ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Проверка независимости значений уровней случайной компоненты
Проверка независимости значений уровней случайной компоненты, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности может осуществляться по ряду критериев, наиболее распространенным из которых является d -критерий Дарбина—Уотсона. Расчетное значение этого критерия определяется по формуле

| (26) |
Расчетное значение критерия Дарбина-Уотсона в интервале от 2 до 4 свидетельствует об отрицательной связи; в этом случае его надо преобразовать по формуле  и в дальнейшем использовать значение
и в дальнейшем использовать значение  .
.
Расчетное значение критерия d (или d') сравнивается с верхним DU и нижним DL критическими значениями статистики Дарбина-Уотсона.
Соответствие ряда остатков нормальному закону распределения важно с точки зрения правомерности построения доверительных интервалов прогноза.
Соответствие ряда остатков нормальному закону распределения можно провести, используя RS- критерий:
 , ,
| (27) |
где  и
и  соответственно максимальный и минимальный уровни ряда остатков;
соответственно максимальный и минимальный уровни ряда остатков;  - среднеквадратическое отклонение ряда остатков
- среднеквадратическое отклонение ряда остатков
Если расчетное значение RS попадает между табулированными границами с заданным уровнем вероятности, то гипотеза о нормальном распределении ряда остатков принимается. Табличные интервалы RS-критерия для уровня значимости 5% приведены в табл.3.
Таблица 3
| n | ||||||
| RS | 2.67 | 3.685 | 3.18 | 4.49 | 3.47 | 4.89 |
Проверка нормальности остатков, в случае достаточно большого количества наблюдений, может быть выполнена с помощью критерия согласия Пирсона [9].
Если все указанные выше четыре проверки свойств остатков дают положительный результат, то выбранная модель является адекватной исходному временному ряду, и, следовательно, ее можно использовать для построения прогнозных оценок. В противном случае – модель надо улучшать.
Характеристики точности модели
Точность модели является важнейшей характеристикой качества модели. Точность оценивается с помощью различных показателей, которые описывают величины ошибок, возникающих при использовании модели. Ошибка прогноза — величина, характеризующая расхождение между фактическим и прогнозным значением показателя.
В статистическом анализе известно большое число характеристик точности. Приведем только некоторые, наиболее часто используемые, из них.
1. Сумма квадратов (Sum Square Error - SSE) и средний квадрат ошибки (Mean Square Error - MSE)

| (28) |

| (29) |
Очевидно, что средний квадрат ошибки MSE равен дисперсии остатков 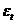 . Иногда в знаменателе формулы (29) используют величину равную n-k, где k- число оцениваемых параметров модели. Это позволяет сравнить точность моделей с учетом различного количества факторов модели.
. Иногда в знаменателе формулы (29) используют величину равную n-k, где k- число оцениваемых параметров модели. Это позволяет сравнить точность моделей с учетом различного количества факторов модели.
Очевидно, что чем меньше эти величины, тем точнее модель
2. Максимальная по абсолютной величине ошибка

| (30) |
3. Относительная максимальная ошибка

| (31) |
4. Средняя абсолютная ошибка (Mean Absolute Error- MAE).

| (32) |
(32)
5. Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error-  ) - характеризует среднюю относительную по модулю ошибку
) - характеризует среднюю относительную по модулю ошибку

| (33) |
Для прогнозов высокой точности < 10%, хорошей – 10% <  < 20%, удовлетворительной – <50%.
< 20%, удовлетворительной – <50%.
Приведенные показатели дают представление или об абсолютной величине ошибки модели или о доле ошибки в процентном отношении к значению результативного признака (для относительных ошибок). При вычислении относительных ошибок, целесообразно пропускать значения ряда, для которых  равно нулю.
равно нулю.
Другую оценку качества модели - степень смещенности прогноза дает средняя процентная ошибка (Mean Percentage Error-  ) и средняя ошибка (Mean Error -
) и средняя ошибка (Mean Error -  ). Эти значения вычисляются по формулам:
). Эти значения вычисляются по формулам:

| (34) |
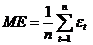
| (35) |
Если прогноз несмещенный, то отрицательные и положительные ошибки уравновешивают друг друга и обе величины и должны быть близки к нулю. Для адекватных моделей не должна превышать 5%.
Фактически величина равна величине  , вычисленная по формуле (23)
, вычисленная по формуле (23)
Построение точечных и интервальных прогнозов
Идея прогнозирования основана на предположении, что закономерность развития, действовавшая внутри временного ряда, сохранится и в прогнозируемом будущем. Другим важным предположением является предположение о том, что учет случайности позволяет оценить вероятность отклонения от закономерного развития.
Поэтому надежность и точность прогноза зависят от того, насколько близкими к действительности окажутся эти предположения, и насколько точно удалось охарактеризовать выявленную в прошлом закономерность.
На основе построенной модели рассчитываются точечные и интервальные прогнозы. Точечный прогноз на основе временных моделей получается подстановкой в модель (уравнение тренда) соответствующего значения фактора времени, т.е. t = n +1, n +2,..., n + k.
Точное совпадение фактических данных и прогностических точечных оценок, полученных путем экстраполяции кривых, характеризующих тенденцию, маловероятно. Возникновение соответствующих отклонений объясняется следующими причинами.
1. Выбранная для прогнозирования кривая не является единственно возможной для описания тенденции. Вполне возможно подобрать такую кривую, которая дает более точные результаты.
2. Прогноз осуществляется на основании ограниченного числа исходных данных. Кроме того, каждый исходный уровень обладает еще и случайной компонентой. Поэтому и кривая, по которой осуществляется прогнозирование, также будет содержать случайную компоненту.
3. Тенденция характеризует движение среднего уровня ряда динамики, поэтому отдельные наблюдения могут от него отклоняться. Если такие отклонения наблюдались в прошлом, то они будут наблюдаться и в будущем.
Точечный прогноз  в будущее на k шагов вперед, т.е. на момент t = n+k строится путем подстановки этого значения времени в уравнение (20) и отбрасывания случайной компоненты
в будущее на k шагов вперед, т.е. на момент t = n+k строится путем подстановки этого значения времени в уравнение (20) и отбрасывания случайной компоненты  ,
,
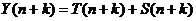
| (36) |
Интервальные прогнозы строятся на основе точечных прогнозов. Доверительным интервалом с надежностью  называется такой интервал, о котором можно утверждать, что он содержит значение прогнозируемого показателя с вероятностью [9]. Ширина интервала зависит от качества модели, т.е. степени ее близости к фактическим данным, числа наблюдений, горизонта прогнозирования и выбранного пользователем уровня надежности . Полуширина доверительного интервала для линейной модели рассчитывается по формуле:
называется такой интервал, о котором можно утверждать, что он содержит значение прогнозируемого показателя с вероятностью [9]. Ширина интервала зависит от качества модели, т.е. степени ее близости к фактическим данным, числа наблюдений, горизонта прогнозирования и выбранного пользователем уровня надежности . Полуширина доверительного интервала для линейной модели рассчитывается по формуле:

| (37) |
где  - критическое значение распределения Стьюдента с числом степеней свободы равным
- критическое значение распределения Стьюдента с числом степеней свободы равным 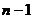 ;
;  .
.
Серединой доверительного интервала является значение точечного прогноза . С учетом этого доверительный интервал прогноза будет иметь следующие границы:
– верхняя граница прогноза равна  ;
;
– нижняя граница прогноза равна  .
.
Анализируя (36) заметим, что ширина интервала  увеличивается с увеличением k. Т.е. точность прогноза уменьшается с ростом горизонта планирования. Несмотря на то, что приведенные формулы позволяют определить прогноз на любое число шагов, попытка заглянуть слишком далеко приведет к очень большим ошибкам. Длина периода упреждения не должна превышать одной трети длины ряда наблюдений.
увеличивается с увеличением k. Т.е. точность прогноза уменьшается с ростом горизонта планирования. Несмотря на то, что приведенные формулы позволяют определить прогноз на любое число шагов, попытка заглянуть слишком далеко приведет к очень большим ошибкам. Длина периода упреждения не должна превышать одной трети длины ряда наблюдений.
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадает в интервал, образованный верхней и нижней границей. После получения прогнозных оценок необходимо убедиться в их разумности и непротиворечивости оценкам, полученным иным способом.
Пример 2.
Месячный объем продаж некоторого товара приведен за 4 года на рис.9.
Требуется провести анализ структуры временного ряда, построить модель и провести прогноз продаж этого товара на первые три квартала 2003 года с надежностью равной 95%.

Рис.9. Объемы продаж.
1. Провести предварительный анализ данных:
· выявить и устранить аномальные значения уровней ряда;
· выровнять (сгладить) ряд с помощью механического выравнивания путем укрупнения интервала. Для этого перейти от ежемесячных значений к среднемесячным за квартал.
2. Для первичного анализа временного ряда построить ряды:
· первых разностей;
· вторых разностей;
· цепных коэффициентов роста.
3. Построить автокорреляционную функцию и ее график (коррелограмму). Проанализировать полученный результат.
4. Определить наличие тренда в исходном временном ряду с помощью:
· критерия серий (основан на медиане выборки);
· метода проверки разностей средних.
5. Построить аддитивную модель временного ряда, сформированного из трендовой (Т), сезонной 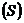 и случайной (Е) компонент(
и случайной (Е) компонент( ).
).
6. Проверить адекватность модели.
7. Оценить точность модели.
8. Провести прогноз.
Решение.
Для предварительного исследования построим график объема продаж в зависимости от времени (рис.10). На нем отчетливо виден подозрительный на аномальность уровень ряда при  .
.
Более детальное исследование на наличие аномальных значений уровней ряда проведем методом Ирвина, используя соотношения (9)-(10). Расчеты приведены на рис.11-12, график соответствующий исправленным уровням ряда приведен на рис.13.

Рис.10. Динамика временного ряда - объем продаж. Отчетливо виден подозрительный на аномальность уровень ряда при .

Рис. 11. Исследование на наличие аномальных значений уровней ряда методом Ирвина (режим отображения данных)

Рис. 12. Исследование на наличие аномальных значений уровней ряда методом Ирвина (режим отображения формул)

Рис. 13. Динамика временного ряда - объем продаж (подозрительных на аномальность уровней ряда нет).
Для выявления тенденции укрупним рассматриваемые временные промежутки, равные месяцу, до квартала путем вычисления средних за квартал уровней. Все вычисления приведены на рис.11-12 в диапазоне ячеек H5:H51. Получим следующий ряд, приведенный в диапазоне ячеек А57:В73 (рис. 14). На том же рис. 14 приведен расчет показателей этого временного ряда: первых и вторых разностей, коэффициента роста. На рис.15-16 приведены соответствующие графики.

Рис.14. Расчет динамики временного ряда – объем продаж в зависимости от номера квартала. Вычисление показателей ряда первых и вторых разностей, коэффициента роста

Рис. 15. Динамика временного ряда – объем продаж в зависимости от номера квартала.

Рис. 16. Показатели временного ряда первые и вторые разности, коэффициента роста объема продаж в зависимости от номера квартала.
Не нашли, что искали? Воспользуйтесь поиском: