ТОР 5 статей:
Методические подходы к анализу финансового состояния предприятия
Проблема периодизации русской литературы ХХ века. Краткая характеристика второй половины ХХ века
Характеристика шлифовальных кругов и ее маркировка
Служебные части речи. Предлог. Союз. Частицы
КАТЕГОРИИ:
- Археология
- Архитектура
- Астрономия
- Аудит
- Биология
- Ботаника
- Бухгалтерский учёт
- Войное дело
- Генетика
- География
- Геология
- Дизайн
- Искусство
- История
- Кино
- Кулинария
- Культура
- Литература
- Математика
- Медицина
- Металлургия
- Мифология
- Музыка
- Психология
- Религия
- Спорт
- Строительство
- Техника
- Транспорт
- Туризм
- Усадьба
- Физика
- Фотография
- Химия
- Экология
- Электричество
- Электроника
- Энергетика
Буфер переупорядочивания микрокоманд
-Микрооперации помещаются в ROB в исходном порядке.
-Исполнение МОП происходит неупорядочено по мере готовности операндов.
-Удаление (отставка) МОП происходит упорядочено из-за: прерываний, исключений, точек останова, неправильно предсказанных переходов.
Микрокоманды в ROB могут находиться в одном из следующих состояний:
1. Не готова к исполнению;
2. Готова к исполнению;
3. Исполняется;
4. Исполнена и ожидает отставки;
5. Находится в процессе отставки. 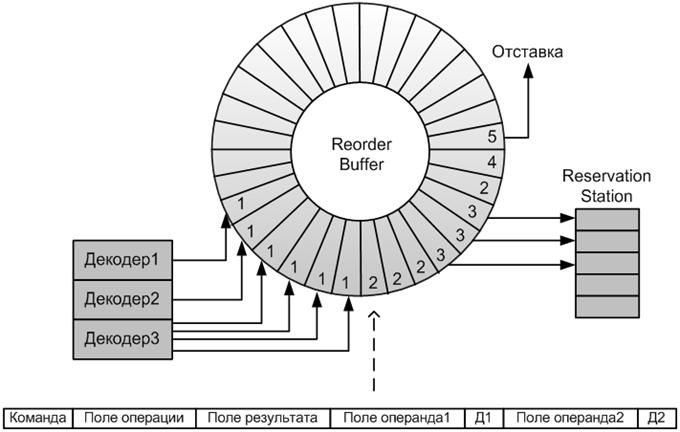
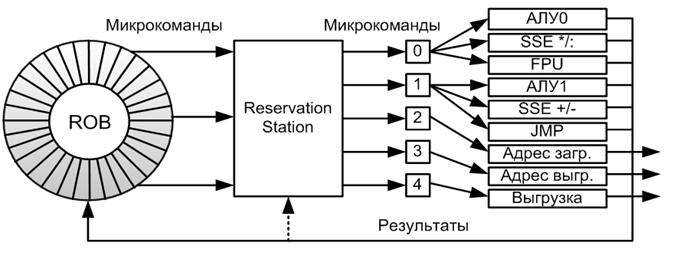
В процессорах P6 пять портов запуска.
В RS (буфер команд готовых к выполнению) в каждом такте могут быть помещены три микрооперации из ROB и пять микроопераций могут быть направлены в порты запуска. Если претендентов на исполнительное устройство несколько, то выбор производится по алгоритму «псевдо-FIFO».
43. Процессор P6: буфер переупорядочивания запросов к памяти. Аппаратная и программная предвыборка.
СемействоP6 (Pentium Pro, Celeron, Pentium II, Pentium III) - Суперскалярная обработка на основе техники переупорядочивания (до трех операций за такт). Динамическое исполнение команд (анализ зависимостей по данным, неупорядоченное и спекулятивное исполнение, предсказание ветвления). Интегрированный смешанный кэш второго уровня (до 2 Мб). SSE (128 разрядов).
Три основные концепции:
- предсказание переходов на основе btb: после уточнения правильности перехода конвейер может быть сброшен.
- анализ потока данных: устранение зависимостей по данным и аппаратная предвыборка: отмена транзакций.
- неупорядоченное исполнение команд: промежуточные данные находятся во временных регистрах замещения.
При необходимости чтения или записи ОП в команде генерируется микрооперация чтения/записи (load/store). Такие микрооперации также хранятся в ROB. Если адреса известны, то такие микрооперации напрляются в блок связи с памятью (MIU). MIU обрабатывается в DTLB, преобразовав логические адреса в физические, выполняется поиск данных в L1D. Если данных нет, то микрооперация чтения/записи передается в буфер переупорядочивания запросов к памяти. Буферы записи хранят запросы store, буферы чтения – load. Микрооперация store выполняется только при отставке команды.
Выгрузка в память (store) происходит в соответствии с порядком отставки (в исходном порядке). Только после отставки возможно незначительное переупорядочивание для оптимизации работы BIU.
Загрузка (load) может происходить неупорядоченно в случае отсутствия зависимостей по данным.
Для ускорения выполнения микроопераций загрузки выполняется поиск требуемых данных в микрооперациях выгрузки (forwarding of data from stores to dependent loads).
Однако возможны приложения, в которых процессор не может обнаружить зависимость по данным (I/O operations).
Команды управления загрузкой-выгрузкой:
Не нашли, что искали? Воспользуйтесь поиском: