ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Q-метод (Q- methodology). Мы видим, что на крайние оценки респондент может расположить ровно
Мы видим, что на крайние оценки респондент может расположить ровно
три карточки, на -4 и +4 — по четыре и т.д. Центр шкалы — наиболее нейтральные высказывания. Здесь можно расположить 16 высказываний.
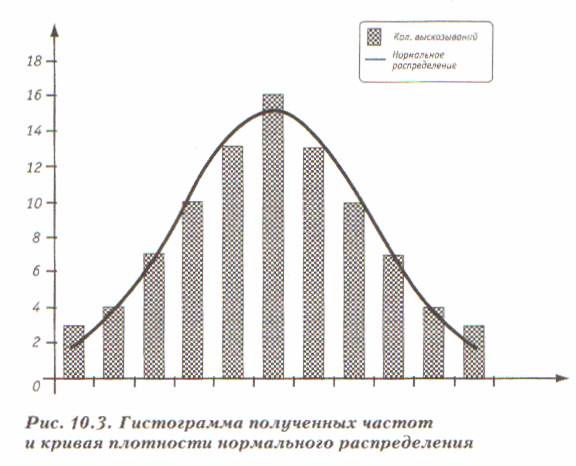
Как выбирается количество высказываний для каждой точки шкалы? Внимательный читатель, наверное, уже обратил внимание на распределение количества высказываний по шкале — симметричное, растущее к центру шкалы и спадающее к краям. А те, кто хотя бы отдаленно знаком с математической статистикой, уже догадался, что где-то уже нечто подобное видел. Авторы не собираются никого мистифицировать — это нормальное распределение. для иллюстрации на рис. 10.3 представлена гистограмма частот и, для сравнения, кривая плотности нормального распределения.
Хорошо, допустим, с этим понятно. Но как вычислить, сколько высказываний необходимо на каждое деление шкалы? В известной нам литературе мы не нашли описания этой процедуры, поэтому позволим себе изложить собственный подход к решению данной проблемы.
Мы исходили из того, что процедура вычислений должна быть достаточно простой и полученное эмпирическое распределение частот должно быть квазинормальным. Было сделано предположение, что в силу конечности шкалы мы не охватываем всю широту мнений, а лишь примерно до 95% генсовокупности. Тогда можно считать, что отклонение нашей шкалы от среднего значения составляет примерно 2 среднеквадратичных (2*σ). для случая шкалы от -5 до +5 и размера Q -выборки из до высказываний мы в силах заставить МS Ехсеl посчитать необходимые частоты по формуле нормального
А. Кутлалиев
А. Попов
распределения со следующими параметрами: (среднее шкалы = 0; σ шкала = 5/2 = 2,5; множитель = 90). Вот как примерно это должно выглядеть в умелых руках (табл. 10.3).

Мы распределили примерно 95% (86/90=0.956) высказываний. По одному добавим на концы шкалы, чтобы учесть «хвосты» распределения и два — в центр. В данном случае мы не претендуем на строго научный подход к вычислению эмпирических частот, но сравнение распределения час приведенных в различных источниках, и нашего алгоритма вычислений казали хорошее совпадение результатов. Значит, ничто не мешает на у- использовать в случае необходимости.
Свободная сортировка, в отличие от принудительной, не ставит жестких ограничений на количество высказываний. Респондент вправе разместить на любой отметке шкалы любое количество высказываний.
Надо сказать, что между исследователями давно идут споры, какой метод лучше. Сторонники принудительной сортировки считают, что такой способ позволяет уменьшить влияние вариативности респондентов. Они справедливо замечают, что часть респондентов избегает крайних оценок, а другая наоборот, более склонна к ним. Более того, ряд респондентов склонен несимметричному размещению высказываний, что смещает шкалу в т или иную сторону. И еще одна немаловажная деталь сильно портит настроение при работе с методом свободной сортировки: он существенно осложняет
Глава 10.
Не нашли, что искали? Воспользуйтесь поиском: