этапа обработки: инверсную LPC-фильтрацию и вычисление энергии. Для повышения эффективности вычислений эти два процесса могут быть объединены в один следующим образом:

| (1) |
где  – остаточная энергия;
– остаточная энергия;  и
и  – коэффициенты автокорреляции входного сигнала и средние LPC-коэффициенты, задаваемые соответственно:
– коэффициенты автокорреляции входного сигнала и средние LPC-коэффициенты, задаваемые соответственно:
 
| (2) |
где N – размер фрейма анализа (160 выборок);

| (3) |
где  – k -й средний коэффициент. Уравнение (1.2) вычисляется кодером источника для определения его собственных LPC-параметров, и для его использования в алгоритме VAD дополнительных вычислений не требуется.
– k -й средний коэффициент. Уравнение (1.2) вычисляется кодером источника для определения его собственных LPC-параметров, и для его использования в алгоритме VAD дополнительных вычислений не требуется.
Так как спектральные характеристики фонового шума приняты стационарными на большом отрезке времени, в алгоритме VAD используется усреднение значений автокорреляционной функции, относящихся к последнему фрейму. С этой целью два набора коэффициентов автокорреляции вычисляются следующим образом:

| (4) |
где h представляет текущий фрейм; h–1 – предыдущий фрейм и так далее до К–1 фрейма; К – число фреймов, используемых для вычисления средних значений, обычно принимается равным четырем.
Средние LPC-параметры  вычисляются на основе средних коэффициентов автокорреляции
вычисляются на основе средних коэффициентов автокорреляции 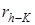 (средние значения коэффициентов автокорреляции К фреймов определены ранее) с использованием алгоритма Дурбина. Коэффициенты автокорреляции средних LPC-параметров затем вычисляются с использованием
(средние значения коэффициентов автокорреляции К фреймов определены ранее) с использованием алгоритма Дурбина. Коэффициенты автокорреляции средних LPC-параметров затем вычисляются с использованием

| (5) |
Для определения, является ли сигнал стационарным или нет, средний спектр, представленный усредненными автокорреляционными LPC-параметрами  , сравнивается со средними значениями автокорреляции сигнала
, сравнивается со средними значениями автокорреляции сигнала  , вычисленными в текущем фрейме с использованием уравнения
, вычисленными в текущем фрейме с использованием уравнения

| (6) |
Если разница между  и
и  больше, чем установка порога, текущей фрейм считается нестационарным, если же меньше, текущий фрейм объявляется стационарным.
больше, чем установка порога, текущей фрейм считается нестационарным, если же меньше, текущий фрейм объявляется стационарным.
Так как речевой сигнал может быть спектрально стационарным длительное время, для различения речи и фонового шума в качестве индикатора используется периодичность речи. Значения задержек LTP для четырех подфреймов сравниваются с наименьшим значением задержки. Если оставшиеся задержки очень близки к минимальной задержке, фрейм считается периодическим, в противном случае — апериодическим.
Перед принятием окончательного решения путем сравнения с пределом энергетического порога  выполняется проверка для выяснения, не нужно ли обновить значение порога. Порог обновляется, если изменение входного сигнала очень мало, что очень легко подтверждается проверкой значения
выполняется проверка для выяснения, не нужно ли обновить значение порога. Порог обновляется, если изменение входного сигнала очень мало, что очень легко подтверждается проверкой значения  , или если высока вероятность появления неречевого сигнала, что проверяется с использованием ранее вычисленной информации о периодичности и стационарности. В первом случае, когда меньше установленного значения
, или если высока вероятность появления неречевого сигнала, что проверяется с использованием ранее вычисленной информации о периодичности и стационарности. В первом случае, когда меньше установленного значения 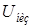 , это показывает на отсутствие сигнала на входе. Энергетический порог устанавливается на его нижний предел, и VAD принимает решение. Во втором случае, когда выше , для решения о следующем шаге используются вычисленные ранее флаги стационарности и периодичности стац и период. Если флаги стац и период показывают, что текущий входной фрейм стационарный и апериодический, выполняется адаптация. Однако для уверенности, что сигнал не временно стационарный, проверяется несколько (обычно восемь) фреймов, чтобы определить, остаются ли условия для адаптации до того, как эта адаптация будет выполнена. В этом случае кроме обновления энергетического порога средние LPC параметры которые используются для инверсного фильтра, также обновляются на вновь вычисленный набор
, это показывает на отсутствие сигнала на входе. Энергетический порог устанавливается на его нижний предел, и VAD принимает решение. Во втором случае, когда выше , для решения о следующем шаге используются вычисленные ранее флаги стационарности и периодичности стац и период. Если флаги стац и период показывают, что текущий входной фрейм стационарный и апериодический, выполняется адаптация. Однако для уверенности, что сигнал не временно стационарный, проверяется несколько (обычно восемь) фреймов, чтобы определить, остаются ли условия для адаптации до того, как эта адаптация будет выполнена. В этом случае кроме обновления энергетического порога средние LPC параметры которые используются для инверсного фильтра, также обновляются на вновь вычисленный набор 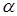 .
.
После предшествующих этапов обработки путем сравнения с принимается окончательное решение. Если  , то принимается решение о наличии речи. В противном случае, когда принимается решение о переходе в состояние «не-речи», выход VAD используется для сообщения этой информации контроллеру прерывистой передачи.
, то принимается решение о наличии речи. В противном случае, когда принимается решение о переходе в состояние «не-речи», выход VAD используется для сообщения этой информации контроллеру прерывистой передачи.
Формирование комфортного шума управляется речевым кодером. Когда VAD обнаружит, что разговор прекращен, передатчик остается включенным еще в течение следующих пяти фреймов. Во время первых четырех фреймов характеристики фонового шума оцениваются путем усреднения коэффициента усиления и коэффициентов фильтра LPC-анализа. Эти усредненные значения передаются в следующем пятом фрейме, где и содержится информация о комфортном шуме (SID-фрейм). Таким образом, поток информации, создаваемый разговором, закодированным с использованием механизма VAD, является прерывистым, и периоды передачи информации чередуются с периодами простоя.
Сети с коммутацией пакетов не обеспечивают гарантированной пропускной способности, поскольку не обеспечивают гарантированного пути между точками связи. C точки зрения передаваемого трафика качество обслуживания пакетной сети есть мера производительности, характеризующаяся следующими основными параметрами:
· Односторонняя задержка передачи – характеризует время доставки сетью одного пакета.
· Межпакетная вариация задержки (джитер – jitter) - характеризует время доставки сетью последовательности пакетов.
Процент потери пакетов – характеризует целостность передачи трафика сетью
Список материалов
· [1] A. Benyassine, E. Shlomot, H. Y. Su, D. Massaloux, C. Lamblin and J. P. Petit, «ITU-T Recommendation G.729 Annex B: a silence compression scheme for use with G.729 optimized for V.70 digital simultaneous voice and data applications,» IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] M. H. Savoji, «A robust algorithm for accurate end pointing of speech,» Speech Communication, pp. 45–60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “Robust speech recognition in noisy environments: The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] R. E. Yantorno, K. L. Krishnamachari and J. M. Lovekin, “The spectral autocorrelation peak valley ratio (SAPVR) – A usable speech measure employed as a co-channel detection system,” Proc. IEEE Int. Workshop Intell. Signal Process. 2001.
Гольдштейн Б.С., Пинчук А.В., Суховицкий А.Л. "IP-Телефония". 2001. [1] [2] Страницы 75-76 (русс. яз.)
· Статья VAD на сайте "Сотовая Связь: История, стандарты, технология"
· DMA minimum performance standards for discontinuous transmission operation of mobile stations TIA doc. and database IS-727, June 1998. (англ. яз)
· M.Y. Appiah, M. Sasikath, R. Makrickaite, M. Gusaite, "Robust Voice Activity Detection and Noise Reduction Mechanism", Institute of Electronics Systems, Aalborg University (англ. яз)
· X.L. Liu, Y. Liang, Y.H. Lou, H. Li, B.S. Shan, Noise-Robust Voice Activity Detector Based on Hidden Semi-Markov Models, Proc. ICPR'10, 81-84. (англ. яз)
| <== предыдущая лекция | | | следующая лекция ==> |
| Информационное обеспечение дисциплины | | | научно-исследовательского семинара |
Не нашли, что искали? Воспользуйтесь поиском: