ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Структура процессора P6.
СемействоP6 (Pentium Pro, Celeron, Pentium II, Pentium III)
Суперскалярная обработка на основе техники переупорядочивания (до трех операций за такт). Динамическое исполнение команд (анализ зависимостей по данным, неупорядоченное и спекулятивное исполнение, предсказание ветвления). Интегрированный смешанный кэш второго уровня (до 2 Мб). SSE (128 разрядов)
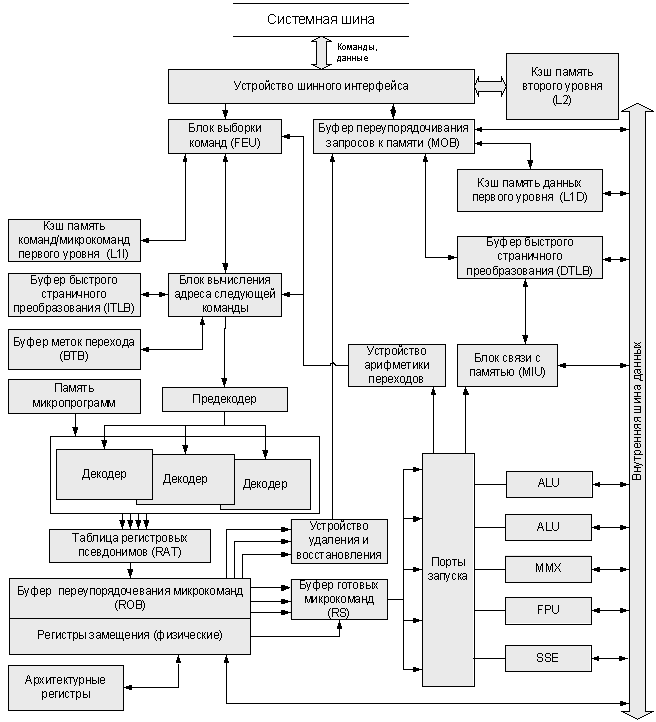
Достоинства P6: Суперскалярная обработка; Интегрированная кэш-память; Сбалансированность фаз конвейера.
Недостатки P6: Длительное декодирование сложных команд; Отсутствие слияния микроопераций загрузки/выгрузки и обработки; Малое количество входов ROB; Наличие медленных команд.
38. Процессор P6: регистры замещения.
Команды из L1I, помимо Блока вычисления адреса следующей команды, поступают в блок декодирования, где выполняется предобразование каждой поступившей инструкции в последовательность микрокоманд. В процессорах P6 реализованы три декодера, первый из которых может обработать любую инструкцию и способен генерировать до четырех микрокоманд за такт, в то время как два других позволяют дешифрировать только простые инструкции, каждая из которых преобразуется в одну микрокоманду. Таким образом, максимальная производительность декодеров в процессорах P6 достигается при компоновке программного кода в блоки по 16 байт, в которых сложная инструкция размещается на первом месте, за которой следуют две простых инструкции. Иное размещение команд замедлит процесс декодирования.
Преобразование машинных инструкций в последовательность микрокоманд, исполнение которых может происходить переупорядочено (т.е. в порядке, отличном от предписанного программой) связано с необходимостью выявления и устранения взаимосвязи команд по данным. Так, если две инструкции программы используют одни и те же ячейки памяти k, возможно четыре типа конфликтов по данным (
Для выявления и устранения конфликтов типа «чтение после записи» и «запись после чтения» применяется механизм переименования, который основан на использовании Регистров замещения. Обязанности программных регистров процессора, указываемых в командах, в каждый момент времени может исполнять любой из регистров замещения. В связи с этим при декодировании очередной инструкции необходимо иметь полную информацию о их текущем назначении. Далее, если в команде предусмотрено сохранение результата, для него выделяется один из свободных регистров замещения, после чего псевдоним выделенного регистра отмечается в специальной таблице: Таблице регистровых псевдонимов. Все последующие команды, использующие полученный результат, должны ожидать его вычисления и сохранения (иными словами: достоверности) во вновь предоставленном регистре замещения, что предусматривает хранение специального бита достоверности для каждого из них. Указанный механизм обеспечивает возможность переупорядоченного исполнения микрокоманд, т.к. разрешает обработку только в том случае, когда все востребованные в микрокоманде операнды достоверны.
39. Процессор P6: взаимодействие блока шинного интерфейса, кэш-памяти и системной шины.
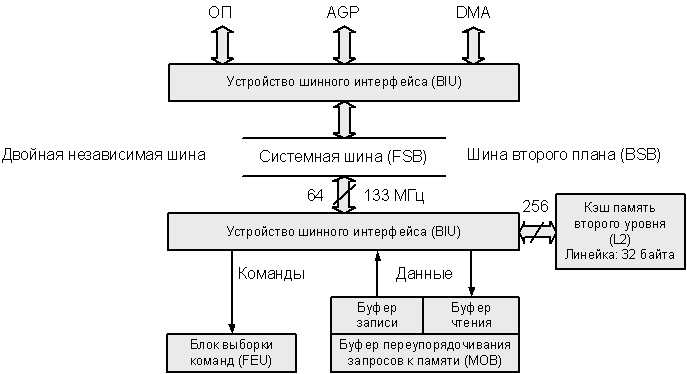
Обращение к ОП выполняется через L2. Разделение системной магистрали на две независимые шины снижает нагрузку на системную магистраль до 10% от максимальной.
Кэш память второго уровня (L2)
Тип: Наборно-ассоциативная неблокируемая
Размер: до 2 Мб; Размер линейки: 32 байта.; Ассоциативность: 4; Политика записи: Write Back;
Алгоритм замещения: LRU; Протокол: MESI
40.Процессор P6: блок вычисления адреса следующей команды. Буфер меток перехода.
Блок вычисления адреса следующей команды реализует механизм статического и динамического предсказания (Алгоритм предсказания зависит от размера строк PHT. При хранении одного бита переход предсказывается в соответствии с предыдущим итогом выполнения команды (точность ~78%). При хранении двух бит учитывается переход для двух последних исполнений команды (точность ~82%). 1. Двухуровневое предсказание.
2. Гибридное предсказание) с использованием наборно-ассоц. Буфера меток перехода BTB (Branch Target Buffer). BTB в P6 состоит из 512 элементов (4-х ассоциативный).

41. Процессор P6: устройство выборки команд и TLB команд.
СемействоP6 (Pentium Pro, Celeron, Pentium II, Pentium III) - Суперскалярная обработка на основе техники переупорядочивания (до трех операций за такт). Динамическое исполнение команд (анализ зависимостей по данным, неупорядоченное и спекулятивное исполнение, предсказание ветвления). Интегрированный смешанный кэш второго уровня (до 2 Мб). SSE (128 разрядов).
Три основные концепции:
- предсказание переходов на основе btb: после уточнения правильности перехода конвейер может быть сброшен.
- анализ потока данных: устранение зависимостей по данным и аппаратная предвыборка: отмена транзакций.
- неупорядоченное исполнение команд: промежуточные данные находятся во временных регистрах замещения.
Блок выборки команд получает физический адрес очередной команды из Блока вычисления адреса следующей команды. По этому адресу сначала происходит обращение в L1I. Если указанного блока команд (линейки) там нет, то запрос передается в BIU.

Для преобразования логического адреса в физический используется ITLB (Instruction Translation Lookaside Buffer) и DTLB (Data Translation Lookaside Buffer). Информация, записываемая в TLB, не подлежит кэшированию. При доступе к данным или командам по адресу, для преобразования которого информация в TLB отсутствует, необходимо обратиться в оперативную память дважды: сначала за информацией из таблицы страниц, и после преобразования за самими данными или командами.

42. Процессор P6: буфер переупорядоченных команд и буфер команд, готовых к выполнению.
СемействоP6 (Pentium Pro, Celeron, Pentium II, Pentium III) - Суперскалярная обработка на основе техники переупорядочивания (до трех операций за такт). Динамическое исполнение команд (анализ зависимостей по данным, неупорядоченное и спекулятивное исполнение, предсказание ветвления). Интегрированный смешанный кэш второго уровня (до 2 Мб). SSE (128 разрядов).
Три основные концепции:
- предсказание переходов на основе btb: после уточнения правильности перехода конвейер может быть сброшен.
- анализ потока данных: устранение зависимостей по данным и аппаратная предвыборка: отмена транзакций.
- неупорядоченное исполнение команд: промежуточные данные находятся во временных регистрах замещения.
Не нашли, что искали? Воспользуйтесь поиском: