ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Закрытое хеширование
При закрытом хешировании в таблице сегментов хранятся непосредственно элементы словаря, а не заголовки списков. Поэтому в каждом сегменте может храниться только один элемент словаря. При закрытом хешировании применяется методика повторного хеширования. Если произойдет попытка поместить элемент х в сегмент с номером h(x), который уже занят другим элементом (такая ситуация называется коллизией), то в соответствии с методикой повторного хеширования выбирается последовательность других номеров сегментов  куда можно поместить элемент х. Каждое из этих местоположений последовательно проверяется, пока не будет найдено свободное. Если свободных сегментов нет, то таблица заполнена, и элемент х вставить в нее нельзя.
куда можно поместить элемент х. Каждое из этих местоположений последовательно проверяется, пока не будет найдено свободное. Если свободных сегментов нет, то таблица заполнена, и элемент х вставить в нее нельзя.
Рассмотрим пример заполнения хеш-таблицы в случае закрытого хеширования (рис. 4).

Рис. 4 – Частично заполненная хеш-таблица
Здесь В=8 и ключи a, b, c, d имеют хеш-значения h(a)=3, h(b)=0, h(c)=4, h(d)=3. Для добавления в таблицу элемента d применим методику линейного хеширования, когда 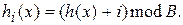 Тогда, если сегмент 3 уже занят, то проверяются на занятость сегменты 4, 5, 6, 7, 0, 1, 2 (именно в таком порядке). 5-ый сегмент оказался первым пустым сегментом, поэтому элемент d был вставлен в него
Тогда, если сегмент 3 уже занят, то проверяются на занятость сегменты 4, 5, 6, 7, 0, 1, 2 (именно в таком порядке). 5-ый сегмент оказался первым пустым сегментом, поэтому элемент d был вставлен в него
При поиске элемента х необходимо просмотреть все адреса пока не будет найден х, или пока не встретится пустой сегмент. Покажем это, введя условие, что в словаре не допускается удаление элементов. Пусть 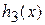 – первый пустой сегмент. В такой ситуации невозможно нахождение элемента х в сегментах
– первый пустой сегмент. В такой ситуации невозможно нахождение элемента х в сегментах 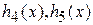 и далее, т.к. х вставляется в первый свободный сегмент, следовательно, он находится до сегмента .
и далее, т.к. х вставляется в первый свободный сегмент, следовательно, он находится до сегмента .
При заполнении таблицы могут возникать коллизии, для борьбы с которыми разработаны специальные методы, которые в основном сводятся к методам "цепочек" и "открытой адресации". Ключи, выдающие одинаковые адреса в таблице, называются ключи-синонимы.
В методе цепочек для разрешения коллизий во все записи вводятся указатели, используемые для организации списков – "цепочек переполнения". В случае возникновения коллизии при заполнении таблицы в список для требуемого адреса хеш-таблицы добавляется еще один элемент.
Поиск в хеш-таблице с цепочками переполнения осуществляется следующим образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется последовательный поиск в списке, связанном с вычисленным адресом. Процедура удаления из таблицы сводится к поиску элемента и его удалению из цепочки переполнения. На рис. 5 показана схема разрешения коллизий методом цепочек при добавлении элемента.
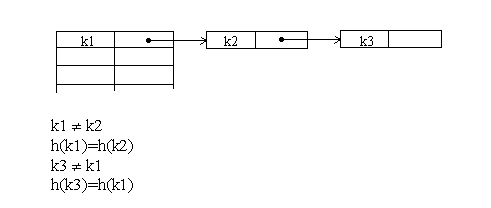
Рис. 5 – Разрешение коллизий при добавлении элементов
Метод открытой адресации состоит в том, чтобы, пользуясь каким-либо алгоритмом, обеспечивающим перебор элементов таблицы, просматривать их в поисках свободного места для новой записи.
Линейное опробование сводится к последовательному перебору элементов таблицы с некоторым фиксированным шагом
a=h(key) + c* i,
где i – номер попытки разрешить коллизию. При шаге равном единице происходит последовательный перебор всех элементов после текущего.
Квадратичное опробование отличается от линейного тем, что шаг перебора элементов нелинейно зависит от номера попытки найти свободный элемент
a = h(key2) + c* i + d* i 2 .
Благодаря нелинейности такой адресации уменьшается число проб при большом числе ключей-синонимов. Однако даже относительно небольшое число проб может быстро привести к выходу за адресное пространство небольшой таблицы вследствие квадратичной зависимости адреса от номера попытки. На рис. 6 показано разрешение коллизий методом открытой адресации.
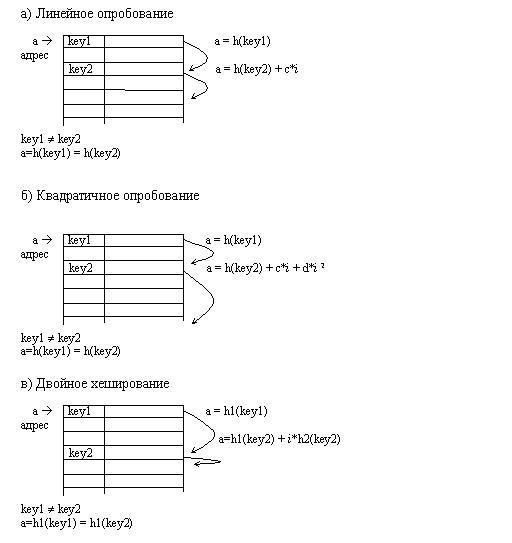
Рис. 6 – Разрешение коллизий при добавлении элементов методами
открытой адресации
Алгоритмы работы с хеш-таблицами методами открытой адресации
Опишем алгоритмы вставки и поиска элементов для метода линейного опробования.
Вставка
i = 0
a = h(key) + i*c
Если t(a) = свободно, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
Поиск
i = 0
a = h(key) + i*c
Если t(a) = key, то стоп элемент найден
Если t(a) = свободно, то стоп элемент не найден
i = i + 1, перейти к шагу 2
Аналогичным образом можно было бы сформулировать алгоритмы добавления и поиска элементов для любой схемы открытой адресации. Отличия будут только в выражении, используемом для вычисления адреса.
Процедура удаления в данном случае не будет являться обратной процедуре вставки. Элементы таблицы находятся в двух состояниях: свободно и занято. Если удалить элемент, переведя его в состояние свободно, то после такого удаления алгоритм поиска будет работать некорректно. Предположим, что ключ удаляемого элемента имеет в таблице ключи-синонимы. Тогда, если за удаляемым элементом в результате разрешения коллизий были размещены элементы с другими ключами, то поиск этих элементов после удаления всегда будет давать отрицательный результат, так как алгоритм поиска останавливается на первом элементе, находящемся в состоянии свободно.
Скорректировать сложившуюся ситуацию можно различными способами. Самый простой из них состоит в том, чтобы выполнять поиск элемента не до первого свободного места, а до конца таблицы. Однако такая модификация алгоритма сведет на нет весь выигрыш в ускорении доступа к данным, который достигается в результате хеширования.
Другой способ сводится к тому, чтобы проследить адреса всех ключей-синонимов для ключа удаляемого элемента и при необходимости переразместить соответствующие записи в таблице. Скорость поиска после такой операции не уменьшится, но затраты времени на само переразмещение элементов могут оказаться очень значительными.
Существует подход, который свободен от перечисленных недостатков. Его суть состоит в том, что для элементов хеш-таблицы добавляется состояние удалено. Данное состояние в процессе поиска интерпретируется как занято, а в процессе записи как свободно.
Рассмотрим алгоритмы вставки, поиска и удаления для хеш-таблицы, имеющей три состояния элементов.
Вставка
i = 0
a = h(key) + i*c
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
Удаление
i = 0
a = h(key) + i*c
Если t(a) = key, то t(a) =удалено, стоп элемент удален
Если t(a) = свободно, то стоп элемент не найден
i = i + 1, перейти к шагу 2
Поиск
i = 0
a = h(key) + i*c
Если t(a) = key, то стоп элемент найден
Если t(a) = свободно, то стоп элемент не найден
i = i + 1, перейти к шагу 2
Алгоритм поиска для хеш-таблицы, имеющей три состояния, практически не отличается от алгоритма поиска без учета удалений. Разница заключается в том, что при организации самой таблицы необходимо отмечать свободные и удаленные элементы. Это можно сделать, зарезервировав два значения ключевого поля. Другой вариант реализации может предусматривать введение дополнительного поля, в котором фиксируется состояние элемента. Длина такого поля может составлять всего два бита, что вполне достаточно для фиксации одного из трех состояний. На языке TurboPascal данное поле удобно описать типом Byte или Char.
Очевидно, что по мере заполнения хеш-таблицы будут происходить коллизии, и в результате их разрешения методами открытой адресации очередной адрес может выйти за пределы адресного пространства таблицы. Чтобы это явление происходило реже, можно пойти на увеличение длины таблицы по сравнению с диапазоном адресов, выдаваемым хеш-функцией. С одной стороны это приведет к сокращению числа коллизий и ускорению работы с хеш-таблицей, а с другой – к нерациональному расходованию адресного пространства. Даже при увеличении длины таблицы в два раза по сравнению с областью значений хеш-функции нет гарантии того, что в результате коллизий адрес не превысит длину таблицы. При этом в начальной части таблицы может оставаться достаточно свободных элементов. Поэтому на практике используют циклический переход к началу таблицы.
Рассмотрим этот способ на примере метода линейного опробования. При вычислении адреса очередного элемента можно в качестве адреса взять остаток от целочисленного деления адреса на длину таблицы n.
Вставка
i = 0
a = (h(key) + c*i) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
В данном алгоритме не учитывается возможность многократного превышения адресного пространства. Более корректным будет алгоритм, использующий сдвиг адреса на 1 элемент в случае каждого повторного превышения адресного пространства. Это увеличивает вероятность поиска свободных элементов в случае повторных циклических переходов к началу таблицы.
Вставка
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
При большой заполненности таблицы возникают частые коллизии и циклические переходы в начало таблицы. При неудачном выборе хеш-функции происходят аналогичные явления. В наихудшем случае при 100% заполнении таблицы алгоритмы циклического поиска свободного места приведут к зацикливанию. Поэтому при использовании хеш-таблиц необходимо стараться избегать очень плотного заполнения таблиц. Обычно длину таблицы выбирают из расчета двукратного превышения предполагаемого максимального числа записей. Не всегда при организации хеширования можно правильно оценить требуемую длину таблицы, поэтому в случае большой заполненности таблицы может понадобиться рехеширование. В этом случае увеличивают длину таблицы, изменяют хеш-функцию и переупорядочивают данные.
Оценку плотности заполнения таблицы целесообразно выполнять косвенным образом – по числу коллизий во время одной вставки. Достаточно определить некоторый порог числа коллизий, в случае превышения которого следует провести рехеширование. Кроме того, такая проверка гарантирует невозможность зацикливания алгоритма в случае повторного просмотра элементов таблицы. Рассмотрим алгоритм вставки, реализующий предлагаемый подход.
Вставка
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
Если i > m, то стоп требуется рехеширование
i = i + 1, перейти к шагу 2
Удаление
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = key, то t(a) =удалено, стоп элемент удален
Если t(a) = свободно или i>m, то стоп элемент не найден
i = i + 1, перейти к шагу 2
Поиск
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = key, то стоп элемент найден
Если t(a) = свободно или i>m, то стоп элемент не найден
i = i + 1, перейти к шагу 2
В данном алгоритме номер итерации сравнивается с пороговым числом m. Следует отметить, что алгоритмы вставки, поиска и удаления должны использовать одинаковое образование адреса очередной записи.
Лекция 3
План лекции:
1. Полустатические и динамические структуры данных.
2. Абстрактный тип данных «список».
3. Сравнение различных реализаций списков.
4. Дважды связные списки.
Не нашли, что искали? Воспользуйтесь поиском: