ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Застосування вибіркового методу в правовій статистиці. Способи відбору статистичної інформації та оцінка результатів вибіркового дослідження.
Вибіркові дослідження широко використовуються в різних галузях статистики. В правовій статистиці вибіркові спостереження дають можливість дослідити різні правові явища. Тобто, якщо необхідно провести поглиблене вивчення окремих видів злочинів, правопорушень і особливостей осіб, що їх вчинили, то доцільно застосовувати вибіркове спостереження. Разом з тим, є необхідним і важливим його застосування і для визначення характерних тенденцій, що виявляються при аналізі правових явищ і процесів що відбуваються в суспільстві.
Нагадаємо, що статистичне спостереження це цілеспрямований, науково організований і методично контрольований облік ознак і властивостей масових явищ, подій, фактів. Метою якого (спостереження) є необхідність зібрання високоякісного статистичного матеріалу на базі обґрунтованого визначення ознак досліджуваного явища, щоб внаслідок проведеного аналізу можна було одержати реальну характеристику розглядуваних явищ і процесів. Також, пам’ятаємо що статистичне спостереження за повнотою охоплення одиниць сукупності поділяється на суцільне і несуцільне.
Отже, вибіркове спостереження, можна визначити як найбільш поширений вид несуцільного спостереження, який застосовують при вивченні різноманітних закономірностей суспільного життя.
Вибіркове спостереження, проведене при дотриманні вироблених наукою правил, дозволяє шляхом вивчення частини фактів виявити статистичні закономірності, що характерні для всієї досліджуваної сукупності. Таким чином, під вибірковим спостереженням розуміється несуцільне спостереження, при якому статистичному обстеженню (спостереженню) піддаються не всі, а окремі одиниці, відібрані з дотриманням певних умов.
Теоретичні основи проведення вибіркових спостережень були закладені роботами видатних математиків: Я. Бернулли (1654-1705), П.С. Лапласа (1749-1827), К.Ф. Гаусса (1777-1855), С.Д. Пуассона (1781-1840). Також чималий внесок в розвиток теорії і практики застосування вибіркового методу був внесений і працями видатних російських математиків: П.Л. Чебишева (1821 – 1894), О.М. Ляпунова (1857– 1918), А.А. Маркова (1856-1922).
Так, вже в другій половині XIX в. вибіркові обстеження проводилися земськими статистиками, які відрізнялися певною новизною в рішенні питань організації відбору одиниць. Користуючись даними земської статистики, О.О. Чупров провів, наприклад, вивчення писемності населення 5200 селищ Московської губернії. За підрахунками, на основі суцільного спостереження, відсоток писемності склав 47,6%. Тоді дослідник з вказаних 5200 селищ відібрав 500 селищ і визначив в них відсоток писемності, що виявився рівним 47,5%. Таким чином, дані суцільного і вибіркового спостережень майже співпали, а різниця виражалася всього лише в 0,1%.
Теорія і практика проведення вибіркового спостереження показують, що при правильній його організації є можливість отримати достовірні дані, які цілком придатні для використання. Так, отримані при вибірковому спостереженні відносні і середні показники, досить точно відтворюють відповідні показники всієї сукупності. Отже, вибірковий масив (сукупність одиниць) являє собою зменшену модель усієї сукупності. Саме одиниці сукупності становлять основу обліку і підлягають безпосередньому обстеженню, адже сума таких одиниць сукупності обов'язково дає статистичну сукупність явищ. Нагадаємо, що в правовій статистиці одиниця сукупності (спостереження) це неподільний складовий елемент сукупності, що вивчається, ознаки якого реєструються в процесі статистичного спостереження (злочин, злочинець, покарання, наслідки злочину (шкода, кількість загиблих тощо)).
Особливе місце вибіркове спостереження займає в дослідженнях злочинності і пов’язаних з нею проблем. До вибіркового спостереження вдаються з різних причин. По-перше, як наголошувалося, використання вибіркового обстеження дозволяє значно заощадити сили і засоби, що в сучасних умовах має важливе значення. По-друге, разом з економією ресурсів однієї з причин перетворення вибіркового спостереження в найважливіше джерело статистичної інформації в процесі вивчення соціально-правових явищ виявляється можливість значно прискорити отримання необхідних даних. Адже при обстеженні, скажімо, 10–15% одиниць сукупності буде витрачено набагато менше засобів і часу, а результати можуть бути отримані швидше і будуть більш актуальними.  По-третє, і це, мабуть, найголовніше, перевага вибірки, її значення зростає через можливість розширення програми спостереження. Оскільки дослідженню піддається порівняно невелика частина всієї сукупності, можна більш широко і детально вивчити окремі одиниці і їх групи по тим ознакам що цікавлять дослідників.
По-третє, і це, мабуть, найголовніше, перевага вибірки, її значення зростає через можливість розширення програми спостереження. Оскільки дослідженню піддається порівняно невелика частина всієї сукупності, можна більш широко і детально вивчити окремі одиниці і їх групи по тим ознакам що цікавлять дослідників.
І останній чинник, перетворення вибіркового спостереження в найважливіше джерело соціально-правової інформації про правопорушення і державні заходи соціального контролю над ними – можливість його використання в цілях уточнення і для розробки даних суцільного обстеження. Вибіркова розробка даних суцільного спостереження пов’язана з необхідністю представлення оперативних попередніх підсумків обстеження. Крім цього, при узагальненні даних суцільного обліку (наприклад, карток єдиного обліку злочинів) неможливо вести суцільну розробку по всіх поєднаннях даних ознак. Також це досить складно, довго і невигідно (дорого). В цих умовах вибірковий метод дозволив би отримати необхідні відомості прийнятної точності, коли чинники часу і вартості роблять суцільну розробку недоцільною. Водночас застосування вибіркового обстеження (несуцільного) замість суцільного, що використовується державною статистикою, дає можливість глибше організувати спостереження, забезпечує швидкість його проведення, приводить до економії засобів і праці на отримання і обробку інформації.
Джерелами первинної інформації при організації і проведенні вибіркового спостереження з науково-практичних питань контролю над злочинністю можуть бути: статистичні звіти, інформаційні бюлетені, огляди, аналітичні довідки і доповіді, документи єдиного обліку (статистичні картки) злочинів, матеріали кримінальних і цивільних справ, листи, повідомлення, заяви громадян, матеріали преси, радіо, телебачення а також інші документи, відомості, що містять інформацію, про злочин і особу злочинця; потерпілого; членів сім’ї злочинця, інших родичів, друзів за місцем проживання і місцем роботи тощо.
Сутність вибіркового спостереження полягає в тому, що з усієї сукупності за певними правилами відбирається заздалегідь обумовлена частина сукупності (кожна четверта, або п'ята, або десята одиниця), яка ретельно вивчається. Результати цього часткового спостереження поширюються на всю генеральну сукупність з урахуванням похибки репрезентативності.
Репрезентативність це властивість вибіркового масиву відтворювати характеристики всієї сукупності. Таким чином, при відборі одиниць у вибіркову сукупність завжди повинна бути забезпечена рівна можливість потрапити у вибірку кожної з одиниць сукупності. Водночас, при проведенні вибіркового спостереження завжди присутня похибка репрезентативності, в першу чергу тому, що частина завжди відрізняється від цілого.
Відбір репрезентативної вибірки здійснюється за допомогою або імовірних методів, або методів так званих квот. Відомо, що чим більша вибірка (частина тієї, що піддається вивченню сукупності), тим точніше результати.
Для того щоб визначити мінімально необхідне число спостережуваних одиниць, необхідно визначити частку у загальній сукупності, яку займає та її частина, що цікавить дослідника, і в яких межах допустимі помилки в передбачуваних результатах. Виходячи з цих умов, і використовуючи приведену нижче таблицю (табл. 1), можна встановити мінімальне число спостережень, необхідних для того, щоб помилка не перевищила завданої межі (таблиця розрахована на масив у 100000 одиниць).
Припустимо, потрібно дізнатися, скільки необхідно обстежити засуджених за хуліганство для з’ясування серед них частки осіб, які вчинили злочини у стані сп’яніння. Межа похибки при нашому обстеженні повинна бути не більше 4%. На основі попереднього ознайомлення з різними матеріалами (статистична звітність, показники минулих обстежень, судова практика тощо), на нашу думку, очікувана частка складе приблизно 80%. Тоді з останнього рядка таблиці ми побачимо, що величині показника 80% з похибкою у 4% відповідає числу 400. Отже, в даному випадку необхідно досліджувати не менше 400 засуджених осіб.
Таблиця 1. Розрахунок числа спостережень, що необхідні для визначення величини похибки не вище завданої межі
| При величині показників (%) | межі похибки в % | |||||
В цьому разі, також необхідно враховувати й те, що чим однорідніше сукупність, тим менше може бути вибірка. Важливо забезпечити і рівномірний розподіл вибірки по усій сукупності, щоб виключити невідповідність у висновках між різними частинами масиву. Припустимо, що вся сукупність дорівнює 1000, а нам достатньо дослідити 100 одиниць. У даному випадку доцільно брати не підряд 100 одиниць, кожну десяту одиницю (10, 20, 30 тощо), тоді розподіл буде рівномірним по усій сукупності та виключає недоцільність вибірки.
З метою з’ясування, в яких саме межах може коливатися точність показника, одержаного на основі вибірки, використовується таблиця, що дозволяє встановити межі похибки при даному числі спостережень (див. табл. 2).
Таблиця 2
| При величині показника | Число спостережень | |||||||||
| 6,0 | 4,3 | 3,5 | 3,0 | 2,7 | 2,5 | 2,3 | 2,1 | 2,0 | ||
| 7,2 | 5,1 | 4,1 | 3,6 | 3,2 | 2,9 | 2,7 | 2,5 | 2,4 | ||
| 8,0 | 5,7 | 4,6 | 4,0 | 3,6 | 3,3 | 3,0 | 2,0 | 2,7 | ||
| 9,2 | 6,5 | 5,3 | 4,6 | 4,1 | 3,7 | 3,5 | 3,2 | 3,1 | ||
| 9,6 | 6,8 | 5,5 | 4,8 | 4,3 | 3,9 | 3,6 | 3,4 | 3,2 | ||
| 9,9 ' | 7,0 | 5,6 | 4,9 | 4,4 | 4,9 | 3,7 | 3,5 | 3,3 | ||
| 10,0 | 7,1 | 5,7 | 5,0 | 4,5 | 4,1 | 3,8 | 3,5 | 3,3 | ||
| 7,1 | 5,7 | 5,0 | 4,5 | 4,1 | 3,8 | 3,5 | 3,3 | |||
| 9,6 | 6,8 | 5,5 | 4,8 | 4,3 | 3,9 | 3,6 | 3,4 | 3,2 | ||
| 9,2 | 6,5 | 5,3 | 4,6 | 4,1 | 3,7 | 3,5 | 3,2 | 3,1 | ||
| 8,7 | 6,2 | 5,0 | 4,3 | 3,9 | 3,5 | 3,3 | 3,1 | 2,9 | ||
| 8,0 | 5,7 | 4,6 | 4,0 | 3,6 | 3,3 | 3,0 | 2,8 | 2,7 |
Покажемо на прикладі, як використовувати дану таблицю. Припустимо, що на основі обстеження 100 засуджених за хуліганство встановлено, що 80% з них вчинили злочин у стані алкогольного сп'яніння. Наскільки точний цей показник? Відповідь на дане питання дає приведена таблиця, в якій на перетині горизонтальної останньої строчки (з числом 80) з вертикальним першим рядком (з числом 100) ми знаходимо число 8,0. Воно означає наступне: при даному числі спостережень (100 чол.) частка засуджених, тих, що вчинили хуліганські дії у стані сп'яніння, може коливатися у межах від 72 до 88%. Всі показники обчислені з вірогідністю -$,954, тобто з урахуванням так званої подвійної похибки. Як видно з таблиці, шляхом збільшення чисельності вибірки можна зменшити похибку до будь-якої бажаної межі (при збільшенні, наприклад, числа спостережень з 100 засуджених до 400 похибка вибірки буде зменшена у два рази - з 8 до 4%.
Вирішення завдань отримання додаткової інформації за допомогою вибіркових досліджень досягається двома шляхами.
Перший - з використанням методу вторинного групування вже одержаних даних, відображених у статистичних картках за результатами суцільного спостереження. Подібне групування доцільне за такими показниками, як рівень освіти, вік засуджених, місце і час вчинення злочинів. Особливо корисно об’єднувати комбіновані дані, що дозволяють їх співставити, зокрема таких як, рід занять засуджених і вчинення злочинів; виду злочину, статі та віку осіб, що їх вчинили.
Вибіркове дослідження статистичних карток не може забезпечуватися всією додатковою інформацією, необхідною для кримінологічного аналізу, оскільки число і зміст їх показників обмежені. Тому вибіркові дослідження проводяться головним чином за самостійною програмою на основі вивчення певної частини сукупності. Це другий, дієвий шлях отримання додаткової інформації.
По суті, всі статистичні методи, що використовуються в кримінології (анкетування, інтерв’ювання, вивчення кримінальних справ та інших документів), є саме вибірковими дослідженнями, оскільки у цих випадках досліджується не вся сукупність, а лише її певна частина.
Технологія вибіркового спостереження має включати наступні основні етапи:
1) постановка мети спостереження та складання програми спостереження (анкет, бланків опитування і т. д.) і розробку її матеріалів;
2) рішення організаційних питань спостереження в коло яких входить визначення обсягу вибірки і способу відбору;
3) проведення відбору;
4) реєстрація відповідних ознак (за програмою) у відібраних одиницях;
5) узагальнення даних спостереження і розрахунок вибіркових характеристик;
6) розрахунок помилок вибірки;
7) перерахунок вибіркових характеристик на всю сукупність.
З’ясуємо основні поняття що використовуються при проведенні вибіркового спостереження.
Найважливіша ознака вибіркового спостереження як виду несуцільного спостереження – випадковий характер вибірки, а головна його особливість полягає в тому, що при відборі одиниць сукупності для обстеження забезпечується рівна можливість попадання у відібрану частину будь-якої з одиниць. Переваги вибіркового спостереження перед суцільним спостереженням реалізуються лише при дотриманні наукових принципів його організації і проведення, тобто відповідного, насамперед неупередженого, випадкового відбору одиниць для спостереження.
Отже, вибіркова сукупність повинна повністю відтворювати склад генеральної сукупності. Саме тому при розгляді питань що стосуються вибіркової сукупності необхідно зупинитися на основних термінах вибіркового спостереження.
Генеральна сукупність – це вся сукупність одиниць, з якої проводиться відбір частини одиниць для вибіркового спостереження. Таким чином, відібрана в певний спосіб частина генеральної сукупності для вибіркового спостереження називається вибірковою сукупністю. Узагальнюючі показники генеральної сукупності називаються генеральними, а відповідні показники вибіркової сукупності – вибірковими. Водночас принцип випадковості відбору забезпечує всім одиницям генеральної сукупності рівні можливості потрапити у вибіркову сукупність.
Таким чином генеральна сукупність (N) це сукупність одиниць, з якої проводиться відбір деякої їх частини для статистичного дослідження. А вибіркова сукупність (n) це сукупність одиниць, яка відібрана з генеральної сукупності і піддана спостереженню (реєстрації ознак що цікавлять дослідника).
Генеральна сукупність (а слідом за нею і вибіркова сукупність) може бути кількісною або якісною, що залежить від того, чи є ознаки, властивості одиниць спостереження кількісними (вік) або якісними (стать). Ця відмінність припускає, що статистичний опис сукупності приймає або форму середніх арифметичних, або форму питомої ваги (частки). Тим самим, абсолютно природно, що між цими показниками генеральної і вибіркової сукупностей є якась відмінність, інакше кажучи, існує помилка у визначенні показників вибіркової сукупності саме тому, що остання є частиною генеральної сукупності. Отже, ці так звані похибки репрезентативності є розбіжністю між показниками вибіркової і генеральної сукупності. Відповідно, наголошуючи що частина завжди відрізняється від цілого і має певні відмінності, а самі ті що є між показниками генеральної і вибіркової сукупностей, в статистиці називають похибками репрезентативності. Відповідно вони пояснюються тим, що вибіркова сукупність не зовсім точно відображає склад генеральної сукупності. Таким чином, середня в генеральній сукупності відрізняється від середньої у вибірковій сукупності на величину похибки репрезентативності. Похибки репрезентативності можуть бути систематичними і випадковими. Якщо перші виникають у зв'язку з особливостями прийнятої системи відбору і обробки даних спостережень або у зв'язку з порушенням встановлених правил відбору, то другі в наслідок недостатньо рівномірного уявлення у вибірці окремих видів одиниць генеральної сукупності.
Наприклад, генеральна сукупність правопорушників складається з 500 осіб. З них 30% складають злочинці, які виховувались в неповних сім’ях. При вибірковому спостереженні було вивчено 50 правопорушників, серед яких питома вага таких осіб склала 25%. Помилка вибірки дорівнює 30-25=5%. Середня арифметична величина віку злочинців в генеральній сукупності склала 28,3 роки, а у вибірковій сукупності – 26,5 років, що дає похибку яка дорівнює 28,3-26,5=1,8 років.
В загальному вигляді формула для розрахунку похибки репрезентативності така:
 , (1)
, (1)
де  2 – дисперсія; – середнє квадратичне відхилення (СКВ);
2 – дисперсія; – середнє квадратичне відхилення (СКВ);
n – число одиниць вибірки.
Аналіз формули (1) показує, що похибка репрезентативності прямо пропорційна та зворотно пропорційна числу одиниць вибірки n, тобто w буде тим менше, чим менше дисперсія (СКВ) і чим більше n. Якщо статистичне дослідження вже проведено, тобто обсяг вибірки n вже відомий, завданням буде розрахунок дисперсії. Для якісних ознак дисперсія (СКВ) розраховується за формулою:
 (2)
(2)

де р – частка якісної ознаки; 1 – р – частка інших ознак (протилежних ознак).
Для вищенаведеного прикладу р = 30% = 0,3; 2 = 0,3 (1-0,3) = 0,21; 
Для кількісних ознак
 , (3)
, (3)
де: х1,х2, …, хі, …,хn – показник варіюючої ознаки, 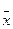 - середнє арифметичне значення ознаки, а f1, f2, f3, …fi, …, fn - частоти варіюючої ознаки.
- середнє арифметичне значення ознаки, а f1, f2, f3, …fi, …, fn - частоти варіюючої ознаки.
З врахуванням вищенаведених формул (2) та (3), формули для розрахунку похибок репрезентативності якісних і кількісних ознак матимуть наступний вигляд:
 , (4)
, (4)
 (5)
(5)
Розглянемо приклад розрахунку похибки репрезентативності (w) для статистичної вибірки 100 засуджених (n=100), що відбувають покарання строком від одного до шести років. Розподіл засуджених за строками ув’язнення приведено в таблиці.
Таблиця. Розподілу засуджених за строками ув’язнення.
| Строк, років | ||||||
| Засуджених, осіб |
Середня арифметична строку ув’язнення дорівнює:

Дисперсія: 
Похибка репрезентативності:

Якщо обсяг вибірки збільшити в чотири рази, тобто до 400 засуджених, то похибка репрезентативності може бути зменшена вдвічі, що складатиме року.
Формули (4) та (5) доцільні для так званої повторної вибірки, коли кожна відібрана одиниця знову повертається в загальний масив сукупності.
При безповторному відборі, коли кожна відібрана одиниця виключається з числа одиниць генеральної сукупності (відібрана одиниця може потрапити в вибірку лише один раз), похибка вибірки для якісних та кількісних розраховується по таким формулам:
 , (6)
, (6)
 (7)
(7)
Наявність множника у формулах (6) і (7) дозволяє більш точно вирахувати помилку безповторної вибірки, причому в бік її мінімізації. Тому якщо досліднику невідома чисельність генеральної сукупності, а ним здійснена безповторна вибірка, то похибка репрезентативності може бути вирахувана за формулою повторної вибірки. Незначну неточність, що пов’язана зі збільшенням розрахункової помилки, можна не враховувати, оскільки соціально-правові дослідження не потребують високої точності.
Гранична похибка репрезентативності  знаходиться як добуток однократної помилки вибірки на відповідний коефіцієнт довіри t:
знаходиться як добуток однократної помилки вибірки на відповідний коефіцієнт довіри t:
= wt (8)
Коефіцієнт довіри (коефіцієнт кратності похибки) t дозволяє збільшити репрезентативність вибірки за рахунок збільшення вибіркової сукупності. Для кримінологічних, соціально-правових досліджень, а також для практичних оперативних цілей дозволяється точність з коефіцієнтом довіри t=1. При рішенні важливих наукових та практичних питань бажано щоб t=2. Значення t>2 при визначені крайньої похибки репрезентативності в юридичній статистиці майже не використовується.
Визначення обсягу вибіркової сукупності має суттєве значення для дослідників. Кількість одиниць сукупності, що відбираються для вибіркового спостереження, має бути досить велика. Водночас, кількість одиниць, відібраних для вибіркового спостереження завжди залежить від того наскільки однорідна чи різнорідна сукупність. Якщо сукупність однорідна, тим менше одиниць відбирається, і навпаки, чим різнорідніша сукупність тим більше одиниць необхідно відібрати. Необхідно врахувати й те, що чим менше одиниць відбирається для спостереження тим більше може бути похибка репрезентативності. Так і в тому разі, якщо для вибіркового спостереження відбирається дуже значна кількість одиниць, то відбувається зайва витрата часу на його проведення, що призводить до нівелювання основного змісту та цілей вибіркового спостереження. Беззаперечно, що основний зміст вибіркового спостереження полягає у можливості значно швидше і з найменшими витратами часу отримати необхідні результати.
Водночас, розрахунок обсягу вибіркової сукупності здійснюється на основі так званих завданих та наявних показників. Завданими показниками є гранична похибка репрезентативності (w або ), коефіцієнт довіри t, а наявними дисперсія  (СКВ ) досліджуваних ознак і в деяких випадках чисельність генеральної сукупності.
(СКВ ) досліджуваних ознак і в деяких випадках чисельність генеральної сукупності.
Формули розрахунку вибіркової сукупності отримуються з формул розрахунку похибок репрезентативності. 1, 4-8.
Для якісних та кількісних ознак розрахунок обсягів вибіркової сукупності здійснюється за наступними формулами:
 (9)
(9)
 (10)
(10)
Формули розрахунку обсягу вибіркової сукупності при без повторній вибірці відповідно для якісних та кількісних ознак має наступний вигляд:
 (11)
(11)
 (12)
(12)
Враховуючи те, що основним завданням при проведенні вибіркового дослідження у правовій статистиці є визначення репрезентативного обсягу вибіркового спостереження, тобто скільки необхідно проаналізувати одиниць з генеральної сукупності, щоб одержана випадкова похибка середнього значення досліджуваної ознаки не перевищувала визначеної величини похибки репрезентативності з достатньою імовірністю. Отже, визначення величини похибки середнього значення ознаки для встановлення обсягу вибірки є досить важливим моментом.
Визначення можливої і фактично допущеної помилки вибірки має значну роль в рішенні питання про можливість застосування вибіркового методу. Величина помилки характеризує ступінь надійності результатів вибірки, а тому знання цієї величини необхідне при оцінці параметрів генеральної сукупності. Оцінка можливої величини і складу помилок репрезентативності лягають в основу планування проектованого вибіркового спостереження.
При проведенні вибіркового спостереження необхідно враховувати наступні обставини, що обумовлюють величину випадкової помилки репрезентативності, а саме, спосіб формування вибіркової сукупності; ступінь коливання ознаки, що вивчається, в генеральній сукупності та об’єм (обсяг) вибірки. Зрозуміло, що збільшення розміру вибірки за інших рівних умов дає велику впевненість (чим більше одиниць потрапляє у вибірку, тим меншою буде можлива помилка), але оскільки потрібна можливо менша вибірка, в статистці виробляються способи, які або забезпечують підвищення точності оцінок при фіксованому розмірі вибірки, або дозволяють зменшити розмір вибірки, що вимагається для отримання заданої точності.
Враховуючи вищезазначене, підкреслимо, що похибка репрезентативності залежить від багатьох чинників: по-перше, імовірності, з якою ми бажаємо отримати результат; по-друге, кількості одиниць вибіркової сукупності; по-третє, однорідності досліджуваної сукупності, і по-четверте, від способу відбору одиниць у вибіркову сукупність.
Отже, розглянемо основні способи відбору статистичної інформації. Об’єктивну гарантію репрезентативності отриманої вибіркової сукупності дає застосування відповідних науково обґрунтованих способів відбору підлягаючих дослідженню одиниць. Тим самим в процесі формування вибіркової сукупності повинен бути забезпечений об’єктивний підхід до відбору одиниць. Порушення цього принципу, коли спостереженню піддаються одиниці, відібрані на підставі суб’єктивної думки дослідника, призводить до того, що результати такого спостереження відносяться не до всієї генеральної сукупності, а тільки до тієї її частини, яка була піддана обстеженню.
Майже всі кримінологічні дослідження базуються на вибіркових спостереженнях, тобто з використанням вибіркового методу. Щоб вивчити якусь кримінологічну проблему, дослідник повинен відібрати таку частину об’єктів спостереження, яка найточніше представлятиме явище, що досліджується. Отже, в правовій статистиці, генеральну сукупність утворює вся множина об’єктів, які є предметом вивчення в межах, окреслених програмою кримінологічного дослідження і територіально-часовими параметрами. Наприклад, якщо об’єктом вивчення є всі зареєстровані в 2006 р. випадки хуліганства, генеральна сукупність буде нараховувати всі кримінальні справи та інші матеріали про хуліганство. Якщо дослідження охоплює всі без винятку об’єкти, що утворюють його генеральну сукупність, то воно буде суцільним обстеженням. Тоді як вибіркову сукупність становить частина генеральної сукупності, що виступає об’єктом спостереження. Адже вибіркова сукупність най частіше застосовується в конкретних кримінологічних дослідженнях. І як вище зазначалось, вона повинна бути репрезентативною. Нагадуємо, що репрезентативність вибірки означає, що з деякою наперед заданою погрішністю можна ототожнити встановлений у вибірковій сукупності розподіл ознак явища, що вивчається, з їх дійсним розподілом у генеральній сукупності.
Розглянемо основні етапи формування вибіркової сукупності:
1) Перед організацією процедури безпосереднього відбору об’єктів у вибірку, потрібно обґрунтувати її структуру з точки зору завдань дослідження. Структура вибіркової сукупності за звичай складається на підставі висунутих гіпотез. Наприклад, при дослідженні проблеми хуліганства кримінолог може висунути гіпотезу про різне поширення цього злочину серед верств населення залежно від рівня їх освіти. Тоді, зазначаючи, що в генеральній сукупності (серед населення регіону що вивчається) 15% осіб з вищою освітою, 40% - із середньою і 45% - з неповною середньою освітою, він повинен витримати ці пропорції і у вибірці. Якщо гіпотеза передбачає також, що схильність до хуліганства залежить від віку, то у вибірці мають бути пропорційно представлені ті вікові групи генеральної сукупності, які цікавлять дослідника.
2) Структура вибіркової сукупності задається з урахуванням доступної досліднику кримінологічної інформації.
3) Після того як визначена, структура вибіркової сукупності, наприклад розподіл осіб за віком, виникає питання, як практично відібрати об’єкти з генеральної сукупності, щоб отримати потрібну структуру. В цьому разі ефективними будуть методи математичної статистики. На цьому етапі обирається обсяг вибірки та способи її проведення.
Обсяг вибірки, формули розрахунку якого ми наводили в попередньому підрозділі, дослідниками сприймається як загальне число одиниць спостереження, включених у вибіркову сукупність. Довівши що обсяг вибірки також залежить і від числа ознак, які вона охоплює. Вибірка, яка має достатній обсяг для однієї ознаки, може бути абсолютно недостатньою для іншої. Тому коли планується вивчення розподілу багатьох ознак, то вибірка мусить повно репрезентувати кожну з них.
Для того, щоб результати, отримані при вивченні вибіркової сукупності, можна було без значної погрішності розповсюдити на всю сукупність, при організації вибіркового спостереження необхідно дотримувати наступні, вироблені теорією статистки вимоги. А саме: - число одиниць, узятих для вибіркового обстеження, повинне бути достатньо великим; - вибір одиниць спостереження повинен бути випадковим, тобто кожна одиниця сукупності, що вивчається, повинна мати рівну можливість потрапити у вибірку; - вибір повинен здійснюватися з усіх частин сукупності, що вивчається; - вибір не повинен залежати від кількості і значення ознак, якими володіють одиниці сукупності.
В практиці проведення статистичних досліджень існують різні способи відбору одиниць у вибіркову сукупність. За способом організації розрізняють просту або випадкову, типову, механічну, серійну вибірку. По ступеню обхвату одиниць досліджуваної сукупності розрізняють великі і малі вибірки. Залежно від способу відбору одиниць розрізняють повторну і безповторну вибірку:
1) відбір по схемі поверненої кулі (картки), який називається повторною вибіркою. При повторному відборі вірогідність попадання кожної окремої одиниці у вибірку залишається постійною, оскільки після відбору якоїсь одиниці (кулі, картки) вона знову повертається в сукупність (в урну) і знову може бути вибрана;
2) відбір по схемі неповерненої кулі (картки), називається безповторною вибіркою. В цьому випадку кожна відібрана одиниця не повертається назад, і вірогідність попадання окремих одиниць у вибірку весь час змінюється (для одиниць, що залишилися, вона зростає).
Найчастіше у правовій статистиці використовують такі способи відбору одиниць у вибіркову сукупність: простий випадковий, механічний, типовий, серійний, або гніздовий.
Розглянемо їх більш детально.
Простий випадковий відбір – це класичний спосіб формування вибіркової сукупності, при якому відбір одиниць у вибіркову сукупність проводиться випадково шляхом жеребкування або з використанням таблиці випадкових чисел. При такому способі відбору для усіх одиниць сукупності створюється однакова можливість потрапити у вибіркову сукупність.
Випадкова вибірка звичайно проводиться за допомогою жеребкування або за допомогою таблиць випадкових чисел.
Таблиця випадкових чисел.
Користуватися таблицею випадкових чисел слід наступним чином. Наприклад, у вибіркову сукупність має бути включено 75 одиниць із перелічених 780 одиниць генеральної сукупності. Використовуючи таблицю випадкових чисел, можна побачити, що її перший рядок має такі числа: 5489; 5583; 3156; 0835; 1988; 3912; 0938; 7460; 0869 та 4420. До нашої вибіркової сукупності можуть потрапити одиниці, які мають номер менше 780. Використовуючи лише останні три кожного числа, ми зможемо відібрати необхідну кількість одиниць у вибіркову сукупність. Із наведених чисел це будуть: 489; 583; 156; 460; 420. Можна використовувати і перші три цифри кожного числа. Тоді у вибіркову сукупність потрапили б: 548; 558; 315; 83; 198; 391; 93; 746; 86 та 442.
При простому випадковому відборі для кожної одиниці сукупності створюються однакові умови, щоб потрапити у вибіркову сукупність у кожному окремому акті відбору. Завдяки цьому узагальнюючі ознаки вибіркової сукупності досить точно відображають узагальнюючі показники генеральної сукупності.
Застосування простого випадкового відбору є результативним в тому разі коли сукупність однорідна. В тому разі якщо генеральна сукупність складається з одиниць, які істотно відрізняються одна від одної, то необхідно формувати вибіркову сукупність механічним або типовим відбором.
Механічний відбір – це вибірка, при якій генеральна сукупність заздалегідь поділяється на певне число рівних за кількістю одиниць груп, після чого із кожної групи відбирається для вибіркової сукупності тільки одна одиниця. Основою такої вибірки є впорядкована чисельність елементів сукупності з якої відбір одиниць здійснюється через рівні інтервали. Межу інтервалів обчислюють діленням обсягу всієї сукупності на передбачений обсяг вибіркової сукупності. Відбір одиниць проводять відповідно до встановленої пропорції через який-небудь інтервал. Наприклад, при пропорції 1:50 (2%-ва вибірка) відбирається кожна 50-а одиниця, при пропорції 1:20 (5%-ва вибірка) – кожна 20-а одиниця сукупності і т.д.
Механічна вибірка застосовується у випадках, коли генеральна сукупність яким-небудь чином впорядкована, тобто є певна послідовність в розташуванні одиниць сукупності (списки виборців – за абеткою, табельні номери працівників – по підрозділах, відділах, номери установ кримінально-виконавської системи – по регіонах, номери кримінальних справ – залежно від перебування під слідством і т.п.). Отже, при проведені механічного відбору до вибіркової сукупності потрапляють різні частини генеральної сукупності тому механічний відбір вважається більш репрезентативним.
До поширених способів відбору одиниць сукупності, як у державній так і правовій статистиці, відноситься типовий відбір. Типовою називається така вибірка, при якій генеральна сукупність заздалегідь поділяється на якісно однорідні, типові групи. Далі з кожної групи відбирається певна кількість одиниць у порядку простого випадкового або механічного відбору з метою формування вибіркової сукупності з урахуванням кількості одиниць, які потрапили в кожну окрему групу.
Отже, т иповий відбір можна визначити як спосіб формування вибіркової сукупності залежно від складу генеральної сукупності за типовими ознаками. При типовому відборі забезпечується пропорційне потрапляння у вибірку одиниць сукупності з різних окремих груп.
Отже, при типовій вибірці генеральна сукупність заздалегідь розчленовується на типи, кожний з яких у вибірці представлений квотою, пропорційної чисельності типу в генеральній сукупності. При обстеженнях населення такими типовими групами можуть бути райони, соціальні, вікові або освітні групи, при обстеженні установ кримінально-виконавської системи – вид виправних установ залежно від режиму тримання засуджених, віку ув’язнених і т.п. Безпосередній відбір одиниць з типових груп проводиться у вигляді випадкового відбору, механічного відбору або яким-небудь іншим способом. При цьому відбір може бути або пропорційним чисельності одиниць в окремих типових групах, або непропорційним.
Типовий відбір дасть більш репрезентативну вибірку. Якщо при простому випадковому відборі забезпечується лише кількісна репрезентація вибірки, то при типовому відборі забезпечується як кількісна, так і якісна репрезентація. Найяскравішими прикладами вибірок, здійснюваних по методу квот, є вибірки з метою вивчення громадської думки.
При дослідженні правових явищ і процесів що відбуваються в суспільстві, а також коли необхідно провести поглиблене вивчення окремих видів злочинів, правопорушень і особливостей осіб, що їх вчинили, доцільно застосовувати серійний, або гніздовий відбір.
Серійний, або гніздовий відбір – це спосіб коли відбираються не окремі одиниці, а їх групи (гнізда, серії), щоб в їх межах спостерігати усі без винятку одиниці сукупності.
В тих випадках, коли одиниці сукупності з’єднані в невеликі групи або серії, використовується серійна вибірка. Як такі серії в кримінально-правовій статистиці можуть розглядатися соціальні або вікові групи – при дослідженні причин злочинності, оперативно-стройові підрозділи правоохоронних органів – при дослідженні ефективності їх роботи тощо. Отже при серійному відборі основою вибірки є певна кількість одиниць, яка розглядається як одне ціле. Враховуючи це, серійний відбір здійснюється з меншими витратами часу на його проведення. Але при цьому способі вибірки завжди існує імовірність отримати більшу похибку репрезентативності.
Окрім перерахованих способів відбору, в практиці статистичних обстежень соціально-правових явищ застосовується і їх комбінація. Так, наприклад, можна комбінувати типову і серійну вибірки, коли серії відбираються в установленому порядку з декількох типових груп. Можлива також комбінація серійного і випадкового відборів, при якій окремі одиниці відбираються всередині серії у випадковому порядку.
Спосіб відбору об’єктів дослідження (одиниць сукупності) – вирішальна умова якості висновків з будь-якого вибіркового методу дослідження, який, у свою чергу, багато в чому визначається особливостями предмету дослідження.
І насамкінець, необхідно нагадати що по ступеню обхвату одиниць досліджуваної сукупності розрізняють великі і малі вибірки. Теорія малих вибірок розроблена англійським статистиком В. Госсетом на початку XX в. і продовжена в дослідженнях Р. Фішера. До малих вивірок відносяться вибірки об’ємом менше 30 одиниць. А як вище зазначалось, для певного способу відбору одиниць помилка репрезентативності залежить від обсягу вибірки і ступеня коливання, неоднорідності ознаки, що вивчається, в генеральній сукупності. Причому чим менше обсяг вибірки, тим більшу помилку репрезентативності слід чекати, а це, у свою чергу знижує точність оцінки параметрів генеральної сукупності. При вибірках невеликого об'єму (менше 100 одиниць) відбір повинен проводитися з сукупності, що має нормальний розподіл, який в об’єктах правової статистики зустрічається дуже рідко. Тому малу вибірку при обстеженні правопорушень і контролю над ними слід застосовувати з великою обережністю при відповідному теоретичному і практичному обґрунтуванні.
Враховуючи вищезазначене, зробимо висновок що використання будь-якого з наведених способів формування вибіркової сукупності залежить від мети вибіркового спостереження, а також можливостей його організації та виділеного часу на його проведення.
Не нашли, что искали? Воспользуйтесь поиском: