ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Коэффициент асимметрии Пирсона
 х - Мо
х - Мо
As = -------
s
Оценка степени существенности этого показателя дается с помощью средней квадратической ошибки, рассчитываемой по формуле
 |
6 (n – 1)
s As = ----------
Ö (n+1) (n +3)
где n – число наблюдений.
Если çAs ç / s As > 3, асимметрия существенна и распределение признака в генеральной совокупности не является симметричным. Если же çAs ç / s As < 3,, асимметрия несущественна, ее наличие объясняется влиянием случайных обстоятельств.
Для симметричных распределений рассчитывается показатель эксцесса (островершинности):
m4
Е х = ----- - 3
s4
где m4 - центральный момент четвертого порядка.
Средняя квадратическая ошибка эксцесса исчисляется по формуле
 |
24n (n – 2) (n – 3)
s Е х = -------------------------
Ö (n – 1) 2 (n + 3) (n + 5)
где n – число наблюдений.
Для приближенного определения величины эксцесса может быть использована формула Линдберга:
Ех = П – 38,29
где П – процент количества вариант, лежащих в интервале, равном половине среднего квадратического отклонения в ту и другую сторону от величины средней, в общем количестве вариант данного ряда; 38,29 – процент количества вариант, лежащих в интервале, равном половине среднего квадратического отклонения, в общем количестве вариант ряда нормального распределения..
Кривая Пауссона, выражение которой
ах\е-а
Рх = -------
хi
где Рх – вероятность наступления отдельных значений х
 а = х – средняя арифметическая ряда.
а = х – средняя арифметическая ряда.
Теоретические частоты при выравнивании эмпирических данных по кривой Пуассона определяются по формуле
¦’ = NPx
где ¦’ – теоретические частоты; N – общее число единиц ряда.
Для оценки близости эмпирических (¦) и теоретических (¦’) частот можно применить один из критериев согласия6 критерий Пирсона (c2 - «хи-квадрат»), критерий Романовского, критерий Колмогорова (l - «лямбда»).
Критерий Пирсона (c2) представляет собой сумму отношений квадратов расхождений между ¦ и ¦’ к теоретическим частотам:
(¦ - ¦’)2
c2 = S -----------
¦’
Полученное значение критерия (c2 расч) сравнивается с табличным значением (c2табл). Последнее определяется по специальной таблице в зависимости от принятой вероятности (Р) и числа степеней свободы (n - «ню»)
Уровень значимости (a) – вероятность допуска ошибки первого рода, т.е. вероятность отвергнуть правильную гипотезу о законе распределения, - обычно принимается равным 5 или 1% (a = 0,05 или a = 0,01).
Число степеней свободы (n) рассчитывается как число групп (m) в ряду распределения минус число параметров эмпирического распределения, использованных для нахождения теоретических частот.
Если выравнивание осуществляется не по частотам (¦), а по частостям

 ¦i (wi - wi’)2
¦i (wi - wi’)2
wi = -------- то c2 рассчитывается по формуле c2 = N S ------------
S ¦i wi’
где wi, wi’ – частости соответственно эмпирического и теоретического распределения, N = S ¦i- общая сумма частот (абсолютная численность единиц распределения).
При отсутствии таблиц значений c2 для оценки случайности расхождений теоретических и эмпирических частот можно воспользоваться критерием Романовского
çc2 - n ç
 --------
--------
Ö 2n
Если указанное отношение меньше 3, то расхождение считаются случайными, если больше 3, то они существенны.
Критерий Колмогорова (l) основан на определении максимального расхождения между накопленными частостями эмпирического и теоретического распределений:
 l = d ÖN
l = d ÖN
где d – максимальная величина расхождений между накопленными частостями;
N - число наблюдений, или сумма всех частот.
Если пользоваться не накопленными частостями, а частотами (абсолютными показателями), то формула примет вид
D
 l= ---------
l= ---------
Ö N
где D - максимальная разность между накопленными частотами;
N - сумма всех частот.
При проведении выборочного наблюдения используются следующие показатели:
N – объем генеральной совокупности (число входящих в нее единиц)
n – объем выборочной совокупности (число единиц, попавших в выборку)
 x – генеральная средняя (среднее значение признака в генеральной совокупности)
x – генеральная средняя (среднее значение признака в генеральной совокупности)
 x – выборочная средняя (среднее значение признака в выборочной совокупности)
x – выборочная средняя (среднее значение признака в выборочной совокупности)
p – генеральная доля (доля единиц, обладающих данным признаком в генеральной совокупности)
w – выборочная доля (доля единиц, обладающих данным признаком в выборочной совокупности)
s2 - генеральная дисперсия (дисперсия признака в генеральной совокупности)
S2 – выборочная дисперсия (дисперсия признака в выборочной совокупности)
s - среднее квадратическое отклонение признака в генеральной совокупности
S - среднее квадратическое отклонение признака в выборочной совокупности.
При бесповторном способе отбора формула для расчета стандартной ошибки будет:
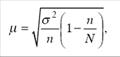
где 1 – n / N – доля единиц генеральной совокупности, не попавших в выборку.
При определении стандартных ошибок типической выборки применяются следующие формулы:
• при повторном способе отбора
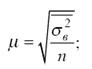
• при бесповторном способе отбора:

– средняя из групповых дисперсий в выборочной совокупности.


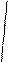


 В формуле предельной ошибки выборки учитывается средняя из групповых дисперсий (s2), т.е.
В формуле предельной ошибки выборки учитывается средняя из групповых дисперсий (s2), т.е.
s2 w( 1- w) t2 s2
D = tm = t ---- или D = t --------- n = ----------
Ö n Ö n D2
Стандартная ошибка серийной в ыборки определяется по формулам:
• при повторном способе отбора –

где d– межсерийная дисперсия выборочной совокупности; r – число отобранных серий;
• при бесповторном способе отбора –

где R – число серий в генеральной совокупности.
Величина межсерийной д исперсии
S(xi – x)2
d2 = -----------------
s
s -число обследованных серий



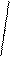 Серийная выборка в основном проводится как бесповторная, и формула ошибки выборки в этом случае имеет вид
Серийная выборка в основном проводится как бесповторная, и формула ошибки выборки в этом случае имеет вид
d2 s
Δ = t --- 1 - ----
Ö s S
где d2 - межсерийная дисперсия,
s - число отобранных серий,
S - число серий в генеральной совокупности.
При комбинированной выборке в сочетании использовались механическая и типическая выборки, то стандартную ошибку можно определить по формуле

где m1 и m2 – стандартные ошибки соответственно механической и типической выборок.
Стандартную ошибку выборки при многоступенчатом отборе при группах разных объемов определяют по формуле

где m1, m2, m3,... – стандартные ошибки на разных ступенях;
n1, n2, n3,... – численность выборок на соответствующих ступенях отбора.
Дисперсия возможных значений выборочной средней
s2r
μ2=-------
n
Исходя из этого средняя ошибка выборочной средней при повторном отборе определяется по формуле

 s2r s
s2r s
 μ2= ------- = ------
μ2= ------- = ------
Ö n Ö n
где s2 - дисперсия изучаемого показателя в генеральной совокупности (так как дисперсия изучаемого показателя в генеральной совокупности неизвестна, то фактически в формулу подставляется выборочная дисперсия, которая при большом числе наблюдений близка к генеральной);
n - объем (численность) выборки.
Средняя ошибка выборки (μ) при повторном отборе зависит от показателя вариации (s) и от объема выборки (n).
Средняя ошибка выборочной доли определяется по формуле
w (1- w)
μ = __________
n
где w - выборочная доля единиц, обладающих изучаемым признаком, w (1- w) - дисперсия доли (альтернативного признака).
При бесповторном отборе в формах под знаком радикала появляется множитель

 n
n
1 - ----
N
где N - численность генеральной совокупности.
Предельная ошибка выборки, обозначаемая через Δ, рассчитывается как t- кратная средняя ошибка, т.е.
Δ = t μ,
где μ - средняя ошибка выборки,
t - коэффициент доверия, т.е. показатель, зависящий от вероятности (Р), с которой предельная ошибка определяется.

 Общая формула предельной ошибки выборки Δ = t μ для средней приобретает вид
Общая формула предельной ошибки выборки Δ = t μ для средней приобретает вид
s2
Δ = t --- (для повторного отбора),
Ö n



 s2 n
s2 n
Δ = t --- 1 - ---- (для бесповторного отбора),
Ö n N
а для доли – соответственно
 |  | ||
w (1 – w) w (1 – w) n
Δ = t ----------- и Δ = t ----------- 1 - ----
Ö n Ö n N
Теорема Чебышева

 Р (çх – х ç < x) ® 1 при n ®¥
Р (çх – х ç < x) ® 1 при n ®¥
Теорема Бернулли является частным случаем теоремы Чебышева и касается расхождения между долями единиц, обладающих изучающим признаком, в выборочной и генеральной совокупности, т.е. разности ç w – p ç.
Согласно так называемой центральной предельной теореме Ляпунова, вероятность заданной предельной ошибки (Δ) может быть найдена как функция от t с помощью интеграла вероятностей Лапласа:
t2

 1 +t - ---
1 +t - ---
 F(t) = P (ç x- x ç £ tm) = --- ò e 2 dt
F(t) = P (ç x- x ç £ tm) = --- ò e 2 dt
Ö 2p -t
где x- x
t = ------ - нормированное отклонение выборочной средней от
μ генеральной.
Значения интеграла Лапласа (Р) для разных t рассчитаны и приведены в специальных таблицах (приложение).
Так при t=1 вероятность Р = 0,683.



 Это означает, что с вероятностью 0,683 (или 68,3%) можно гарантировать, что отклонение генеральной средней от выборочной не превысит однократной средней ошибки, т.е. что в генеральной совокупности среднее значение признака (х) будет находиться в пределах х – μ £ х £ х + μ
Это означает, что с вероятностью 0,683 (или 68,3%) можно гарантировать, что отклонение генеральной средней от выборочной не превысит однократной средней ошибки, т.е. что в генеральной совокупности среднее значение признака (х) будет находиться в пределах х – μ £ х £ х + μ
Индекс изменение товарооборота (агрегатный индекс товарооборота)

Количество - q, цена - p
Индивидуальный индекс цен определяется как отношение цены отдельного товара в отчтном периоде к цене его в базисном периоде ip = pi / p0
Индекс Фишера:

Агрегатный индекс физического объема товарооборота

Агрегатный индекс себестоимости:
 числитель представляет собой сумму фактических затрат на продукцию в отчетном периоде, а знаменатель – условную величину, которая показывает, сколько средств было бы затрачено на продукцию отчетного периода, если бы себестоимость единицы каждого вида продукции сохранялась на базисном уровне.
числитель представляет собой сумму фактических затрат на продукцию в отчетном периоде, а знаменатель – условную величину, которая показывает, сколько средств было бы затрачено на продукцию отчетного периода, если бы себестоимость единицы каждого вида продукции сохранялась на базисном уровне.
Сводный индекс цен

Расчет сводного индекса расхода материалов

Для индивидуальных объемных показателей (объем реализации, объем производительности продукции, посевная площадь) веса выбираются на уровне базисного периода. Например:

где In– сводный индекс урожайности; I – сводный индекс стоимости товарооборота; Iq – сводный индекс себестоимости.
Для индексов динамики с постоянными весами имеет силу взаимосвязь между цепными и базисными темпами роста (индексами):

Индивидуальный индекс физического объема iq = q1/q0 и стоимость продукции каждого вида в базисном периоде (q0p0). Исходной базой построения среднего из индивидуальных индексов служит сводный индекс физического объема:

(агрегатная форма индекса Ласпейреса).
Допустим, что в наличии имеется информация о динамике объема выпуска каждого вида продукции (г^) и стоимости каждого вида продукции в отчетном периоде (p1q1). Для определения общего изменения выпуска продукции предприятия в этом случае удобно воспользоваться формулой Пааше:

Числитель формулы можно получить суммированием величин q1P1, а знаменатель – делением фактической стоимости каждого вида продукции на соответствующий индивидуальный индекс физического объема продукции, т. е. делением: p1q1/iq, тогда:
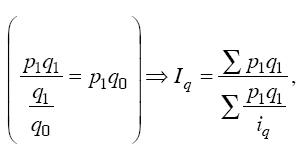
таким образом, получаем формулу среднего взвешенного гармонического индекса физического объема.
Не нашли, что искали? Воспользуйтесь поиском: